微服务链路追踪:Sleuth与分布式追踪系统解析
32 浏览量
更新于2024-08-27
收藏 430KB PDF 举报
“第六章Sleuth--链路追踪”
在微服务架构中,随着系统复杂性的增加,服务之间的交互变得日益频繁,一次用户请求可能会触发多个服务的连锁调用。这就引出了链路追踪的重要性。链路追踪能够帮助开发者解决在分布式系统中遇到的问题,例如快速定位问题、评估故障影响、理解服务依赖关系、以及分析性能瓶颈。
6.1 链路追踪介绍
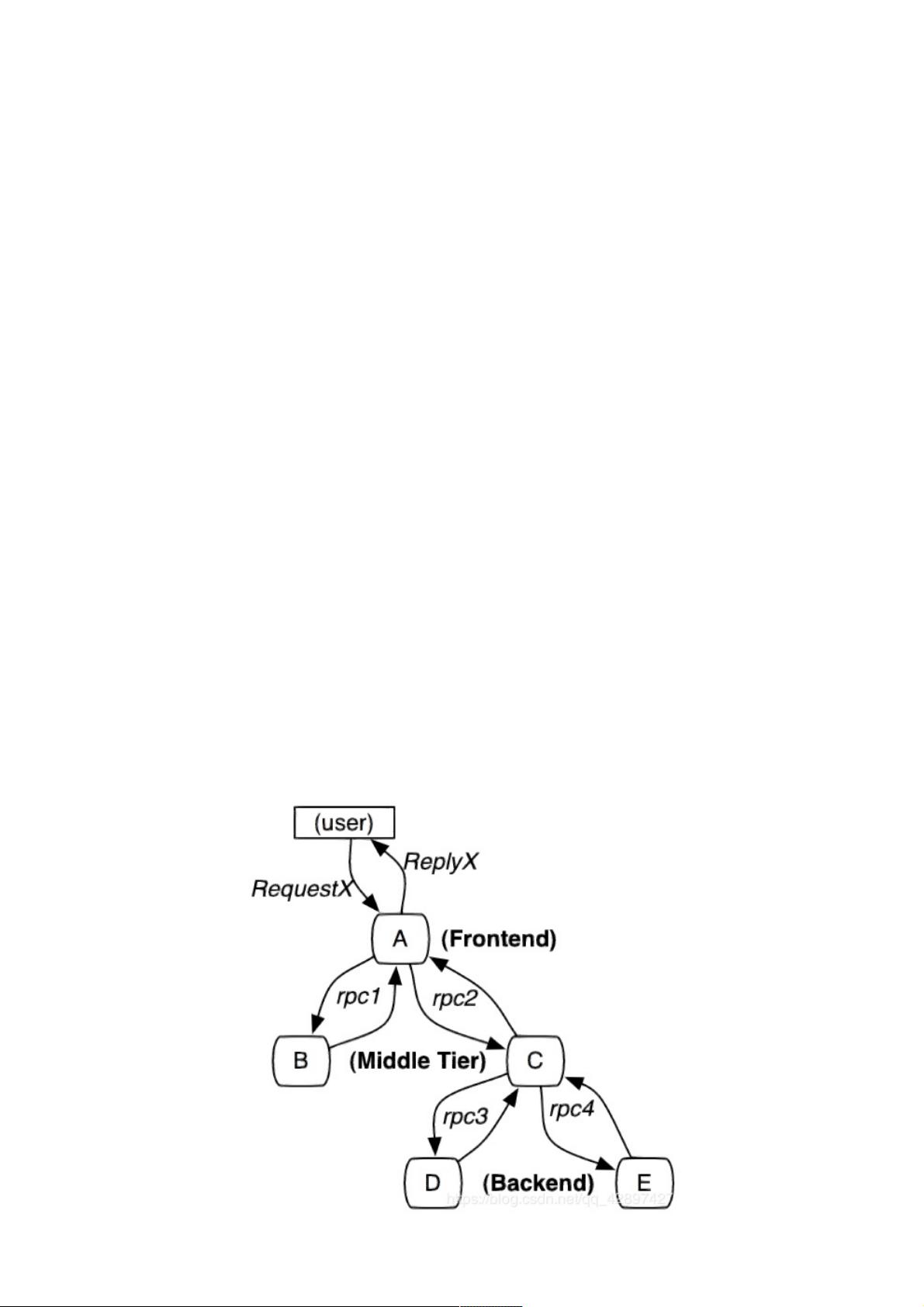
链路追踪的核心目标是跟踪和记录分布式系统中的一次请求从开始到结束所经过的所有服务和组件,形成一条完整的调用链路。这有助于开发者理解请求的执行路径,找出性能问题的源头,以及在出现问题时快速定位故障所在。常见的链路追踪技术包括:
1. Zipkin:由Twitter开源,它提供了数据收集、存储、查找和展示的服务,便于开发者查看服务间的调用延迟。Zipkin与Spring Cloud Sleuth的集成使得监控变得更加便捷,但其功能相对简洁。
2. Pinpoint:源自韩国,它采用字节码注入的方式进行调用链分析,提供丰富的UI界面,且对应用代码的入侵性较低。Pinpoint支持多种插件,适用于需要深度监控的场景。
3. SkyWalking:这是一个国内开源的项目,同样基于字节码注入,支持多种插件,具有强大的UI功能,且无需修改代码即可接入,目前已被Apache接纳为孵化项目。
4. Sleuth:作为Spring Cloud生态的一部分,Sleuth提供了与Zipkin的紧密集成,简化了在Spring Boot应用中实现分布式追踪的过程。它自动为服务间通信添加上下文信息,使得追踪数据的收集变得自动化。
通过链路追踪,开发者可以获得以下关键信息:
- 调用链路:明确请求从客户端到服务端的完整路径,包括中间经过的每一个服务和方法。
- 耗时分析:每个服务节点的响应时间,帮助识别性能瓶颈。
- 请求状态:了解每个服务节点的处理结果,如成功、失败或异常。
- 依赖关系:可视化服务之间的依赖关系,便于服务治理和优化。
- 容量规划:通过对历史数据的分析,预测系统容量需求,防止过载。
在实际应用中,Sleuth通常与Zipkin配合使用,通过收集和展示调用链路数据,为运维人员提供了一种强大的工具,以应对复杂分布式系统中的挑战。此外,Sleuth还可以与其他Spring Cloud组件,如Eureka、Hystrix、Zuul等协同工作,共同构建出一个完善的微服务监控体系。
第六章第六章Sleuth--链路追踪链路追踪
第一章 :微服务的架构介绍发展
第二章 : 微服务环境搭建
第三章 Nacos Discovery--服务治理
第四章 Sentinel--服务容错
第五章 Gateway--服务网关
第六章 Sleuth--链路追踪
第七章 Rocketmq--消息驱动
第八章 SMS--短信服务
第九章 Nacos Config--服务配置
第十章 Seata--分布式事务
6.1 链路追踪介绍
在大型系统的微服务化构建中,一个系统被拆分成了许多模块。这些模块负责不同的功能,组合成系统,最终可以提供丰富的
功能。在这种架构中,一次请求往往需要涉及到多个服务。
互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、有可
能布在了几千台服务器,横跨多个不同的数据中心,也就意味着这种架构形式也会存在一些问题
于是就出现了下面几个 问题
如何快速发现问题?
如何判断故障影响范围?
如何梳理服务依赖以及依赖的合理性?
如何分析链路性能问题以及实时容量规划?
分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式
下载后可阅读完整内容,剩余6页未读,立即下载
2024-02-04 上传
2020-08-19 上传
点击了解资源详情
2024-01-30 上传
2022-06-30 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38718415
- 粉丝: 11
- 资源: 951
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
