成对数据统计分析:相关性与一元线性回归
28 浏览量
更新于2024-06-28
收藏 1.28MB PPTX 举报
"第八章成对数据的统计分析章末复习课公开课.pptx"
本节复习内容聚焦于成对数据的统计分析,主要涵盖两个关键知识点:变量的相关性和一元线性回归模型及其应用。
一、变量的相关性
1. 相关关系与样本相关系数:在统计学中,相关关系指的是两个或多个变量之间存在某种趋势或关联,但并不意味着因果关系。样本相关系数(通常表示为'r')是用来量化这种关系的度量,取值范围在-1到1之间。1表示完全正相关,-1表示完全负相关,0表示没有线性相关。
2. 散点图与公式法:通过散点图可以直观地判断变量间是否存在相关性,而样本相关系数的计算则提供了更精确的度量。例如,当所有数据点都位于一条直线上时,r的绝对值为1,表示线性关系非常强。
例题解析展示了如何判断两个变量是否具有相关关系以及相关系数的计算。比如,庄稼的产量与施肥量可能存在正相关,而人的身高与视力通常没有明显的相关性。
二、一元线性回归模型及其应用
1. 一元线性回归:当两个变量之间呈现线性关系时,可以通过一元线性回归模型来描述这种关系,模型通常表示为y = a + bx + ε,其中y是因变量,x是自变量,a是截距,b是斜率,ε是误差项。
2. 回归分析的应用:一元线性回归模型可以用于预测和解释。例如,通过已知的x值预测y值,或者理解x变化对y的影响程度。在选择模型时,需要注意相关系数的大小,大的相关系数意味着模型的拟合效果更好。
跟踪训练进一步巩固了这些概念,例如,如果变量y与z正相关,那么与y负相关的x也会与z负相关,因为相关性会传递。同时,通过比较两组样本数据的相关系数大小,可以评估它们之间的线性关系的紧密程度。
总结,第八章的复习内容强调了统计分析中成对数据的相关性分析和一元线性回归模型的使用。理解和掌握这些知识对于进行数据分析、预测建模以及科学决策至关重要。在实际应用中,应结合直观的散点图和精确的计算来评估变量间的关系,并利用一元线性回归模型对数据进行建模和预测。
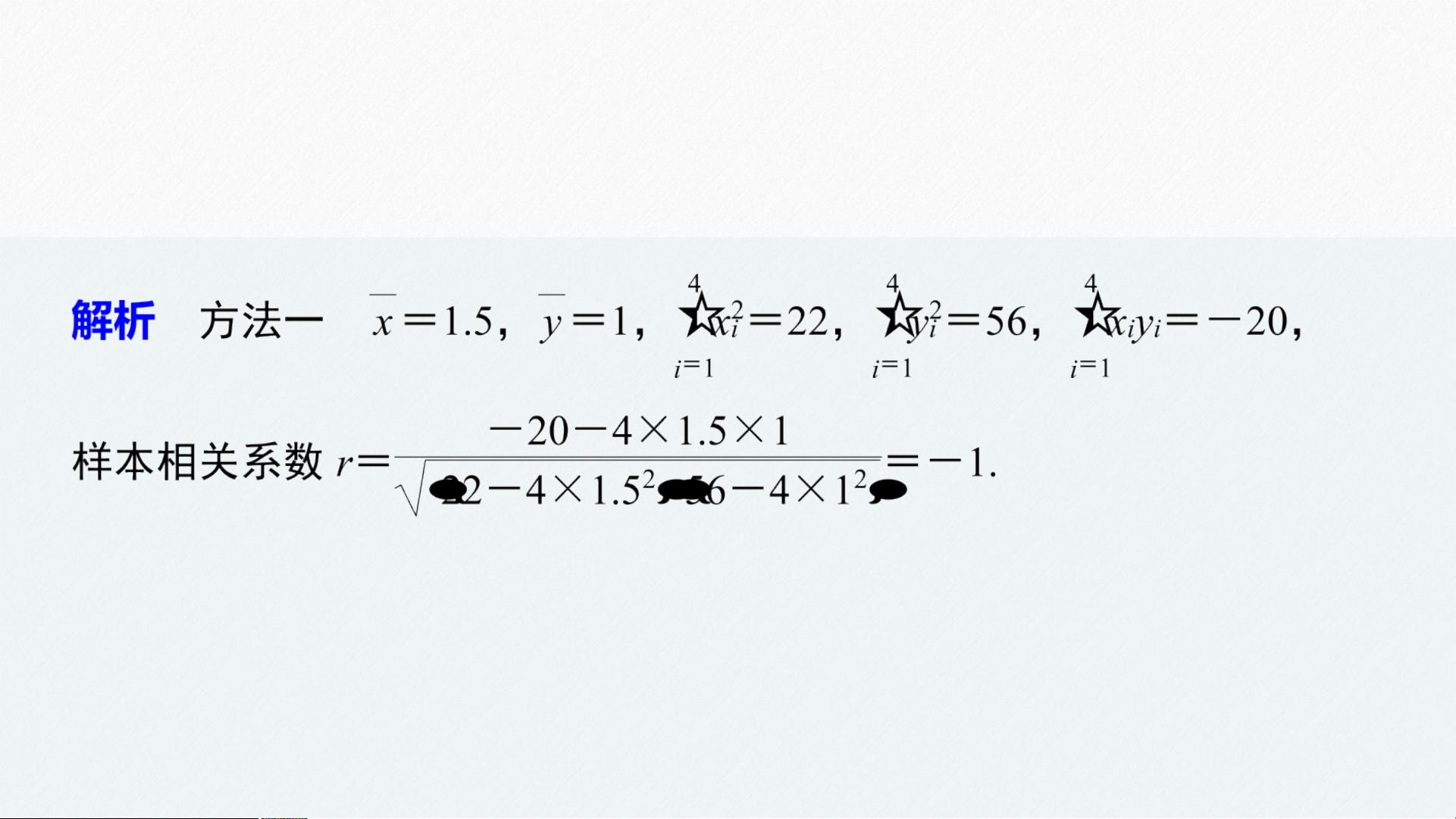
(2)在一次试验中,测得(x,y)的四组值分别为(1,2),(2,0),(4,-4),(
-1,6),则y与x的样本相关系数为_____.
-1
方法二 观察四个点,发现其在一条单调递减的直线上,
故y与x的样本相关系数为-1.

剩余36页未读,继续阅读
2022-12-24 上传
2021-10-12 上传

xinkai1688
- 粉丝: 370
- 资源: 8万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
