使用PaddlePaddle进行CIFAR10猫狗图像分类
2 浏览量
更新于2024-08-03
收藏 1.07MB PDF 举报
"本文档介绍了如何使用人工智能技术,特别是基于PaddlePaddle的深度学习框架,来解决猫狗分类问题。实验使用CIFAR10数据集,该数据集包含了10个类别的图像,而任务是仅针对猫和狗进行分类。实验涉及自定义数据读取器(train_reader和test_reader),数据预处理,CNN网络模型构建,模型训练与评估,以及模型优化和预测。在实验中,模型的准确度和损失值被用来衡量模型性能,并指出需要进一步优化以提高预测准确性。"
在这个实验中,首先我们需要了解图像分类的基本概念,它是计算机视觉领域的一个核心任务,旨在根据图像的内容将其归类到不同的类别中。猫狗分类作为粗粒度分类问题,意味着我们需要区分的类别相对较少,但图像之间的差异可能较小,增加了分类难度。
CIFAR10数据集是一个常用的图像识别数据集,由60,000张32x32像素的彩色图像组成,分为10个类别,每个类别有6,000张图片。数据集被划分为训练集(50,000张)和验证集(10,000张)。在这个实验中,我们只关注猫和狗两类。
数据处理部分,通过自定义`train_reader`和`test_reader`来读取和处理训练集和测试集。`paddle.reader.shuffle()`用于随机打乱训练数据,确保模型在训练过程中遇到的数据顺序是随机的,避免了训练过程中的顺序偏见。`paddle.batch()`则将数据分批处理,参数`BATCH_SIZE`决定了每批数据的大小。
网络配置阶段,实验使用了卷积神经网络(CNN),CNN能够有效地捕捉图像的局部特征。这个简单的CNN模型包括多次卷积层、池化层和BatchNorm层,最后通过全连接层和softmax激活函数实现分类。池化层通常采用最大池化,减少计算量并防止过拟合。BatchNorm2D层的作用是在训练过程中保持每一层输入数据的分布稳定,有助于网络的收敛。
模型训练和评估阶段,通过训练模型并观察accuracy和loss的变化来评估模型性能。如果accuracy较低(如0.6),loss较大,这意味着模型的预测效果不佳,需要对模型进行调整和优化。
实验结果分析表明,当前模型的预测精度不够理想,存在误判情况。为了提升模型性能,可能需要尝试以下方法:增加网络深度或宽度,使用更复杂的网络结构(如ResNet、VGG等),调整学习率策略,引入正则化防止过拟合,或者使用数据增强技术扩大训练集的多样性。
这个实验是一个典型的人工智能应用案例,展示了如何使用PaddlePaddle进行深度学习模型的构建、训练和优化,以解决现实世界中的猫狗分类问题。通过不断的迭代和优化,我们可以期待模型的预测能力得到显著提升。
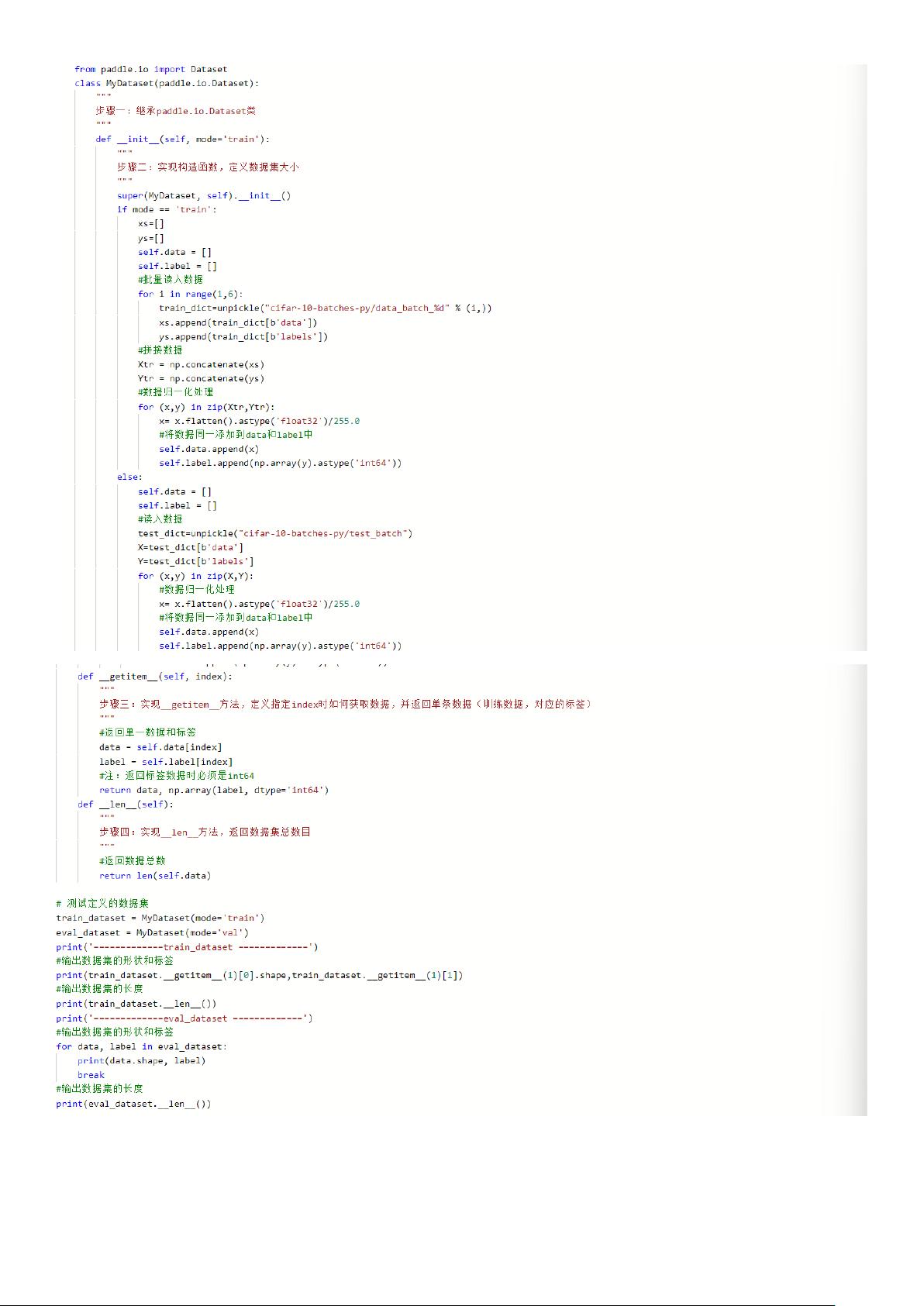
输出数据集的形状和标签
输出数据集的长度
剩余13页未读,继续阅读
2023-12-14 上传
2024-11-14 上传
2019-04-17 上传
2022-10-15 上传
2024-09-14 上传
2024-06-14 上传
2021-03-02 上传

小嘤嘤怪学
- 粉丝: 1520
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- wadegao.github.io:韦德高的个人主页
- pcsetup:从零开始设置我的个人计算机的脚本
- A2G-2020.0.1-py3-none-any.whl.zip
- 升降台程序11.rar
- MDN-note
- Kyhelper:考研助手,利用了Bmob移动后端云服务平台和腾讯旗下的微社区,感谢imooc网和校园小菜的技术指导。 给考研学子们提供一个方便的工具,可以让他们收起鼠标和键盘,逃离喧闹狼藉的宿舍,在自习室里用手机就能查看大部分最重要的考研相关信息。在考研备考过程中要时常打开电脑上网到处浏览与考研相关的信息,生怕错过什么重要通知,那么,如果能有这么一款手机应用,它能够给考研学生带来一定的帮助,成为学子贴身的考研小助手,从而使他们更好地高效率的投入到自己的复习当中。 比如说,看书累了
- michaelkulbacki.github.io:我的个人网站上展示了我的计算机科学项目和摄影作品
- gmod-Custom_FOV:Garry Mod的插件,可以更改fov值
- wfh.vote
- minesweeper-cljs:使用leiningen和figwheel在ClojureScript中实现扫雷游戏的实现
- 2013-2019年重庆理工大学825管理学考研真题
- gulp-font2css:使用 Gulp 将字体文件编码为 CSS @font-face 规则
- 3.14159.in:pi数字的彩色渲染
- AABBTree-0.0a0-py2.py3-none-any.whl.zip
- DataMiningLabTasks
- 机器学习文档(transformer, BERT, BP, SVD)
