混合多特征参数提升语音识别精度与鲁棒性的研究
版权申诉
82 浏览量
更新于2024-07-02
收藏 3.65MB PDF 举报
本文档深入探讨了"人工智能-语音识别-基于多特征参数混合语音识别系统研究与实现"这一主题,随着科技的飞速发展,语音识别技术在各个领域得到了广泛应用。作者在对前人研究成果进行分析和总结的基础上,提出了混合多特征参数的创新研究思路,旨在解决当前识别率和鲁棒性方面存在的问题。
首先,论文概述了语音识别技术的现状,详细解析了识别模型构成的识别系统结构及其工作原理,并对比了常用语音识别算法的优势和不足。通过数学推导和实验模拟,展示了不同算法的具体应用方法,这对于理解现有技术的局限性和改进方向具有重要意义。
其次,文章的重点聚焦于时域和频域特征参数提取算法的研究以及混合方法中的参数优化。时域和频域作为语音信号分析的两大基础,论文深入剖析了这两种特征提取方法的特点,包括Mel频率倒谱系数(MFCC)等经典算法的实现过程。作者探讨了如何结合时域的即时性与频域的稳定性,优化参数设置,以提高识别系统的性能和适应性。
此外,论文还可能涉及深度学习技术在特征提取中的应用,如卷积神经网络(CNN)或循环神经网络(RNN),以及长短时记忆(LSTM)等在处理序列数据方面的优势,这些都是提高语音识别准确度的关键因素。混合方法可能涉及到声学模型、语言模型和上下文信息的融合,以增强模型对噪声和变声的鲁棒性。
通过理论分析和实验验证,作者期望提出一种高效、鲁棒的混合多特征参数语音识别系统,能够在实际应用场景中展现出更好的性能。这不仅对提升语音识别技术的实用价值有积极影响,也为相关领域的进一步研究和发展提供了新的思路和实践指导。这篇论文是一篇深入挖掘语音识别技术潜力,推动技术创新的重要文献。
基于多特征参数混合语音识别系统研究与实现
- 8 -
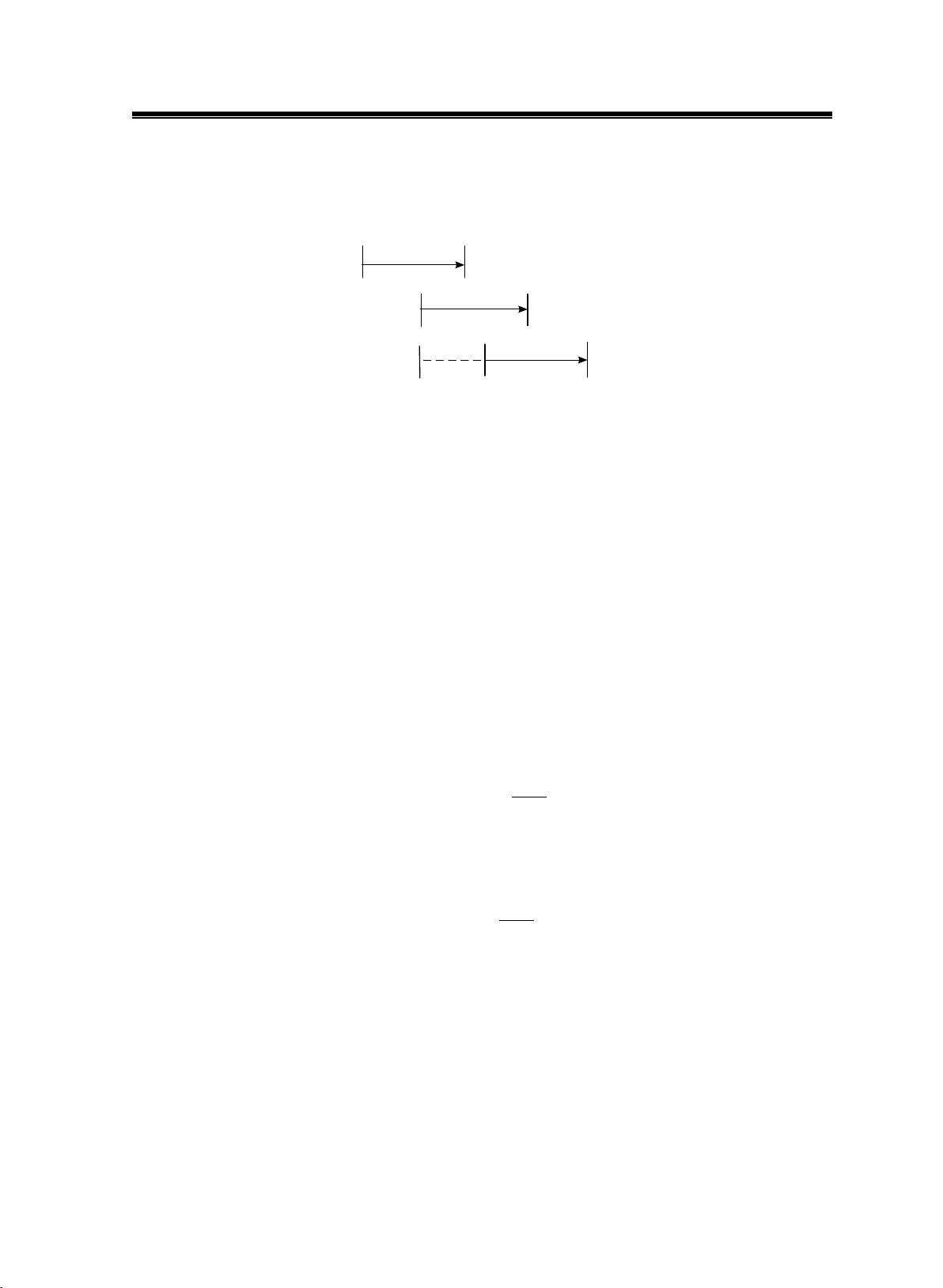
分帧。在实际处理时都是按帧取数据,处理完一帧数据后再取下一帧,这样就保证
了帧与帧之间的连续性。帧移是指两帧之间固定交叠的部分,本文选取语音帧长为
30ms,帧移为 10ms。语音信号帧长与帧移关系如图 2.3 所示。
帧移
帧长
第K帧
第K+1帧
第K+2帧
图 2.3 帧长与帧移关系图
一般采用有限长度的窗函数来截取语音信号形成分帧,窗函数
wn
将需要处理
的区域之外的样本点全部置零即可获得当前语音帧。设帧长为
N
,对已获得的一帧
信号进行加窗处理,即用确定的窗函数
wn
来乘以语音信号
xn
,得到加窗后的语
音
w
sn
:
w
s n x n w n
,
01nN
(2-2)
下面是常用的窗函数的表达式为:
矩形窗:
1,0 1
()
0, 0
nN
wn
n n N
或
(2-3)
汉明窗:
2
0.54 0.46cos( ),0 1
()
1
0, 0
n
nN
wn
N
n n N
或
(2-4)
汉宁窗:
2
0.51(1 cos( )),0 1
()
1
0, 0
n
nN
wn
N
n n N
或
(2-5)
接下来是对三种窗函数的性能进行简单比较。直接对信号加矩形窗进行截断,
会产生频谱泄露,采用非矩形的汉明或汉宁窗可以避免出现频谱的泄漏。主瓣宽度
对应频率分辨力,主瓣宽度越宽对应的频率分辨力越低,因此在选择窗函数时尽可
能将能量集中于主瓣,或者最大旁瓣高度的相对幅度尽可能小,而汉明窗在幅频特
性中旁瓣衰减较大,且可以减小吉布斯效应
[18]
,所以语音信号的分帧处理一般选择
汉明窗。
万方数据

剩余75页未读,继续阅读
2022-06-28 上传
2023-08-30 上传
2023-07-13 上传
2023-05-14 上传
2023-08-29 上传
2023-07-08 上传
2023-08-31 上传
2023-05-24 上传
2023-08-20 上传

programhh
- 粉丝: 8
- 资源: 3743
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
