Flume数据采集实战:从安装到配置详解
 已收录资源合集
已收录资源合集
需积分: 0 115 浏览量
更新于2024-08-03
收藏 278KB DOCX 举报
本篇文章主要介绍了Flume数据采集在大数据领域的实战应用,特别是针对实验四——Flume客户端的安装与配置。Flume作为Apache Hadoop生态系统的重要组成部分,被广泛用于大规模数据收集和传输。实验目标是让读者掌握Flume的基本操作,通过实际步骤实现数据采集。
首先,实验开始于在MRSManager集群管理界面中启动Flume服务,并点击下载客户端,下载完成后确认下载位置,通常在Master节点的/tmp/MRS-client目录。接下来,使用Mobaxterm登录该服务器并解压Flume客户端包,确保客户端配置文件的完整性,通过执行`sha256sum-c MRS_Flume_ClientConfig.tar.sha256`进行校验。
步骤6中,安装Flume环境变量至新目录`/opt/Flumeenv`,通过执行`install.sh`脚本完成,确认安装成功的标志是"Components client installation is complete."。接着,设置环境变量,通过`source /opt/Flumeenv/bigdata_env`使系统能够识别Flume客户端。
继续进行客户端的安装,解压Flume客户端包到`/tmp/MRS-client/MRS_Flume_ClientConfig/Flume`目录下,然后使用`install.sh -d /opt/FlumeClient`命令安装,其中`-d`选项指定安装路径。如果安装成功,系统会显示"install flume client successfully."。
最后,实验涉及到了HDFS配置文件的拷贝,这一步可能是为了确保Flume能够正确地将采集到的数据存储到Hadoop分布式文件系统中,以便后续的处理和分析。这部分的具体操作未在提供的部分列出,但通常包括配置Flume的Sink(数据接收端)以连接HDFS,以及定义数据传输的Source(数据源)和Channel(数据缓冲区)。
通过这个实验,学习者将熟悉Flume的基本架构,包括数据流的源、通道和sink,以及如何配置它们以满足特定的数据采集需求。此外,安装和配置过程中对细节的关注,如环境变量设置和文件验证,对于理解Flume在实际工作中的部署和运维至关重要。熟练掌握Flume的数据采集能力,有助于在大数据分析项目中提高数据采集的效率和准确性。
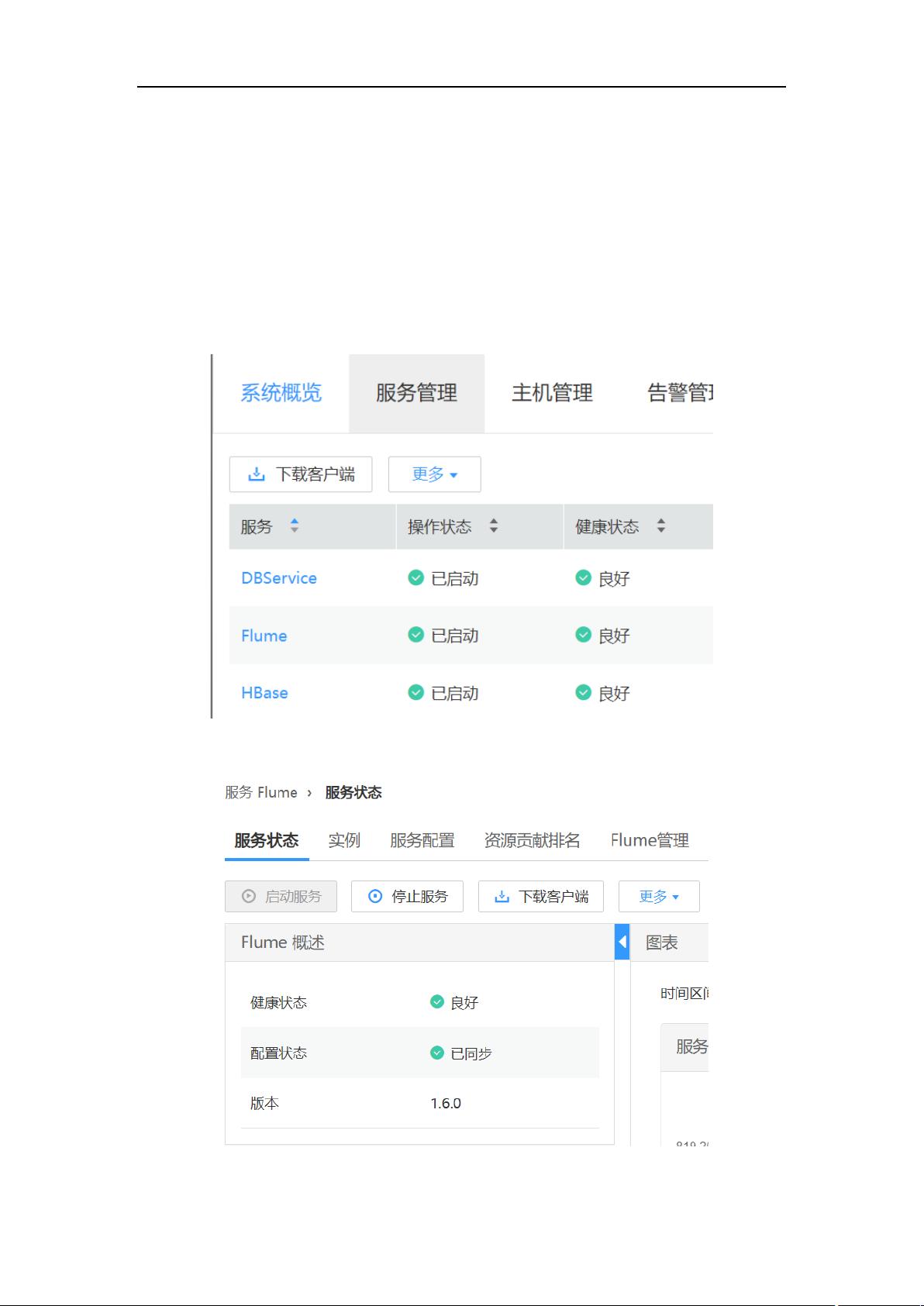
实验四 Flume 数据采集
任务一:Flume 客户端安装
步骤 1 打开 flume 服务界面
进入 MRS Manager 集群管理界面,打开服务管理,点击 Flume,进入 Flume
服务
步骤 2 点击下载客户端
点击确定,等待下载
下载后可阅读完整内容,剩余6页未读,立即下载
2019-08-13 上传
2022-03-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

爆炸西蓝花
- 粉丝: 46
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- CoreOS部署神器:configdrive_creator脚本详解
- 探索CCR-Studio.github.io: JavaScript的前沿实践平台
- RapidMatter:Web企业架构设计即服务应用平台
- 电影数据整合:ETL过程与数据库加载实现
- R语言文本分析工作坊资源库详细介绍
- QML小程序实现风车旋转动画教程
- Magento小部件字段验证扩展功能实现
- Flutter入门项目:my_stock应用程序开发指南
- React项目引导:快速构建、测试与部署
- 利用物联网智能技术提升设备安全
- 软件工程师校招笔试题-编程面试大学完整学习计划
- Node.js跨平台JavaScript运行时环境介绍
- 使用护照js和Google Outh的身份验证器教程
- PHP基础教程:掌握PHP编程语言
- Wheel:Vim/Neovim高效缓冲区管理与导航插件
- 在英特尔NUC5i5RYK上安装并优化Kodi运行环境
