Python实战:心脏病数据集分析探索
版权申诉
"该文档是关于使用Python进行心脏病数据集分析的数据分析实战教程。文档首先介绍了导入所需的Python库,如numpy、pandas、matplotlib和seaborn,然后展示了数据集的基本结构和各列的含义,包括年龄、性别、胸痛类型、血压、胆固醇等与心脏病相关的指标。数据集中没有包含生活习惯如抽烟、熬夜的信息。接着,文档提到了初步的数据探索,如男女比例和患病比率的分析。"
在这篇文档中,作者通过Python进行了一次实际的数据分析项目,使用的数据集是关于心脏病患者的一项研究。首先,他们引入了常用的Python数据分析库,包括numpy用于数值计算,pandas用于数据处理和分析,matplotlib和seaborn则用于数据可视化。这些工具是进行任何数据科学项目的基础,能帮助我们清洗、处理和理解数据。
数据集包含了303个样本,每个样本有14个特征。这些特征包括病人的年龄(age)、性别(sex)、胸痛类型(cp)、静息血压(trestbps)、胆固醇水平(chol)、空腹血糖(fbs)、静息心电图(restecg)结果、最大心率(thalach)、运动引发的心绞痛(exang)、ST段下降程度(oldpeak)、最高运动ST段斜率(slope)、次要血管数量(ca)以及thal特征,这是一个与地中海贫血相关的指标。最后,target列表示病人是否患有心脏病(0表示没有,1表示有)。
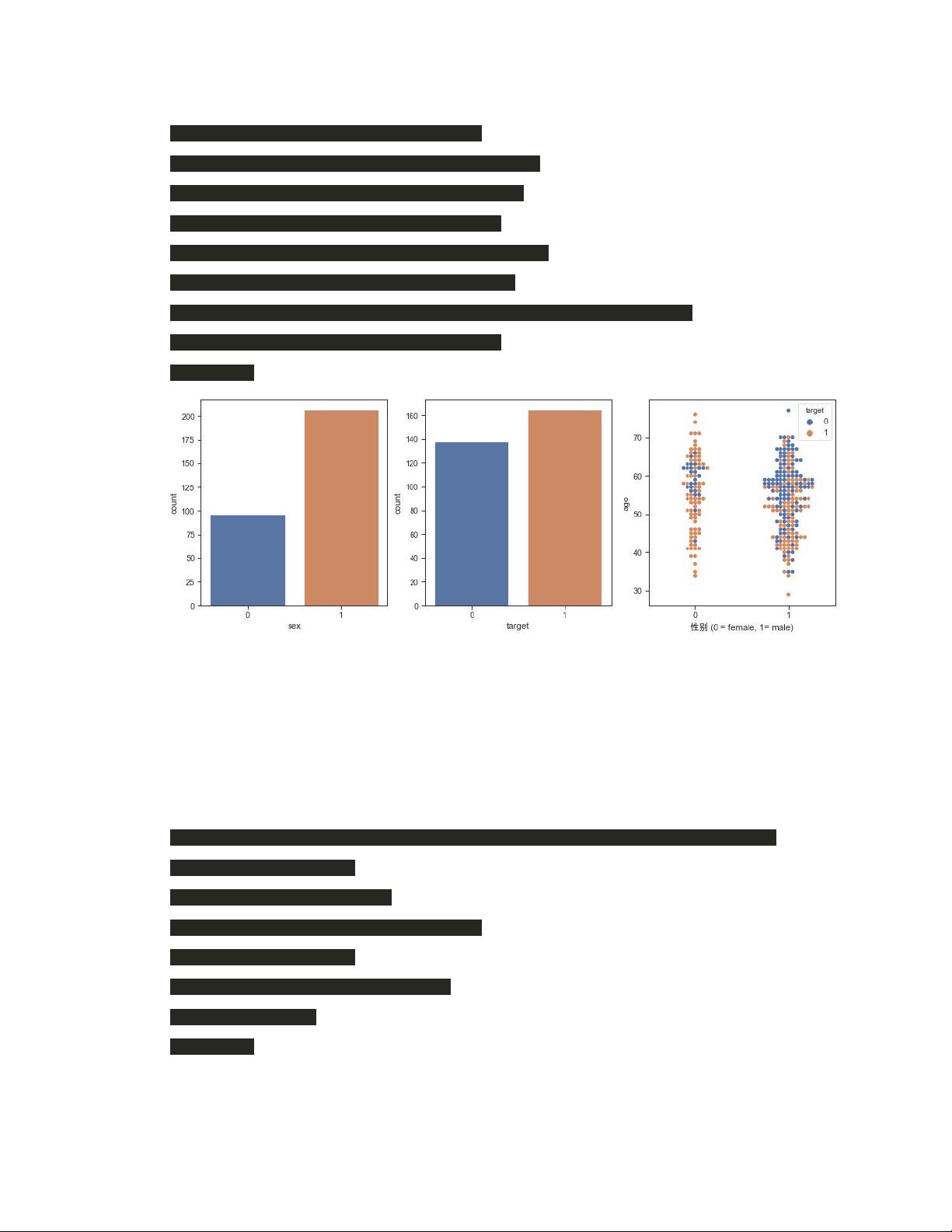
在分析过程中,作者关注了数据的性别分布和患病情况,通过计算不患病(countNoDisease)和患病(countHaveDisease)人数,以及男性(countmale)和女性(countfemale)数量,来了解数据集中的基本比例。这样的初步探索有助于理解数据的总体特征,为进一步的统计测试和模型建立打下基础。
虽然这个数据集没有包含生活方式因素,如吸烟、熬夜等,但这样的分析仍然是有价值的,因为可以研究不同生理指标与心脏病之间的关系。例如,通过关联分析可以找出哪些特征与心脏病的发生有显著关联,这对于医学研究和临床决策都具有重要意义。
这篇文档提供了一个使用Python进行医疗数据分析的实例,演示了如何利用编程工具探索和理解复杂的数据集,以及如何从中提取有价值的信息。对于学习数据分析,特别是医疗数据分析的人来说,是一个很好的实践案例。
fig, ax =plt.subplots(1,3) #2 个子区域
fig.set_size_inches(w=15,h=5) # 设置画布大小
sns.countplot(x="sex", data=data,ax=ax[0])
plt.xlabel("性别 (0 = female, 1= male)")
sns.countplot(x="target", data=data,ax=ax[1])
plt.xlabel("能否患病 (0 = 未患病, 1= 患病)")
sns.swarmplot(x='sex',y='age',hue='target',data=data,ax=ax[2])
plt.xlabel("性别 (0 = female, 1= male)")
plt.show()
从这三联图可以看到男性 多余女性 ,患病 多于未患病 ,在年
龄分布提琴图里可以看到女性患者比例多于男性患者比例。
其中比列具体拆解一下,见下方代码和图示:
pd.crosstab(data.sex,data.target).plot(kind="bar",figsize=(15,6),color=[
'#30A9DE','#EFDC05' ])
plt.title('各性别下患病图示')
plt.xlabel('性别 (0 = 女性, 1 = 男性)')
plt.xticks(rotation=0)
plt.legend(["未患病", "患有心脏病"])
plt.ylabel('人数')
plt.show()
剩余15页未读,继续阅读
2024-09-05 上传
2024-09-05 上传
2022-06-14 上传
2023-07-20 上传
2023-10-25 上传
2024-10-28 上传
2023-06-10 上传
2023-12-01 上传
2023-05-04 上传

bingbingbingduan
- 粉丝: 0
- 资源: 7万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
