"Python OpenCV YOLOv5行人目标检测实现及方法介绍"
需积分: 0 21 浏览量
更新于2024-01-11
5
收藏 2.38MB DOCX 举报
目标检测在计算机视觉领域有着广泛的应用,可以支持多种任务,如实例分割、姿态估计、跟踪和动作识别。在监控、自动驾驶和视觉答疑等领域,目标检测的需求越来越大。因此,研究人员不断努力提出新的目标检测方法,并使用机器学习技术来训练更准确、高效的模型。
本文介绍了使用Python OpenCV yolov5实现行人目标检测的方法。行人目标检测是一种常见的目标检测任务,也是许多应用领域的基础。研究团队在Fynd的研究中一直致力于训练一个行人检测模型来支持目标跟踪模型的开发。
目标检测可以理解为两部分,目标定位和目标分类。目标定位即预测对象在图像中的位置,通常使用边界框来表示。而目标分类则是确定对象所属的类别,如人、车、狗等。目标检测方法可以分为三类:级联检测器、带锚框的单级检测器和无锚框的单级检测器。
级联检测器是目标检测的一种常见方法,它包含两种网络类型,一种是RPN(Region Proposal Network)网络,用于提出候选目标区域;另一种是检测网络,用于对候选区域进行分类。典型的例子是RCNN系列。
带锚框的单级检测器是另一种常用的目标检测方法,它不需要独立的RPN网络,而是依赖于预定义的锚框。YOLO(You Only Look Once)系列就是这种类型的检测器。YOLO将图像分成网格,每个网格预测多个边界框和相应的类别概率,然后通过非极大值抑制(NMS)将重叠的候选框合并。
无锚框的单级检测器是目标检测问题的一种新方法,它是端到端可微的,不依赖于感兴趣区域。这种方法将图像直接映射到目标属性,实现了更简洁的模型和更高效的训练过程。
在行人目标检测的研究中,使用了Python和OpenCV库,以及yolov5模型实现了行人目标检测。yolov5是YOLO系列的最新版本,相比之前的版本,yolov5在网络结构和训练方法上都有所改进,提供了更高的检测精度和更快的检测速度。在使用yolov5进行行人目标检测时,还需要选择适当的数据集进行模型训练。数据集的选择应该与特定的应用场景相关,并包含足够多样的行人图像样本。
总而言之,目标检测是计算机视觉中一个重要的任务,可以支持多种应用领域。本文介绍了使用Python OpenCV yolov5实现行人目标检测的方法,并对目标检测的常用方法进行了分类和介绍。在行人目标检测的研究中,选择合适的模型架构和数据集是至关重要的,可以通过不断的实践和优化来提高检测精度和性能。
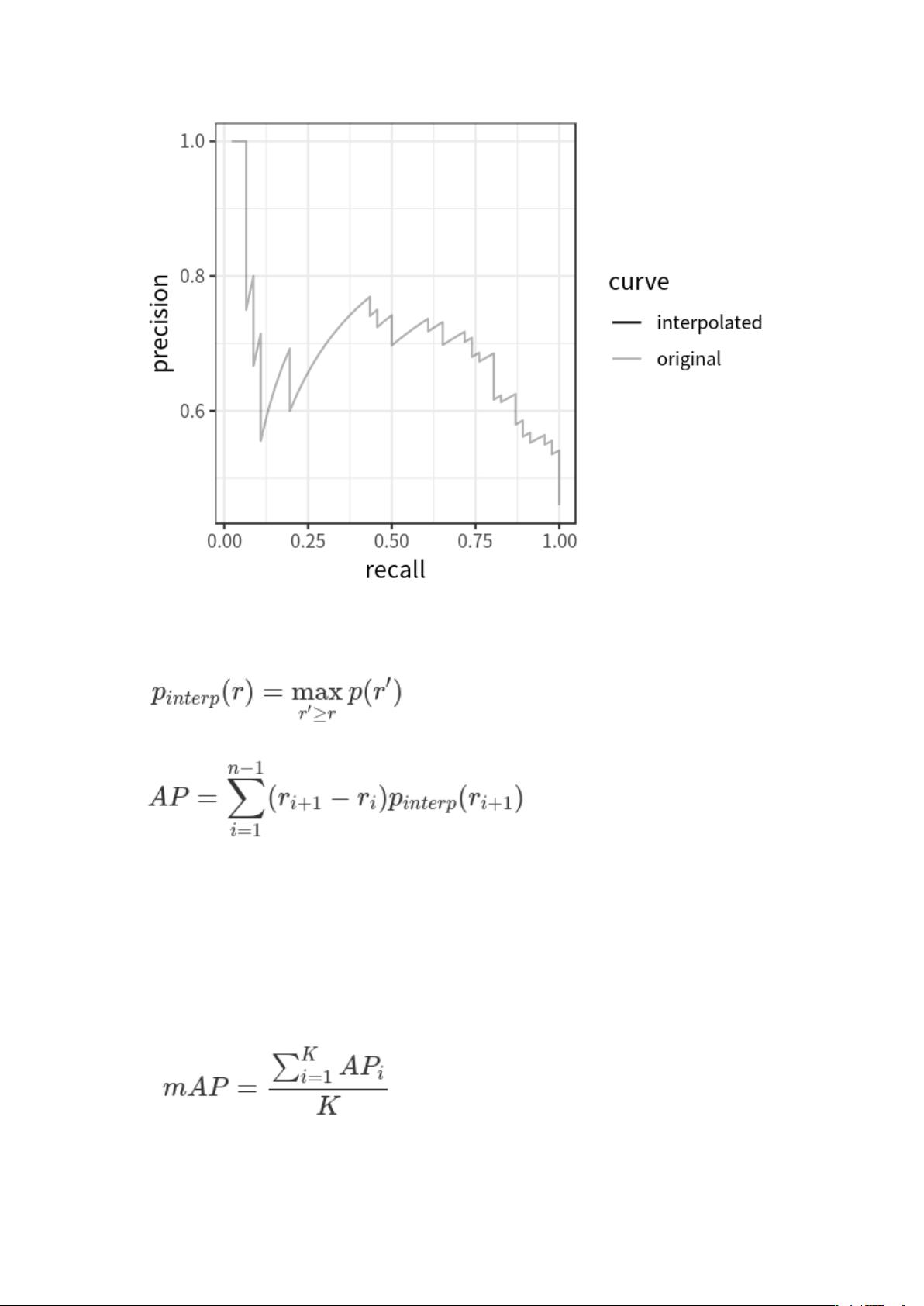
AP 可定义为插值精度召回曲线下的面积,可使用以下公式计算:
mAP
AP 的计算只涉及一个类,然而,在目标检测中,通常存在 K>1 类。*均精度(Mean
average precision,mAP)定义为所有 K 类中 AP 的*均值:
剩余18页未读,继续阅读
2019-06-20 上传
2019-03-02 上传
2018-01-22 上传
2023-06-02 上传
2023-06-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

极客11
- 粉丝: 386
- 资源: 5519
 我的内容管理
展开
我的内容管理
展开







最新资源
- CoreOS部署神器:configdrive_creator脚本详解
- 探索CCR-Studio.github.io: JavaScript的前沿实践平台
- RapidMatter:Web企业架构设计即服务应用平台
- 电影数据整合:ETL过程与数据库加载实现
- R语言文本分析工作坊资源库详细介绍
- QML小程序实现风车旋转动画教程
- Magento小部件字段验证扩展功能实现
- Flutter入门项目:my_stock应用程序开发指南
- React项目引导:快速构建、测试与部署
- 利用物联网智能技术提升设备安全
- 软件工程师校招笔试题-编程面试大学完整学习计划
- Node.js跨平台JavaScript运行时环境介绍
- 使用护照js和Google Outh的身份验证器教程
- PHP基础教程:掌握PHP编程语言
- Wheel:Vim/Neovim高效缓冲区管理与导航插件
- 在英特尔NUC5i5RYK上安装并优化Kodi运行环境
