HBase入门基础:列式存储与特性解析
需积分: 9 76 浏览量
更新于2024-07-17
收藏 1.85MB DOCX 举报
"这是一份关于HBase入门的学习笔记,适合初学者了解HBase的基础知识。文档可能不适用于已经深入理解HBase的读者。"
在IT领域,数据库是数据管理和存储的核心,而HBase作为一种非关系型数据库(NoSQL),在处理高并发读写、海量数据高效读写以及提供高扩展性和可用性方面表现出色,特别适用于大数据场景。关系型数据库如MySQL、Oracle和SQL Server,虽然在事务一致性、复杂的SQL查询等方面有优势,但在面对大规模并发和大数据量时,可能会遇到性能瓶颈。
非关系型数据库,尤其是像HBase这样的列式数据库,因其速度和存储能力的优势而受到青睐。HBase起源于Google的BigTable论文,是一种分布式、多版本、基于列族的键值存储系统,通常与Hadoop生态系统紧密集成。它在处理实时读写、大规模数据存储和分布式操作上有着独特的优势。
HBase的基本概念包括:
1. 表(Table):数据的主要组织形式,由行(Row)和列族(Column Family)组成。
2. 行(Row):通过行键(Row Key)唯一标识,数据按行键字典序排序。
3. 列族(Column Family):数据的逻辑分组,每个列族可以包含多个列(Column)。
4. 列(Column):由列族和列限定符(Qualifier)组成,列限定符用于区分同一列族内的不同列。
5. 单元格(Cell):由行键、列族、列限定符和时间戳定义,存储实际的数据。
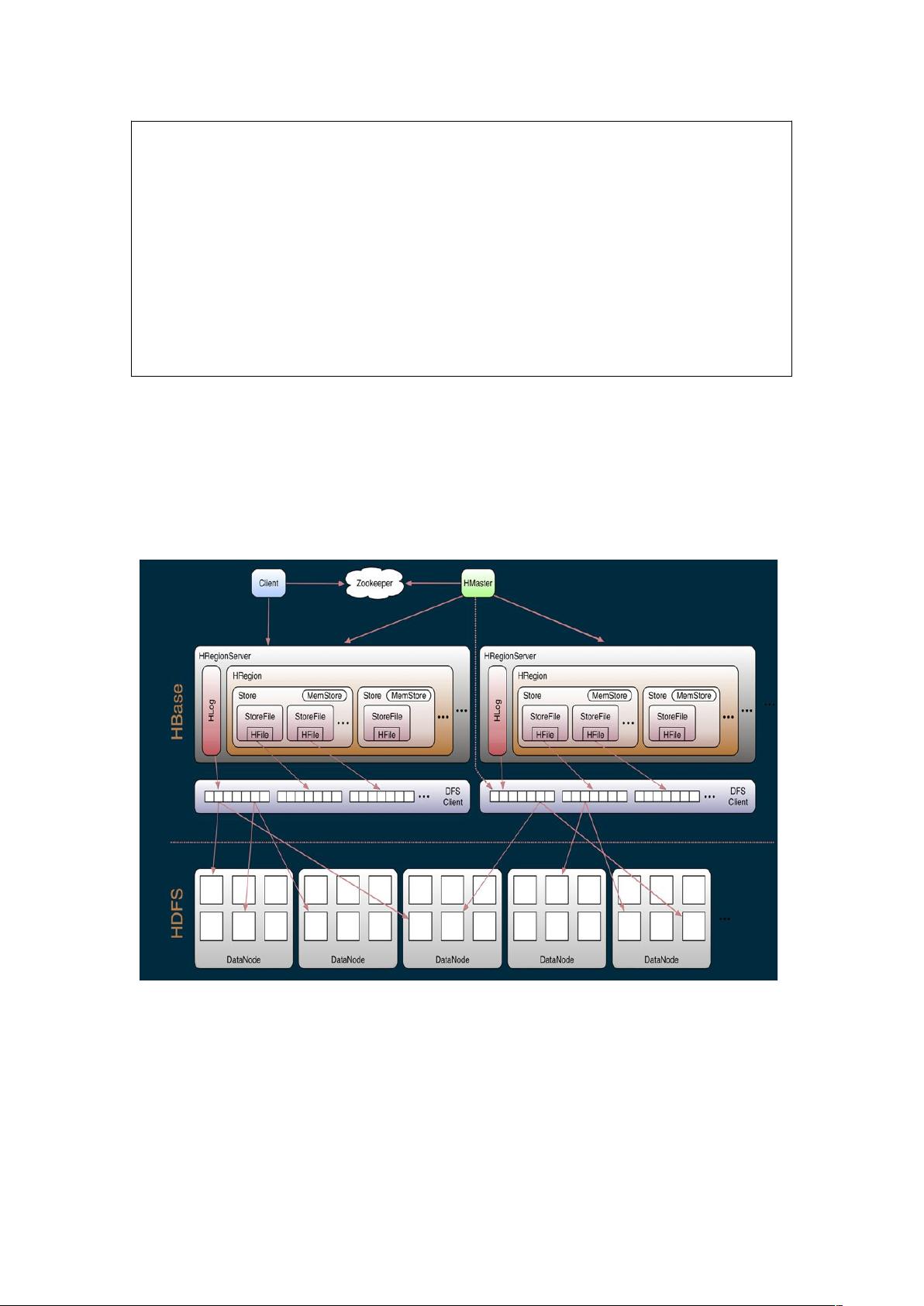
HBase的架构主要包括:
1. RegionServer:数据存储和处理的实体,负责管理一个或多个Region。
2. HMaster:主要负责Region的分配、RegionServer的监控和故障恢复,以及表的创建、删除等元数据操作。
HBase的物理模型中,Table被划分为多个Region,每个Region负责一部分数据的读写。Region的大小随着数据增长而动态调整,当Region达到预设阈值时,会被拆分成两个新的Region。RegionServer负责Region的生命周期管理,包括拆分、合并和迁移。
Region的寻址过程在早期版本中涉及ZooKeeper(ZK):
1. 客户端首先向ZK查询-ROOT-表的RegionServer地址。
2. 然后,客户端通过-ROOT-表找到.META.表的位置,并缓存相关信息以加快后续访问。
3. 最后,客户端依据.META.表获取所需数据所在的RegionServer。
HBase还提供了丰富的命令行工具和API,允许用户进行表的操作、数据的增删改查等。此外,HBase支持数据的版本控制和时间戳,确保数据的历史记录可追溯。其灵活的架构和强大的数据处理能力,使其成为大数据环境下的理想选择,特别是在互联网、物联网、日志分析等领域。
444444444444444444444444444444444444444444444444444444444444444444
1!1>显示
$!1!11;<0;;11+1
1!1?B6.B.C851;<0;;1@
1!1?B6.B.C851;<0;;1BD.C851;<0;;1@
444444444444444444444444444444444444444444444444444444444444444444
!1!11;<0;;11+1>删除
'!1!1>记录
HBase 架构
.$ 是存储 /( 的数据的单位
/!进行负载均衡的功能决定 $ 放在哪里
剩余17页未读,继续阅读
156 浏览量
938 浏览量
151 浏览量
2020-02-24 上传
5458 浏览量
283 浏览量
2024-03-12 上传
128 浏览量

Oasen
- 粉丝: 49
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- 大酒店员工手册
- xoak-feedstock:一个xoak的conda-smithy仓库
- 文件夹
- 易语言源码易语言使用脚本开关系统还原源码.rar
- SleepDisplay:命令行工具可让您的Mac显示器直接进入睡眠状态
- Papara Excel İşlem Özeti-crx插件
- python程序设计(基于网络爬虫的电影评论爬取和分析系统)
- OlaMundo:Primeiro存储库
- 零售业管理:价格策略
- 投资组合
- java笔试题算法-Complete-Striped-Smith-Waterman-Library:Complete-Striped-Smit
- ros_arm_control.7z
- tripitaka:Tripitaka的依赖性很低,没有针对Node.js的简洁记录器
- 以品类管理为导向的连锁企业管理功能重组
- 长颈鹿
- 三菱Q系列PLC选型工具软件.zip
