中国姓氏排行研究:数据清洗与分布分析
需积分: 0 53 浏览量
更新于2024-08-04
1
收藏 3.64MB DOCX 举报
本次作业是关于中国姓氏排行的研究,主要涉及数据清洗、整合和分析三个部分。首先,任务要求从"data01"和"data02"两个数据文件中读取数据,然后使用Python的pandas库中的`pd.concat()`函数将它们合并成一个完整的数据集。这个过程需要注意的是,需要结合“户籍地城市编号”以及“中国城市代码对照表”来获取城市的经纬度信息,并将其添加到合并后的数据中。
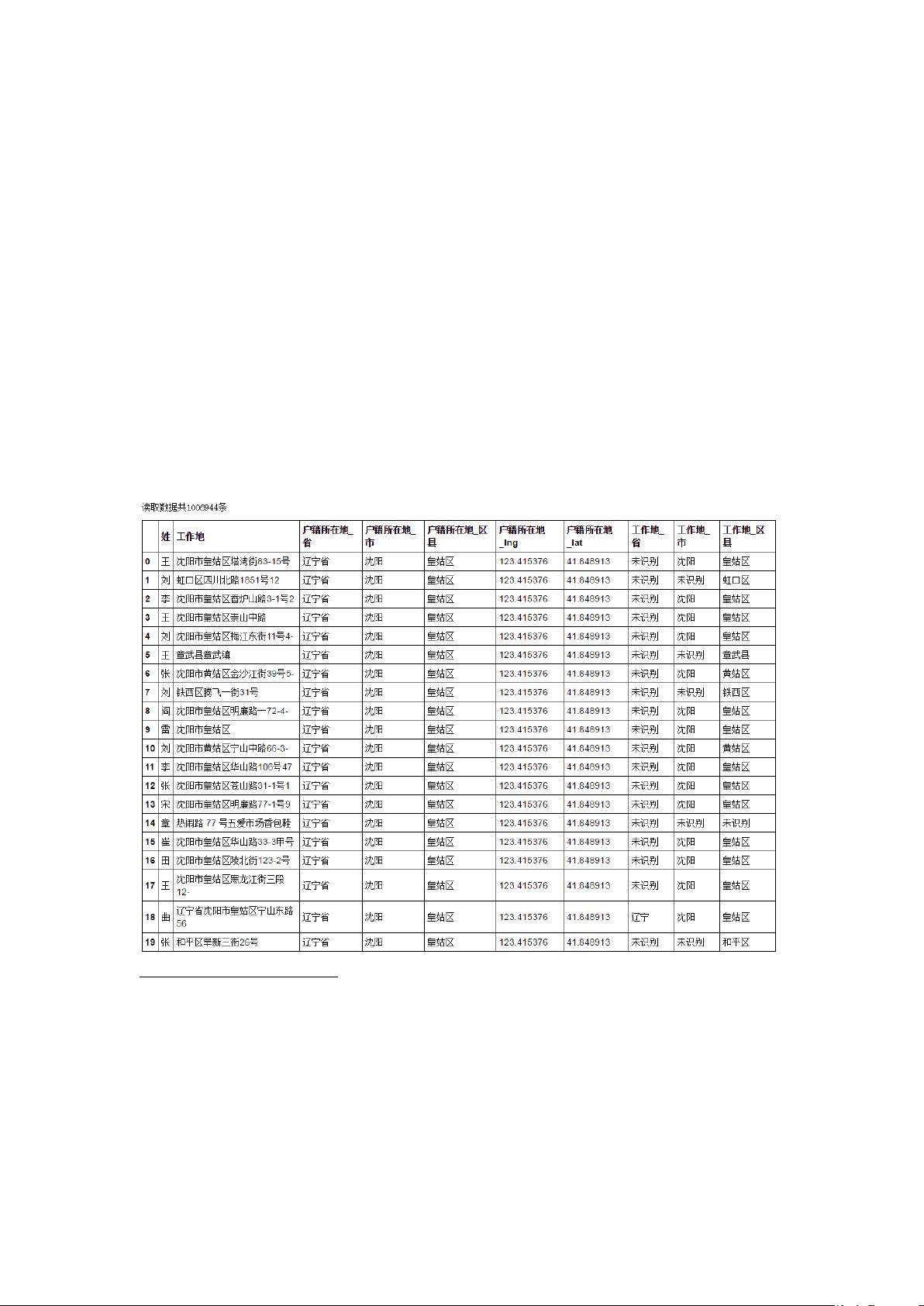
接下来,作业要求对“工作地”字段进行处理。需要创建新的字段来分别表示“工作地”的省、市和区县信息。如果数据中无法准确提取省和市,则用“未识别”填充。对于“工作地”的处理,关键在于检查识别结果,如果识别后的文本长度超过5个字符,就标记为“未识别”。
整合后的数据量大约为1006944条,数据清洗和结构化对于后续的分析至关重要。
在分析部分,学生需要按姓氏进行统计,找出人口数量最多的前20个姓氏,并用Bokeh库制作柱状图,实现数据的可视化,同时提供联动功能。对于“王”和“姬”这两个特定姓氏,要求分别查看其在全国的分布情况。这包括导出Excel文件并利用PowerMap工具绘制密度图,以及尝试使用ECharts绘制空间柱状图。PowerMap需要Office 2016或更高版本支持,并确保使用xlsx格式存储数据。在PowerMap中,通过设置“值”为姓氏计数来创建热力图,并能调整配色风格和地图类型。
对于“奔波指数”的计算,学生需要根据识别的工作地信息,通过Geocoding服务获取精确坐标,然后计算每个姓氏的人均迁徙距离,即户籍地与现居住地所在地级市之间的距离。最后,选择一个姓氏,详细展示其迁徙距离的分布情况。
这项作业涵盖了数据处理、数据可视化、地理编码和数据分析等多个IT技能的应用,旨在通过实际操作让学生深入理解如何在Python环境下处理和分析大规模的地理位置数据,并通过图形化呈现来探索中国姓氏的地域分布特征。
【项目 09】 中国姓氏排行研究
作业要求
1、数据清洗、整合
要求:
① 将“data01”、“data02”分别读取,并且合并成一个数据
② 结合“户籍地城市编号”及“中国城市代码对照表”数据,将城市经纬度连接进数据中
③ 分别提取“工作地”中的省、市
提示:
① 可以先读取“data01”、“data02”,然后用 pd.concat()来连接数据
② 新建字段“工作地-省”,“工作地-市”,“工作地-区县”,如果数据中“工作地”字段无法提取省
和市,则用“未识别”填充单元格
* 通过查看识别后的单元格,如果字数超过 5 则为“未识别”据
② 新建字段“工作地-省”,“工作地-市”,“工作地-区县”,如果数据中“工作地”字段无法提取省
和市,则用“未识别”填充单元格
* 通过查看识别后的单元格,如果字数超过 5 则为“未识别”
整理后数据大概 1006944 条
下载后可阅读完整内容,剩余5页未读,立即下载
2011-11-07 上传
2021-10-01 上传
点击了解资源详情
2012-05-12 上传
2021-09-11 上传
2021-10-01 上传
2021-04-02 上传
2021-08-07 上传
2021-08-06 上传

坐在地心看宇宙
- 粉丝: 32
- 资源: 330
 我的内容管理
展开
我的内容管理
展开







最新资源
- aggregate_resources:与使用传统循环相比,此仓库包含一个汇总参数示例。 该演示是使用eos_vlan模块在Arista vEOS上完成的
- spatial_rcs
- socket_handshake
- CubeApi
- 文件时间批量修改工具(指定时间随机)
- ncomatlab代码-x5chk2021:x5chk2021
- python-math-solver:用Python编写的定理证明者求解器
- laravel-grid-app:Laravel应用程序展示leantonylaravel-grid软件包功能
- Tag-Based-File-Manager:用python编写的基于标签的文件管理器
- kxmlrpcclient:KXMLRPCClient-帮助使用XML-RPC API的库
- ProjetosJava
- 英语-
- ncomatlab代码-pyldas:土地数据同化系统(LDAS)的python包
- dictionary-app
- COSC-473-项目
- ExampleOfiOSLiDAR:iOS ARKit LiDAR的示例
