Python爬虫基础教程:从入门到正则与Scrapy框架
需积分: 9 28 浏览量
更新于2024-07-19
收藏 8.2MB PDF 举报
"Python爬虫入门,讲解Python爬虫框架、正则表达式和Scrapy入门"
在Python编程领域,网络爬虫是一项重要的技术,用于自动提取大量数据自互联网。Python因其简洁的语法和丰富的库支持,成为开发爬虫的理想选择。本教程主要面向初学者,旨在引导你进入Python爬虫的世界。
一、网络爬虫简介
网络爬虫,也称为Web Spider,通过跟踪网页间的链接,遍历互联网上的页面。它们从一个或几个初始网页开始,读取页面内容,识别其中的链接,然后访问这些链接指向的新页面,如此反复,实现对网站数据的抓取。在大规模的数据挖掘和分析中,网络爬虫起到了关键作用。
二、浏览网页的原理
当你在浏览器中输入URL(例如www.baidu.com)时,实际上是在向服务器发送一个请求,请求获取该URL对应的资源。服务器响应后,将HTML代码发送回浏览器。浏览器负责解析HTML代码,并根据其中的标签和样式信息渲染出可视化的网页。
三、HTML与网页解析
HTML(HyperText Markup Language)是构成网页的基础,它使用一系列标签来定义页面结构和内容。浏览器接收HTML代码后,会解析这些标签,将文本、图像等元素按照指定的方式展示出来。
四、URI与URL
URI(Universal Resource Identifier)是互联网资源的唯一标识,包括访问资源的机制、主机名和资源本身的路径。而URL(Uniform Resource Locator)是URI的一个特例,专指可以定位资源的特定地址,通常包含协议类型(如http或https)、主机名和路径。
五、Python爬虫框架
Python有许多用于爬虫开发的框架,如BeautifulSoup、Requests、Selenium等。对于初学者,BeautifulSoup库易于学习,能解析HTML和XML文档,便于提取所需数据。Requests库则用于发送HTTP请求,获取网页内容。
六、正则表达式
在爬虫中,正则表达式(Regex)常用来匹配和提取网页中的特定模式。通过定义规则,你可以从HTML源码中筛选出需要的信息,如电话号码、电子邮件地址等。
七、Scrapy框架
Scrapy是一个高级的Python爬虫框架,提供了完整的爬虫项目结构和中间件支持,方便处理数据下载、解析、存储等任务。Scrapy适用于大型、复杂的爬虫项目,具有高效和可扩展的特性。
总结:
Python爬虫入门需要理解网络爬虫的工作原理,掌握HTML解析和URI/URL的含义。在实际操作中,利用Python的requests库获取网页内容,BeautifulSoup库解析HTML,正则表达式进行数据匹配,更进阶时可以学习Scrapy框架来构建更强大的爬虫系统。通过不断实践和学习,你将能够熟练运用Python爬虫技术,从海量互联网数据中获取有价值的信息。

16
以下为个人学习笔记。
在开始后面的内容之前,先来解释一下 urllib2 中的两个个方法: info
and geturl
urlopen 返回的应答对象 response( 或者 HTTPError 实例 )有两个很有
用的方法 info() 和 geturl()
1.geturl() :
这个返回获取的真实的 URL,这个很有用, 因为 urlopen( 或者 opener
对象使用的 )或许会有重定向。获取的 URL 或许跟请求 URL 不同。
以人人中的一个超级链接为例 ,
我们建一个 urllib2_test10.py 来比较一下原始 URL 和重定向的链接
:
[python] view plaincopy
1. from urllib2 import Request, urlopen, URLError, HTTPError
2.
3.
4. old_url = 'http://rrurl.cn/b1UZuP'
5. req = Request(old_url)
6. response = urlopen(req)
7. print 'Old url :' + old_url
8. print 'Real url :' + response.geturl()
运行之后可以看到真正的链接指向的网址:
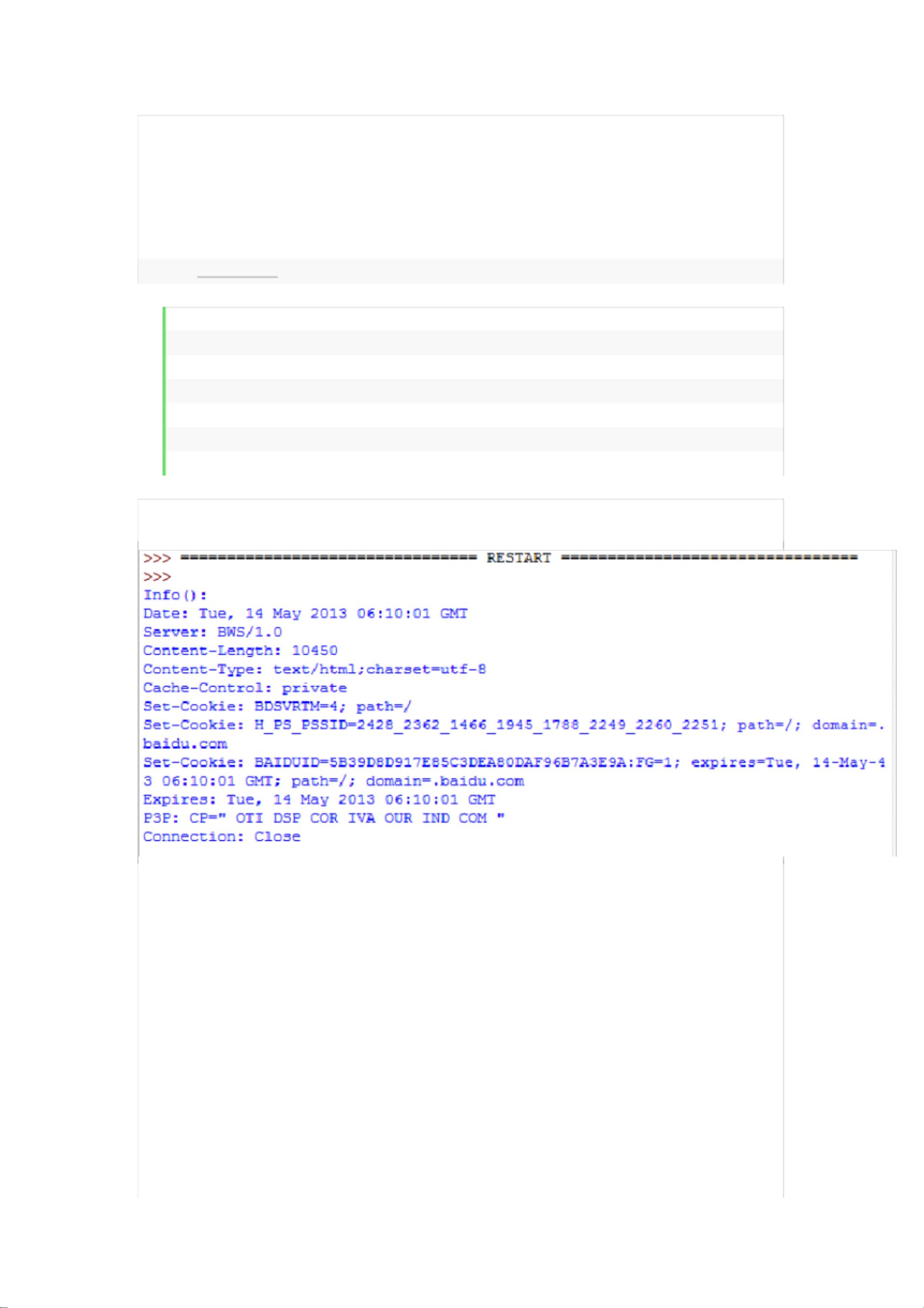
2.info() :
这个返回对象的字典对象,该字典描述了获取的页面情况。 通常是服务
器发送的特定头 headers 。目前是 httplib.HTTPMessage 实例。



剩余110页未读,继续阅读
433 浏览量
239 浏览量
147 浏览量
2024-11-30 上传
1618 浏览量
213 浏览量

Andy155155
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hibernate3.3.1参考文档:Java关系型持久化标准
- CMMI与敏捷开发:互补的流程创新
- Spring与Struts整合:XML配置详解
- C++编程规范详解:经典书籍推荐与实践指南
- 2.0版EA评估框架:四大能力区域详解与评分标准
- Mainframe面试必备:COBOL问题与解答
- datagrid商品小计与总价计算方法
- 探索Java反射机制:动态获取与调用
- 精通C++:Scott Meyers的More Effective C++解析
- UNIX系统详解:历史、构成与基础操作
- Ibatis 1.2.9开发指南详解:入门与配置
- C++编程思想:进阶与标准库解析
- Flex事件详解:新手入门与高级机制
- C++与面向对象编程入门指南
- MySQL Cluster评估指南:关键点与决策支持
- 单片机新手入门常见问题与解决方案
