Spring Boot + Redis+Caffeine:两级缓存实战教程
版权申诉
本文将深入探讨如何在Spring Boot应用中利用Spring Cache实现两级缓存,结合Redis和Caffeine这两种流行的缓存技术。Spring Boot本身集成了一系列缓存选项,包括Redis、Caffeine、JCache和EhCache等,但单一使用可能带来网络消耗或内存占用问题。因此,采用两级缓存策略可以显著提升应用性能。
首先,我们来理解什么是缓存和两级缓存。缓存是一种将常用数据存储在更快访问介质(如内存)的技术,以减少对底层数据源(如数据库)的频繁访问。例如,通过Redis进行内存缓存可以大大提高读取速度,但可能会有网络延迟。而Caffeine作为应用内的缓存,可以作为第一级缓存,减少对Redis的依赖。
Spring Cache提供了一种注解驱动的方式来管理缓存,简化了缓存操作的添加和管理。然而,直接在业务代码中处理缓存可能导致代码冗余和理解困难。使用Spring Cache,我们可以创建自定义缓存配置,比如定义哪些数据应该被缓存、缓存的生存期等。
在Spring Boot+Spring Cache中,Redis通常用于实现第二级缓存,它提供了分布式、高可用的数据存储,适合大量数据和跨节点共享。但RedisCache在Spring Cache中的实现可能存在一些局限,如复杂的配置和对Redis客户端的依赖。
Caffeine作为第一级缓存,其内存占用相对较小,且支持更灵活的缓存策略,如LRU(最近最少使用)淘汰策略。在Spring Boot中集成Caffeine,可以通过Spring Data Caching库或者直接使用Caffeine的Java API来实现。
实现两级缓存(Redis+Caffeine)的关键在于整合Spring Cache的`@Caching`注解与RedisTemplate或Caffeine缓存,以及配置适当的缓存策略。首先,设置Spring Cache的Redis配置,然后在需要使用缓存的方法上添加`@Caching`注解,指定数据应该先从Caffeine中查找,如果没有再查询Redis。当数据从Redis返回后,可以根据需要同步回Caffeine。
通过这种方式,我们可以在保持代码简洁的同时,优化数据访问性能,降低网络开销,提高应用响应速度。同时,这样的设计也有利于代码的维护和扩展,使得业务逻辑更加清晰,提高了整体的系统效能。
spring boot+spring cache实现两级缓存实现两级缓存(redis+caffeine)
主要介绍了spring boot+spring cache实现两级缓存(redis+caffeine),小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
spring boot中集成了spring cache,并有多种缓存方式的实现,如:Redis、Caffeine、JCache、EhCache等等。但如果只用一种缓存,要么会有较大的网络消耗(如Redis),要么就是内
存占用太大(如Caffeine这种应用内存缓存)。在很多场景下,可以结合起来实现一、二级缓存的方式,能够很大程度提高应用的处理效率。
内容说明:内容说明:
1. 缓存、两级缓存
2. spring cache:主要包含spring cache定义的接口方法说明和注解中的属性说明
3. spring boot + spring cache:RedisCache实现中的缺陷
4. caffeine简介
5. spring boot + spring cache 实现两级缓存(redis + caffeine)
缓存、两级缓存缓存、两级缓存
简单的理解,缓存就是将数据从读取较慢的介质上读取出来放到读取较快的介质上,如磁盘-->内存。平时我们会将数据存储到磁盘上,如:数据库。如果每次都从数据库里去读取,会因为
磁盘本身的IO影响读取速度,所以就有了像redis这种的内存缓存。可以将数据读取出来放到内存里,这样当需要获取数据时,就能够直接从内存中拿到数据返回,能够很大程度的提高速
度。但是一般redis是单独部署成集群,所以会有网络IO上的消耗,虽然与redis集群的链接已经有连接池这种工具,但是数据传输上也还是会有一定消耗。所以就有了应用内缓存,如:
caffeine。当应用内缓存有符合条件的数据时,就可以直接使用,而不用通过网络到redis中去获取,这样就形成了两级缓存。应用内缓存叫做一级缓存,远程缓存(如redis)叫做二级缓存
spring cache
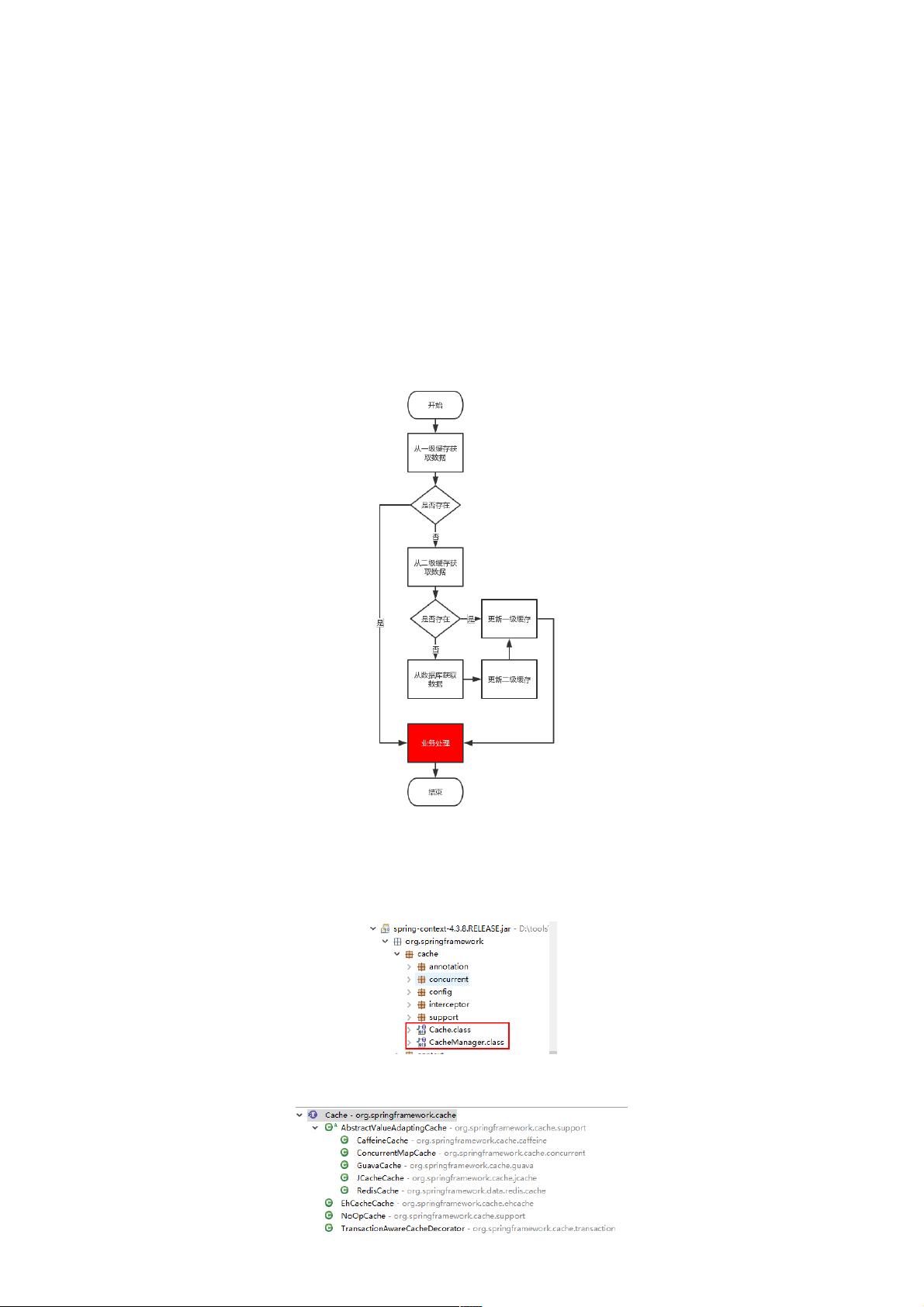
当使用缓存的时候,一般是如下的流程:
从流程图中可以看出,为了使用缓存,在原有业务处理的基础上,增加了很多对于缓存的操作,如果将这些耦合到业务代码当中,开发起来就有很多重复性的工作,并且不太利于根据代码
去理解业务。
spring cache是spring-context包中提供的基于注解方式使用的缓存组件,定义了一些标准接口,通过实现这些接口,就可以通过在方法上增加注解来实现缓存。这样就能够避免缓存代码与
业务处理耦合在一起的问题。spring cache的实现是使用spring aop中对方法切面(MethodInterceptor)封装的扩展,当然spring aop也是基于Aspect来实现的。
spring cache核心的接口就两个:Cache和CacheManager
Cache接口接口
提供缓存的具体操作,比如缓存的放入、读取、清理,spring框架中默认提供的实现有:
除了RedisCache是在spring-data-redis包中,其他的基本都是在spring-context-support包中
下载后可阅读完整内容,剩余9页未读,立即下载
2021-05-17 上传
2024-04-11 上传
2024-02-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38504687
- 粉丝: 6
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
