无限期强化学习与最优化控制
需积分: 9 137 浏览量
更新于2024-07-15
收藏 1.07MB PDF 举报
"RL_MONOGRAPH5.pdf 是麻省理工学院Dimitri P. Bertsekas教授关于强化学习和最优控制的教材章节。该章节聚焦于无限期强化学习,目前仍处于草稿阶段,可能会有错误并缺乏完整的文献引用。作者欢迎读者提供反馈和建议。最新修订日期为2019年4月1日。章节内容涵盖了价值空间的近似及性能边界、有限展望、滚动策略、近似策略迭代、拟合值迭代以及基于模拟的参数化近似策略迭代等方法。"
强化学习是人工智能领域的一个重要分支,它涉及智能体在与环境的交互中通过试错学习来优化其行为策略。无限期强化学习关注的是在没有预设终止状态的情况下,如何进行有效的学习和决策。
5.1.1. 有限展望:在强化学习中,有限展望是一种策略,其中智能体只考虑未来有限步的结果来决定当前动作,而不是考虑整个未来的奖励。这种方法可以降低计算复杂性,但可能牺牲一定的性能。
5.1.2. 滚动策略(Rollout):这是一种策略评估技术,它通过扩展当前策略的有限步数来估计其长期效果。这可以被视为对完全展开策略的一种近似,可以用于在实际应用中平衡计算成本和准确性。
5.1.3. 近似策略迭代:在策略迭代算法中,如果环境状态空间过大,无法精确存储或计算所有状态的价值函数,可以使用近似方法。近似策略迭代结合了策略改进和价值函数的近似更新,以适应大规模问题。
5.2. 拟合值迭代(Fitted Value Iteration):这是强化学习中的一种策略,它涉及到使用一组样本来训练一个函数近似器(如神经网络),以拟合每个状态的价值函数。这种方法允许处理连续状态空间,并且可以迭代地改进近似。
5.3. 基于模拟的参数化近似策略迭代:在具有参数化策略的环境中,智能体可以学习并调整这些参数以优化其长期回报。自我学习系统和演员-评论家系统是这类方法的实例,其中自我学习系统同时更新策略和价值函数,而演员-评论家系统则将策略更新(演员)与价值函数评估(评论家)分开。
5.3.1. 自我学习和演员-评论家系统:自我学习系统通过同时更新策略和价值函数来学习,而演员-评论家系统则引入两个相互作用的组件,演员负责更新策略,评论家负责评估策略的效果,以实现策略的改进。
这些内容构成了强化学习理论和实践的基础,对于理解如何在实际问题中有效地应用强化学习至关重要。无论是有限展望、滚动策略还是近似方法,都是为了在计算限制下找到接近最优策略的有效途径。
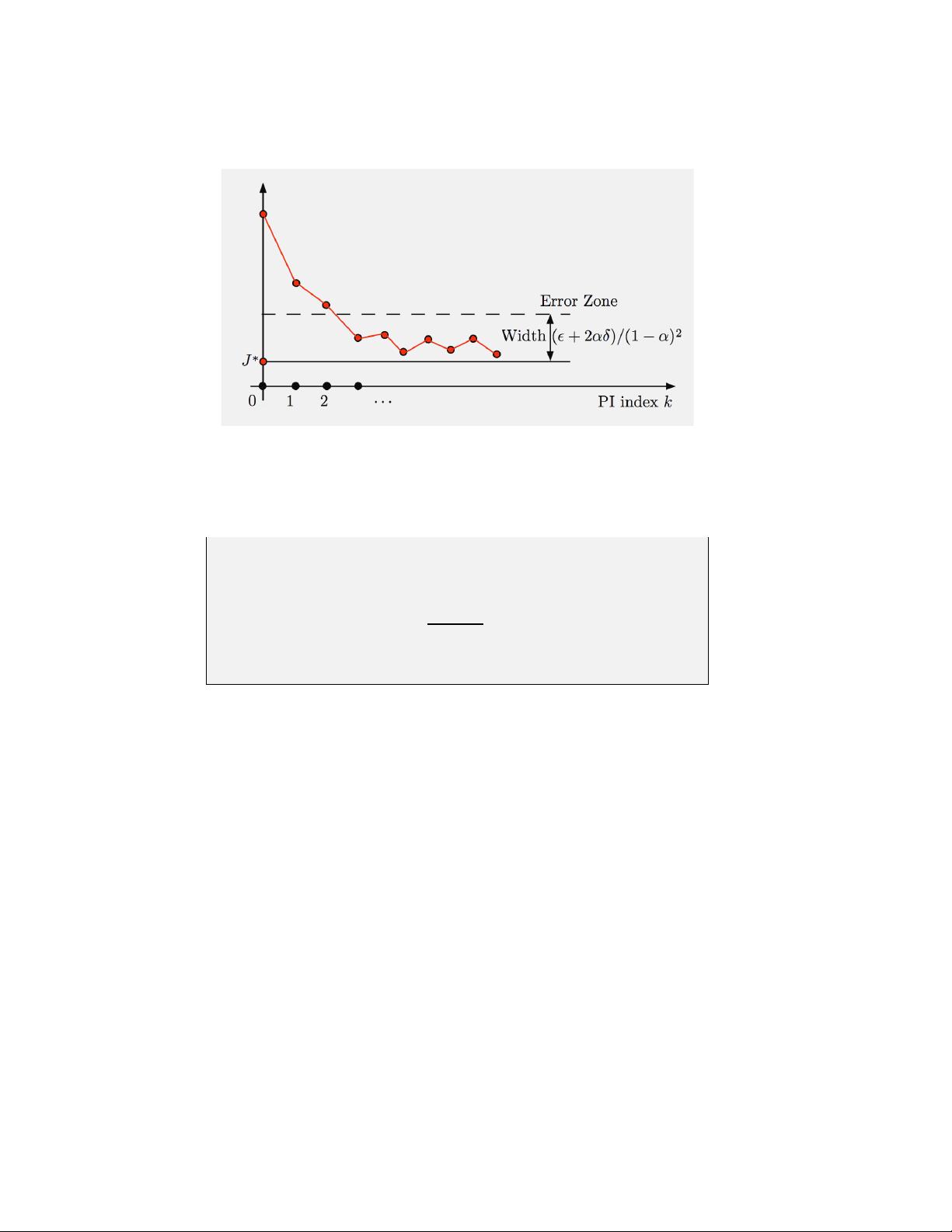
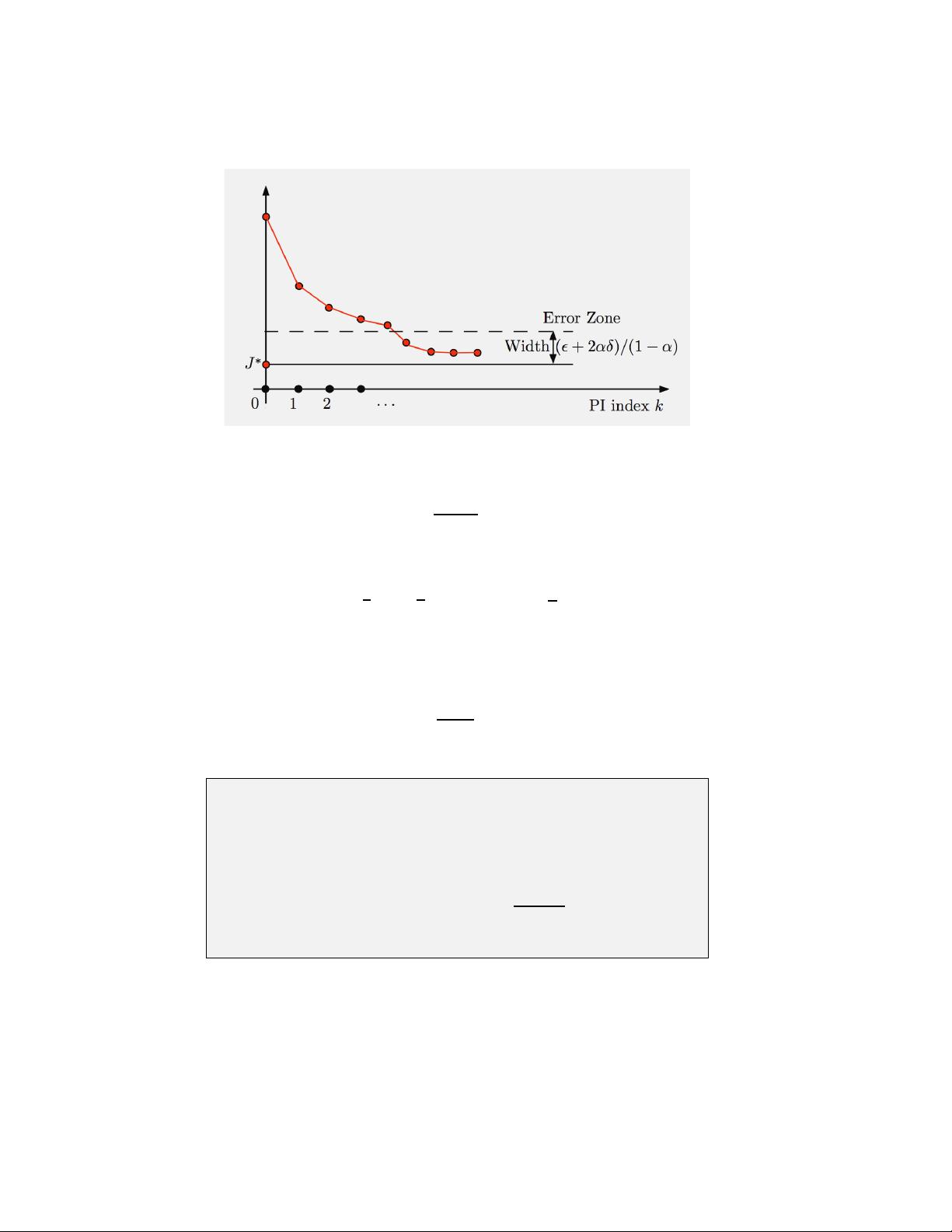
12 Infinite Horizon Reinforcement Learning Chap. 5
k PI index k J
∗
0 1 2
0 1 2
0 1 2 . . .
0 1 2 . . .
J
∗
. . . Error Zone Width (
Error Zone Width (ǫ + 2αδ)/(1 − α)
2
) J
µ
k
Figure 5.1.4 Illustration of typical behavior of approximate PI. In the early
iterations, the method tends to make rapid and fairly monotonic progress, until
J
µ
k
gets within an error zone of s ize less than (ǫ + 2αδ)/(1 − α)
2
. After that J
µ
k
oscillates randomly within that zone.
max
i=1,...,n
J
µ
k
(i) − J
*
(i)
,
becomes less or equal to
ǫ + 2αδ
(1 − α)
2
,
asymptotically as k → ∞.
The preceding performance bound is not particularly useful in prac-
tical terms. Significantly, howeve r, it is in qualitative agreement with the
empirical behavior of approximate PI. In the b eginning, the method tends
to make rapid and fairly monotonic progress , but eventually it gets into
an oscillatory pattern. This happens after J
µ
k
gets within an error zone of
size (ǫ + 2αδ)/(1 − α)
2
or smaller, and then J
µ
k
oscillates fairly randomly
within that zone; see Fig. 5.1.4. In practice, the error bound of Prop. 5.1.4
tends to be pessimistic, so the zone of oscillation is usually much narrower
than what is suggested by the bound. However, the bound itself can be
proved to be tight, in worst case. This is shown with an e xample in the
book [BeT96], Sectio n 6.2.3. Note also that the bound of Prop. 5.1.4 holds
in the case of infinite state and control spaces disco unted problems, when
there are infinitely many policies (see [Ber18a ], Prop. 2.4.3).
Performance Bound for the Case Where Policies Converge
Generally, the policy sequence {µ
k
} generated by approximate PI may


剩余75页未读,继续阅读
2020-11-10 上传
2020-11-10 上传
2024-10-15 上传
2024-10-15 上传
2024-10-15 上传
2024-10-15 上传

Quant0xff
- 粉丝: 1w+
- 资源: 459
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
