深入理解Hadoop架构:核心组件与应用场景
版权申诉
137 浏览量
更新于2024-06-29
收藏 513KB PPTX 举报
"Hadoop技术-Hadoop架构简介.pptx"
Hadoop是大数据处理领域的一个核心框架,其设计目标是处理和存储海量数据。Hadoop的生态系统由多个关键组件构成,这些组件共同协作,提供了一个可靠的、可扩展的分布式计算环境。
Hadoop分布式文件系统(HDFS)是Hadoop的基础,它是一个高容错性的系统,能够将大型数据集分布在大量的廉价硬件上。HDFS由NameNode和DataNode组成。NameNode是HDFS的主节点,负责存储和管理文件系统的元数据,包括文件名、文件属性、文件目录结构等。而DataNode是HDFS的工作节点,它们在本地文件系统中存储实际的数据块,并执行数据的校验。
SecondaryNameNode并非NameNode的备份,而是协助NameNode的角色,定期合并NameNode的元数据日志,以减轻NameNode的负担,确保系统稳定运行。
MapReduce是Hadoop的计算框架,它将复杂的分布式计算简化为两个主要阶段:Map和Reduce。Map阶段将数据源拆分成键值对,然后并行处理;Reduce阶段则负责对Map阶段的结果进行聚合和汇总,输出最终结果。YARN(Yet Another Resource Negotiator)作为Hadoop的资源管理系统,负责调度和分配集群资源,使得各种应用程序能在集群上高效运行。ResourceManager全局管理资源,NodeManager监控每个节点的资源,ApplicationMaster协调应用程序的执行,Container则是资源分配的基本单位,包含运行任务所需的资源和环境。
HBase是建立在HDFS之上的NoSQL数据库,它提供了一个高吞吐量的随机访问方式来处理大数据。Hive则是一个基于Hadoop的数据仓库工具,允许用户使用类SQL的HQL语言来查询和分析存储在HDFS中的大量数据,简化了大数据的查询操作。Pig是另一个Hadoop上的数据分析平台,它的PigLatin语言提供了一种抽象层,使得处理Hadoop数据变得更加简单。
Hadoop生态系统包括了HDFS、MapReduce、YARN、HBase、Hive和Pig等多个组件,它们协同工作,为大数据的存储、处理和分析提供了强大支持。Hadoop的灵活性和可扩展性使其成为处理大规模数据的理想选择,广泛应用于互联网、电信、金融等多个行业。
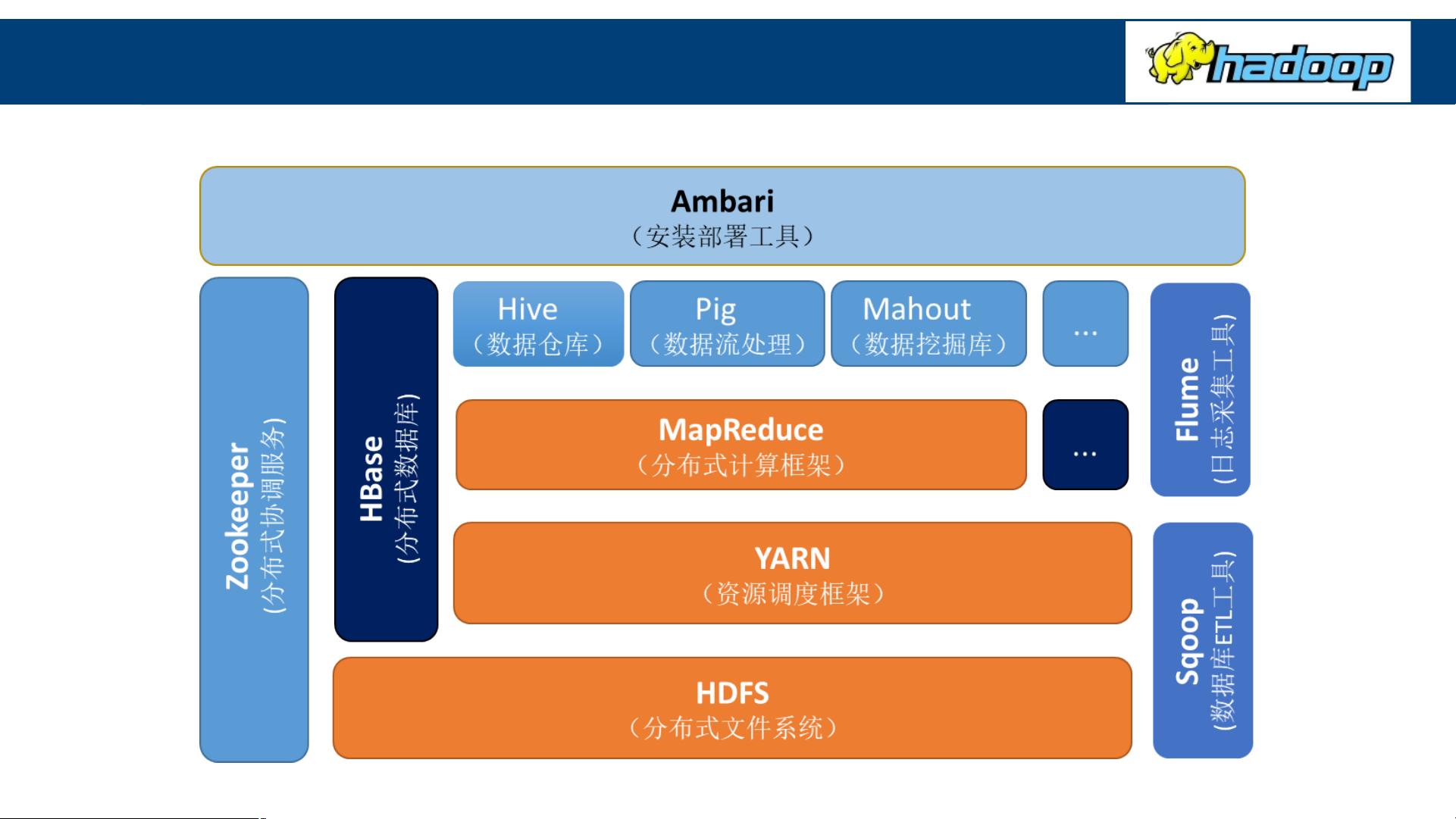
Hadoop生态系统
剩余14页未读,继续阅读
2022-11-02 上传
2022-11-02 上传
2022-11-02 上传
2022-11-02 上传
2022-11-02 上传

知识世界
- 粉丝: 371
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
