"第7章:Spark大数据技术与应用-机器学习与模型评估"
本文是对《Spark大数据技术与应用-第7章.pptx》中第七章节中关于Spark机器学习库的内容进行总结。本章节主要介绍了机器学习的概念、应用和流程,并对Spark MLlib进行了简要介绍。
机器学习是人工智能的子领域,也是人工智能的核心之一。早在20世纪50年代,Samuel就给出了机器学习的定义,即通过特定编程使计算机具备学习能力。百度百科对机器学习的定义更加全面,指出它是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。机器学习专门研究计算机如何模拟或实现人类的学习行为,通过获取新的知识或技能,来不断改善自身的性能。
为什么要使用机器学习?机器学习和统计模型等基于模型的方法相比,能够发现人类难以发现的模式,特别是在数据集量级和复杂度较高的情况下。同时,基于模型的方法能够避免个人或情感上的偏见,只要应用时足够细心且正确。
在机器学习的流程中,常见的步骤包括数据获取与存储、数据清理与转换、模型训练、模型测试、模型部署与整合等。其中,数据获取与存储是获取原始数据并进行存储,数据清理与转换是对数据进行清洗和转换的过程,以便于后续的分析和建模。模型训练是通过训练数据集来构建模型,模型测试是对构建好的模型进行评估和验证。最后,将训练好的模型部署到实际应用中,并与其他系统进行整合。
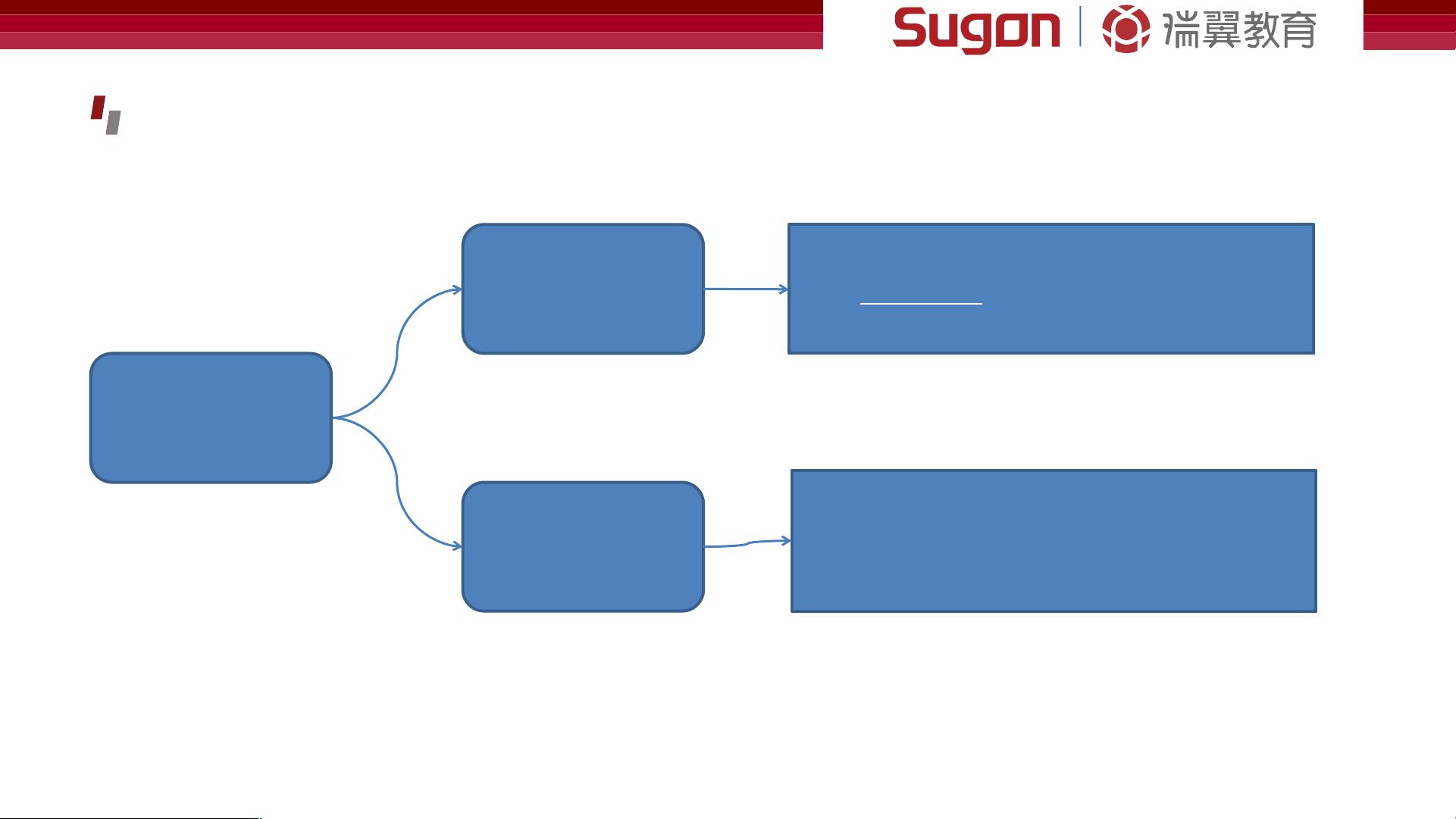
在机器学习的分类中,一种常见的方法是使用标注好的训练数据集来学习一个模型。监督学习是其中的一种方法,包括K-近邻和决策树等。此外,还有无监督学习、半监督学习和强化学习等其他分类方法。
Spark MLlib是Spark的机器学习库,它提供了丰富的机器学习算法和工具,方便用户进行大规模数据的机器学习任务。Spark MLlib支持的机器学习任务包括分类、回归、聚类和推荐等。它还提供了特征提取、特征转换和模型评估等功能,方便用户进行数据预处理和建模过程。
总之,本章节系统介绍了机器学习的概念、应用和流程,并对Spark MLlib进行了简要的介绍。通过掌握机器学习的基本原理和使用Spark MLlib进行机器学习任务的方法,可以帮助用户更高效地进行大规模数据的分析和建模,提高数据的处理效率和质量。

机器学习的分类
•
使用标注好的训练数据集学习一个模型
•
K- 近邻、决策树
监督学习
•
有训练数据集但无标签,自主推断数据
•
主成分分析、随机森林、 K-means
无监督学习
•
介于监督学习和无监督学习之间,少量标注数据
•
模式识别
半监督学习
•
通过奖励函数,输入数据对模型进行反馈
•
Q-learning
强化学习
剩余35页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-11-14 上传
2022-12-24 上传
2019-02-21 上传
2022-06-09 上传
2022-12-24 上传
2021-09-23 上传

惜于情
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 管理系统系列--中阳保险管理系统.zip
- SIMD_Convolution:超快速卷积
- test-scapy2
- 毕业设计论文-源码-ASP求职招聘网站(设计源码).zip
- CRUD-Express-Redis:这是 Express 和 Redis 中 CRUD 操作的示例
- -ember-link-to-example:演示问题测试链接到帮助程序
- 9轴加速度计、融合地磁测量(上位机、实例程序、手机APK及Android参考源码)-电路方案
- 管理系统系列--中心化的作业调度系统,定义了任务调度模型,实现了任务调度的统一管理和监控。.zip
- metaReasoningRealTimePlanning
- alpha-complex:计算任意维度中点集的 alpha 复数
- python实例-09 二维码生成器.zip源码python项目实例源码打包下载
- 【开源】仪星电子200M 双通道虚拟示波器(SDK2.0+软件+说明书等)-电路方案
- karmaPreload:Angular 2的KarmaJasmine测试方法
- strangescoop.github.io
- Binary-Tree:使用C编程语言使用基本的所需功能构建二进制树数据结构
- 管理系统系列--资产管理系统.zip
