虚拟机中构建Hadoop 2.7.3集群实战
需积分: 10 154 浏览量
更新于2024-07-18
收藏 13.41MB PPTX 举报
"本文档详细介绍了如何构建一个基于Hadoop的集群,涵盖了虚拟机环境的创建、克隆、配置,以及Linux基础操作和Hadoop生态系统中的相关组件版本。此外,还涉及了常用的Linux命令和虚拟机软件VMware Workstation的安装与使用。"
在构建Hadoop集群时,首先需要一个适合的环境。由于物理机可能不便于个人用户配置,通常会选择使用虚拟机。这里推荐使用VMware Workstation v9.0.1作为虚拟机平台,配合CentOS 6操作系统。为了构建集群,我们需要创建4个虚拟机:1个Master节点和3个Slave节点。Master节点上运行NameNode和JobTracker,负责管理数据分布和任务调度;而Slave节点则作为DataNode和TaskTracker,执行数据存储和任务处理。
在虚拟机的配置过程中,确保每个节点都能通过局域网相互连接。首先,需要安装JDK 1.8.0并设置环境变量,这是运行Hadoop所必需的。接着,安装Hadoop 2.7.3,这个版本是较稳定的选择。同时,为了实现节点间的无密码通信,需要配置SSH免密登录。在CentOS系统中,可以使用root或hadoop账号登录,并通过`ifconfig`命令检查每个节点的IP地址。
VMware Workstation的安装需要注意几个关键点:关闭主机的光驱自动运行功能,将软件安装在大容量的磁盘分区,以便未来分配更多的硬盘空间给虚拟机。此外,确保虚拟化技术在BIOS中被启用,这通常是防止启动时出现不支持64位虚拟机的问题。
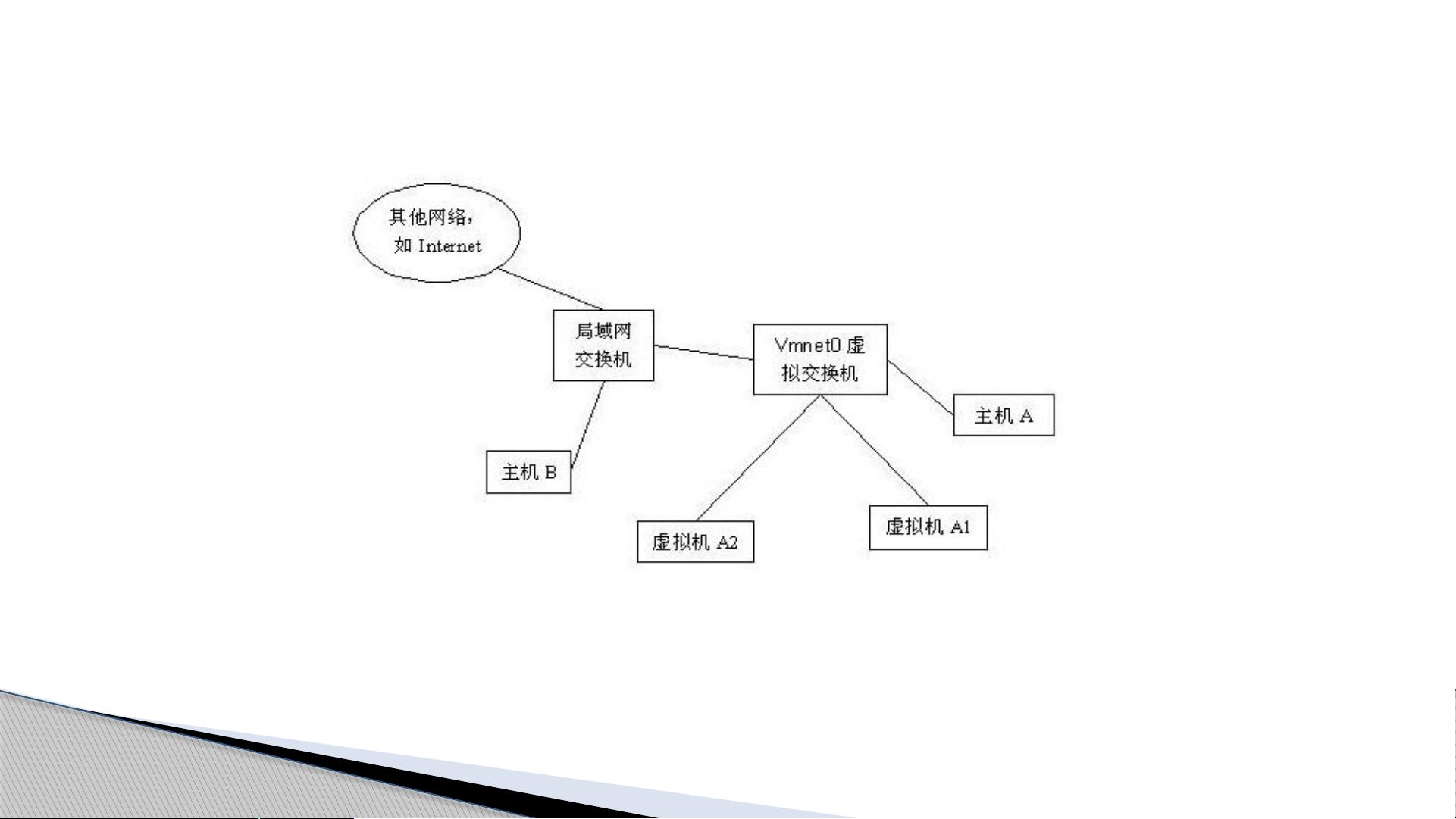
虚拟机的安装步骤包括下载CentOS 6.8的ISO镜像文件,然后在VMware中创建新的虚拟机,选择合适的硬件配置,如内存大小、CPU数量和网络适配器模式。虚拟机的网络配置应该设置为“桥接模式”,以便它们能直接接入物理网络。
Hadoop集群的搭建还需要其他组件,例如Zookeeper 3.4.10用于协调服务,HBase 1.2.4作为NoSQL数据库,Hive 2.1.1用于数据仓库和SQL查询,以及Spark 2.1.0结合Scala 2.11.8进行大数据处理。这些组件的安装和配置也需要遵循特定的步骤,例如修改配置文件,启动服务,并确保它们能与Hadoop集群无缝集成。
对于Linux基础操作,了解和熟练使用如`ls`, `cd`, `mkdir`, `rm`, `cp`, `mv`, `ssh`, `scp`, `vi/vim`等命令至关重要。PieTTY和WinSCP是Windows用户常用的远程连接和文件传输工具,分别用于SSH终端和SFTP文件管理。
构建Hadoop集群是一项涉及多方面技能的任务,包括虚拟化技术、Linux系统管理、网络配置以及大数据处理框架的安装和使用。通过逐步学习和实践,可以掌握这一过程,为大数据分析和处理提供坚实的基础。


2021-04-06 上传
2022-10-30 上传
点击了解资源详情
2024-11-08 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-01-01 上传
点击了解资源详情

roadlord
- 粉丝: 40
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- spring-data-orientdb:SpringData的OrientDB实现
- 施耐德PLC通讯样例.zip昆仑通态触摸屏案例编程源码资料下载
- Sort-Text-by-length-and-alphabetically:EKU的CSC 499作业1
- Resume
- amazon-corretto-crypto-provider:Amazon Corretto加密提供程序是通过标准JCAJCE接口公开的高性能加密实现的集合
- array-buffer-concat:连接数组缓冲区
- api-annotations
- 行业数据-20年春节期间(20年1月份24日-2月份9日)中国消费者线上购买生鲜食材平均每单价格调查.rar
- ex8Loops1
- react-travellers-trollies
- Bootcamp:2021年的训练营
- SpookyHashingAtADistance:纳米服务革命的突破口
- 蛇怪队
- address-semantic-search:基于TF-IDF余弦相似度的地址语义搜索解析匹配服务
- 摩尔斯键盘-项目开发
- Terraria_Macrocosm:空间
