使用jsoup优雅地处理HTML文档
"jsoup操作手册 API"
jsoup是一个强大的Java库,专用于解析HTML文档。它不仅能够解析HTML内容,还提供了高效且简便的API,使得开发者可以如同使用jQuery那样通过DOM和CSS选择器来查找和操作HTML数据。这个库是基于MIT协议发布的,因此可以在商业项目中自由使用。
**jsoup的主要功能:**
1. **解析HTML源**:jsoup可以从URL、文件或简单的字符串中获取HTML内容,转化为可操作的Document对象。
2. **选择和提取数据**:利用DOM解析器和CSS选择器,开发者可以方便地定位并提取HTML文档中的特定元素和数据。
3. **操作HTML元素和属性**:jsoup允许对HTML元素进行增删改查,包括修改属性值、添加或删除元素,以及处理文本内容。
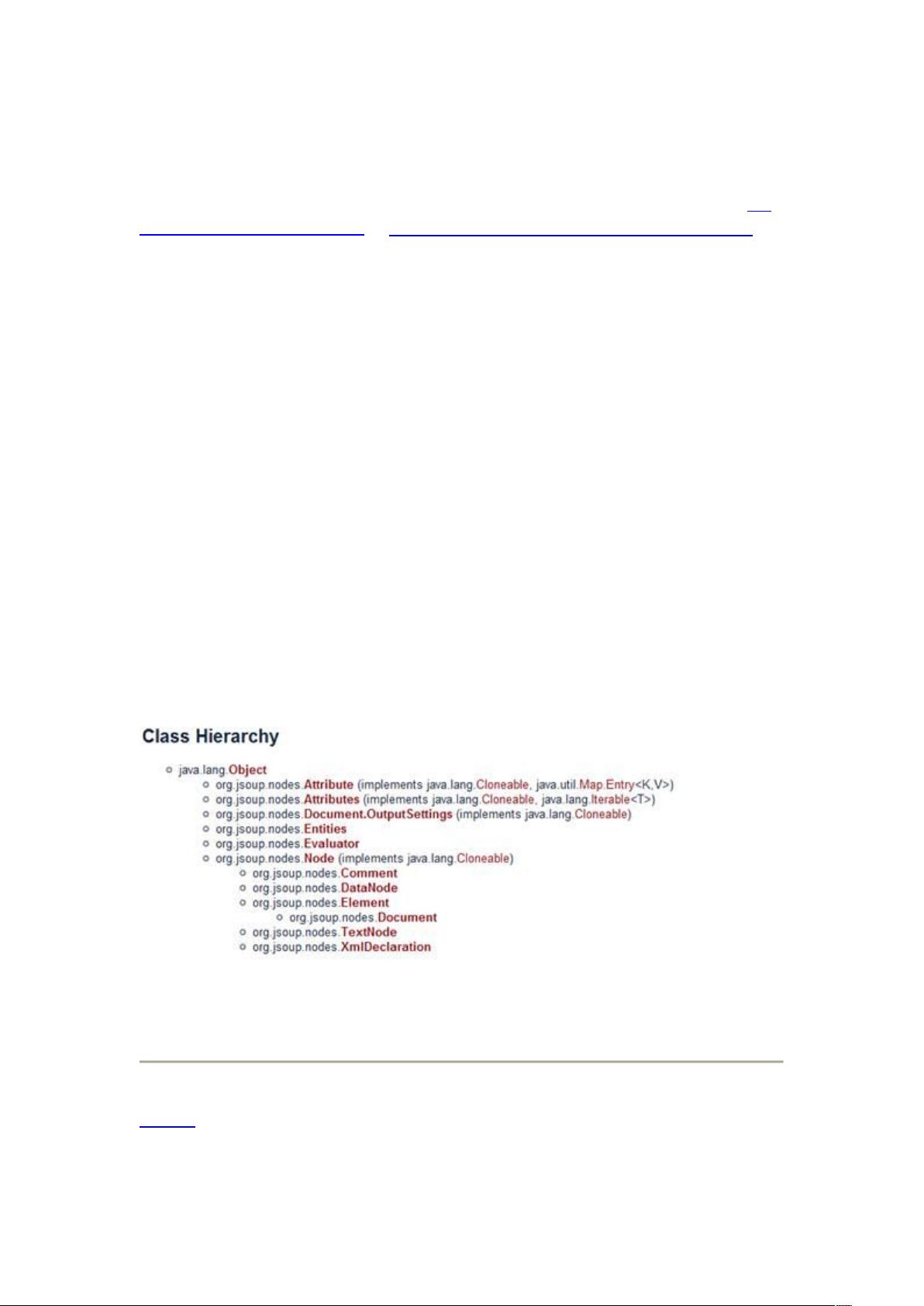
**主要类层次结构:**
jsoup的核心类包括Document、Element、Selector等,它们构成了jsoup强大的HTML处理框架。Document代表整个HTML文档,Element表示HTML元素,Selector则用于根据CSS选择器查找元素。
**文档输入示例:**
- **从字符串输入**:可以直接将HTML字符串传递给Jsoup.parse()方法,创建一个Document对象。
- **从URL加载**:使用Jsoup.connect()方法连接到指定URL,调用get()方法获取HTML内容。
- **设置请求参数**:可以添加请求参数(data()),设置User-Agent(userAgent())以及管理cookies(cookie())。
- **超时设置**:可以调整HTTP请求的超时时间(timeout())以适应不同的网络环境。
**常见应用场景:**
1. **网页抓取**:jsoup常用于从网页中抓取结构化数据,例如新闻标题、评论等。
2. **数据提取**:通过CSS选择器提取特定元素,如获取页面的标题、链接或图片。
3. **内容清洗**:jsoup可以去除HTML中的无效标签和内容,使数据更规范。
4. **网站自动化**:在自动化测试或脚本中,jsoup用于模拟用户交互,如点击按钮、填写表单等。
**使用示例:**
```java
// 解析HTML字符串
String html = "<html><head><title>示例页面</title></head><body><p>这是内容</p></body></html>";
Document doc = Jsoup.parse(html);
String title = doc.title(); // 获取标题:示例页面
// 从URL获取HTML
doc = Jsoup.connect("https://example.com").get();
Elements paragraphs = doc.select("p"); // 选择所有段落
for (Element p : paragraphs) {
System.out.println(p.text()); // 输出段落内容
}
```
jsoup是一个强大且易于使用的工具,它简化了HTML处理任务,使得Java开发者能更高效地处理网页数据。无论是在爬虫项目还是网页自动化场景中,jsoup都能发挥重要作用。
jsoup 简介
Java 程序在解析 HTML 文档时,相信大家都接触过 htmlparser 这个开源项
目,我曾经在 IBM DW 上发表过两篇关于 htmlparser 的文章,分别是:从
HTML 中攫取你所需的信息 和 扩展 HTMLParser 对自定义标签的处理能力 。
但现在我已经不再使用 htmlparser 了,原因是 htmlparser 很少更新,但最
重要的是有了 jsoup 。
jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文
本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于
jQuery 的操作方法来取出和操作数据。
jsoup 的主要功能如下:
1. 从一个 URL,文件或字符串中解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找、取出数据;
3. 可操作 HTML 元素、属性、文本;
jsoup 是基于 MIT 协议发布的,可放心使用于商业项目。
jsoup 的主要类层次结构如图 1 所示:
图 1. jsoup 的类层次结构
接下来我们专门针对几种常见的应用场景举例说明 jsoup 是如何优雅的进行
HTML 文档处理的。
回页首
文档输入
下载后可阅读完整内容,剩余7页未读,立即下载
2024-09-26 上传
2018-07-04 上传
2014-04-13 上传
点击了解资源详情

eraytzhang
- 粉丝: 0
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
