Mamba:线性时间序列建模与选择性状态空间
需积分: 0 50 浏览量
更新于2024-06-18
收藏 1.23MB PDF 举报
"Mamba:Linear-TimeSequenceModelingwithSelectiveStateSpaces是针对深度学习领域,特别是 Transformer 架构的一种新方法,旨在解决长序列处理时的计算效率问题。该论文提出了一个名为 Mamba 的模型,它结合了结构化状态空间模型(Structured State Space Models, SSMs)与输入地址相关的参数,以实现线性时间复杂度的序列建模,并在内容推理能力上进行了增强。"
深度学习和人工智能领域的进步主要归功于基础模型,这些模型大多基于Transformer架构及其核心的注意力机制。Transformer由于其强大的表示能力和广泛的应用,已经在多个领域取得了显著成果,特别是在语言等重要模态上。然而,随着序列长度的增加,Transformer的计算复杂度呈平方级增长,这限制了其在处理长序列任务时的效率。
为了克服这一挑战,研究者们提出了许多次平方时间复杂度的架构,如线性注意力、门控卷积和递归模型,以及结构化状态空间模型(SSMs)。尽管这些方法在一定程度上缓解了计算效率问题,但它们在处理语言等关键模态时的表现并未能超越注意力机制。Mamba模型的出现正是针对这个问题,它试图弥补SSM模型在内容推理能力上的不足。
Mamba模型的创新之处在于两方面:首先,它允许SSM的参数成为输入地址的函数,这在离散模态中解决了SSM的弱点。通过这种方式,模型可以根据当前的令牌动态地选择性地传播或遗忘序列中的信息,增强了对序列长度维度上的信息处理能力。其次,即使在连续模态中,Mamba也通过引入内容依赖的更新规则来强化内容推理。这使得模型能够在处理序列时更加智能地决定哪些信息应该被保留,哪些可以被忽略,从而提高效率并保持性能。
此外,论文可能还探讨了如何在保持线性时间复杂度的同时,有效地整合这些改进,以及在实际任务中的性能对比,例如机器翻译、语言建模和音频处理等。通过对这些任务的实验验证,Mamba展示了一种既能高效处理长序列,又能在多种模态中保持竞争力的新型序列建模方法。
"Mamba: Linear-Time Modeling With Selective State Space"为深度学习领域的序列建模提供了一个新视角,它不仅优化了计算效率,还提升了模型在内容推理方面的表现,对于推动未来高效且强大序列模型的发展具有重要意义。

we want to maximize h idden state dimension without paying speed and memory costs.
•
Note that the recurrent mode is more flexible than the convolution mode, since the latter
(3)
is derived from
expanding the former
(2)
(Gu, Goel, and Ré 2022; Gu, Johnson, Goel, et al. 2021). However, this would require
computing and materializing the latent state
ℎ
with shape
(𝙱, 𝙻, 𝙳, 𝙽)
, much larger (by a factor of
𝑁
, the SSM
state dimension) than the input
𝑥
and output
𝑦
of shape
(𝙱, 𝙻, 𝙳)
. Thus the more efficient convolution mode was
introduced which could bypass the state computation and materializes a convolution kernel
(3a)
of only
(𝙱, 𝙻, 𝙳)
.
•
Prior LTI SSMs leverage the dual recurrent-convolutional forms to increase the effective state dimension by a
factor of 𝑁 (≈ 10 − 100), much larger than traditional RNNs, without efficiency p enalties.
3.3.2 Overview of Selective Scan: Hardware-Aware State Expansion
The selection mechanism is designed to overcome the limitations of LTI models; at the same time, we therefore
need to revisit the computation problem of SSMs. We address this with three classical techniques: kernel fusion,
parallel scan, and recomputation. We make two main observations:
•
The naive recurrent computation uses
𝑂(𝐵𝐿𝐷𝑁)
FLOPs while the convolutional computation uses
𝑂(𝐵𝐿𝐷 log(𝐿))
FLOPs, and the former has a lower constant factor. Thus for long sequences and not-too-large state dimension
𝑁, the recurrent mode can actually use fewer FLOPs.
•
The two challenges are the sequential nature of recurrence, and the large memory usage. To address the latter,
just like the convolutional mode, we can attempt to not actually materialize the full state ℎ.
The main idea is to leverage properties of modern accelerators (GPUs) to materialize the state
ℎ
only in more
efficient levels of the memory hierarchy. In particular, most operations (except matrix multiplication) are bounded
by memory bandwidth (Dao, Fu, Ermon, et al. 2022; Ivanov et al. 2021; Williams, Waterman, and Patterson
2009). This includes our scan operation, and we use kernel fusion to reduce the amount of memory IOs, leading to
a significant speedup compared to a standard implementation.
Concretely, instead of preparing the scan input
(A, B)
of size
(𝙱, 𝙻, 𝙳, 𝙽)
in GPU HBM (high-bandwidth memory),
we load the SSM parameters
(∆, A, B, C)
directly from slow HBM to fast SRAM, perform the discretization and
recurrence in SRAM, and then write the final outputs of size (𝙱, 𝙻, 𝙳) back to HBM.
To avoid the sequential recurrence, we observe that despite not being linear it can still be parallelized with a
work-efficient parallel scan algorithm (Blelloch 1990; Martin and Cundy 2018; Smith, Warrington, and Linderman
2023).
Finally, we must also avoid saving the intermediate states, which are necessary for backpropagation. We carefully
apply the classic technique of recomputation to reduce the memory requirements: the intermediate states are not
stored but recomputed in the backward pass when the inputs are loaded from HBM to SRAM. As a result, the
fused selective scan layer has the same memory requirements as an optimized transformer implementation with
FlashAttention.
Details of the fused kernel and recomputation are in Appendix D. The full Selective SSM layer and algorithm is
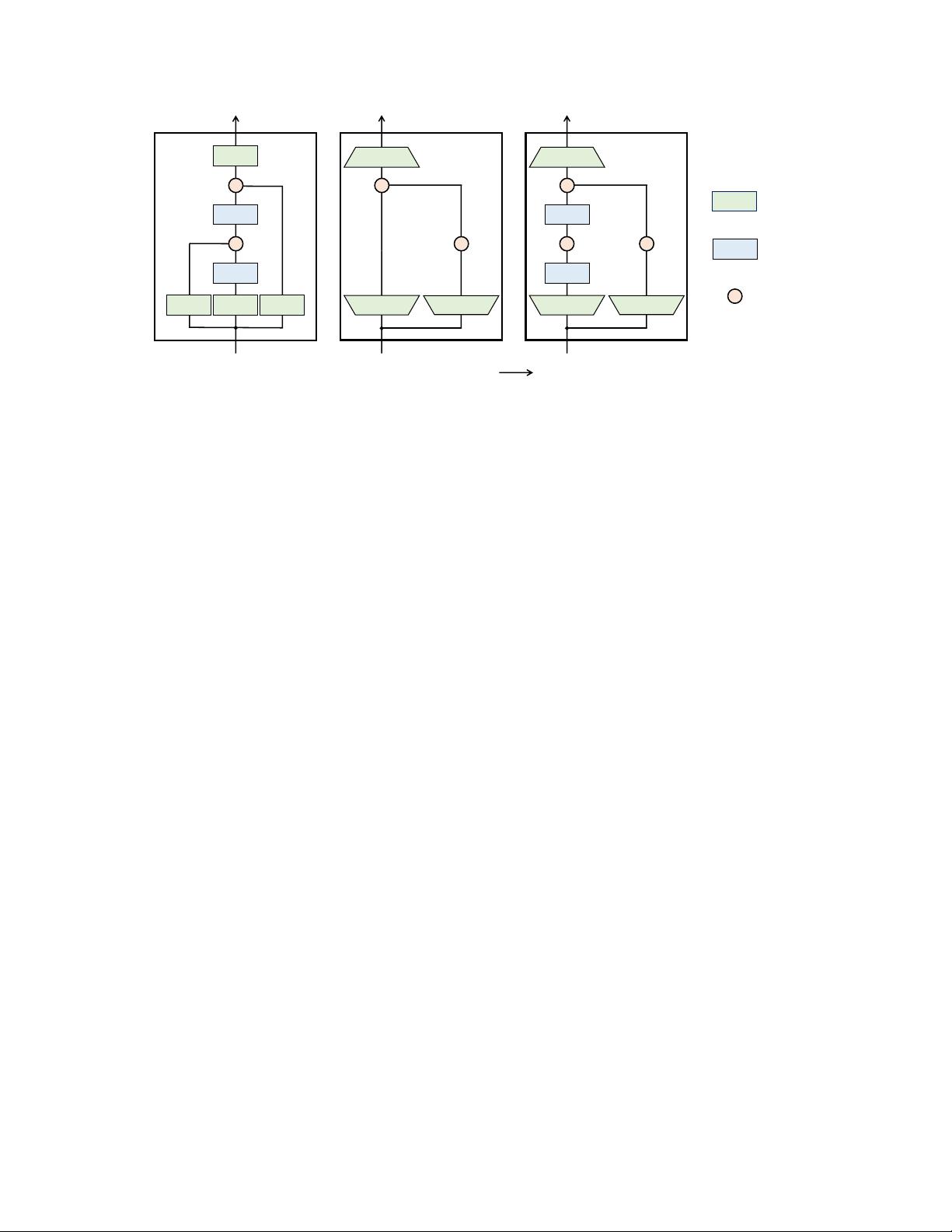
illustrated in Figure 1.
3.4 A Simplied SSM Architecture
As with structured SSMs, selective SSMs are standalone sequence transformations that can be flexibly incorporated
into neural networks. The H3 architecture is the basis for the most well-known SSM architectures (Section 2), which
are generally comprised of a block inspired by linear attention interleaved with an MLP (multi-layer perceptron)
block. We simplify this architecture by combining these two components into one, which is stacked homogenously
(Figure 3). This is inspired by the gated attention unit (GAU) (Hua et al. 2022), which did something similar for
attention.
This architecture involves expanding the model dimension
𝐷
by a controllable expansion factor
𝐸
. For each
block, most of the parameters (
3𝐸𝐷
2
) are in the linear projections (
2𝐸𝐷
2
for input projections,
𝐸𝐷
2
for output
projection) while the inner SSM contributes less. The number of SSM parameters (projections for
∆, B, C
, and
7
剩余36页未读,继续阅读
2025-02-20 上传
250 浏览量
329 浏览量
2022-04-20 上传
点击了解资源详情
点击了解资源详情

CS-Polaris
- 粉丝: 1052
 我的内容管理
展开
我的内容管理
展开







最新资源
- 昆仑通态MCGS嵌入版_XMTJ温度巡检仪软件包解压教程
- MultiBaC:掌握单次与多次组批处理校正技术
- 俄罗斯方块C/C++源代码及开发环境文件分享
- 打造Android跳动频谱显示应用
- VC++实现图片处理的小波变换方法
- 商城产品图片放大镜效果的实现与用户体验提升
- 全新发布:jQuery EasyUI 1.5.5中文API及开发工具包
- MATLAB卡尔曼滤波运动目标检测源代码及数据集
- DoxiePHP:一个PHP开发者的辅助工具
- 200mW 6MHz小功率调幅发射机设计与仿真
- SSD7课程练习10答案解析
- 机器人原理的MATLAB仿真实现
- Chromium 80.0.3958.0版本发布,Chrome工程版新功能体验
- Python实现的贵金属追踪工具Goldbug介绍
- Silverlight开源文件上传工具应用与介绍
- 简化瀑布流组件实现与应用示例
