Python2字符编码与函数基础:解决中文乱码与解码技巧
80 浏览量
更新于2024-08-31
收藏 403KB PDF 举报
在Python编程中,字符编码和函数的基础使用是至关重要的,尤其是在处理文本数据时。本文主要针对Python 2版本中的特定问题进行讲解,因为在早期版本中,字符编码问题尤为显著。Python 2中默认使用GBK编码来解析IDE内的代码,但在命令行环境中,由于默认支持GBK,这导致了直接打印中文字符可能出现意外的正确输出。
首先,让我们明确Python2中的字符解码和编码过程。当你试图在命令行中使用非UTF-8编码的文本时,如果没有正确的声明,可能会出现乱码现象。例如,使用`msg="中国"`,如果不指定编码,直接`print msg`,可能会看到一堆难以识别的字符。这时,通过`decode`和`encode`函数可以实现编码和解码操作。例如:
```python
msg = "中国"
# 解码utf-8编码成Unicode,然后再编码成gbk
gbk_str = msg.decode('utf-8').encode('gbk')
print(gbk_str)
```
这段代码中,首先将UTF-8编码的字符串解码成Unicode,然后转换为GBK编码,目的是为了适应命令行环境默认的GBK字符集。尽管如此,这段代码的输出可能并不会像预期那样显示乱码,因为Python解释器在内存中默认使用Unicode,所以在解码过程中,它能理解并正确地处理UTF-8编码的文本。
值得注意的是,Python 2的这种行为并不是理想状态,因为它可能导致潜在的编码混淆。在现代Python开发中,推荐使用Python 3,它在处理字符串时更为清晰,直接支持Unicode,不再需要显式指定编码,使得跨平台和跨语言的文本处理更为便捷。因此,尽管本文介绍了Python 2中的字符编码技巧,但在实际项目中,使用Python 3及其内置的`str`对象(默认就是Unicode)通常更为明智。
总结来说,Python字符编码和函数的基础使用在Python 2中涉及到字符集转换、乱码处理以及内存中字符编码的默认行为。了解这些基础知识对于正确处理文本数据至关重要,尤其是在处理多语言和跨平台项目时。随着Python的发展,学习和掌握Python 3的相关编码规则和最佳实践是更长久且高效的选择。
Python字符编码与函数的基本使用方法字符编码与函数的基本使用方法
下面小编就为大家带来一篇Python字符编码与函数的基本使用方法。小编觉得挺不错的,现在就分享给大家,也给大家做个
参考。一起跟随小编过来看看吧
一、一、Python2中的字符存在的解码编码问题中的字符存在的解码编码问题
如果是现在正在用Python2的人应该都知道存在字符编码问题,就举一个最简单的例子吧:Python2是无法在命令行直接打印中文的,当然
他也是不会报错的,顶多是一堆你看不懂的乱码。如果想在直接显示中文,我们是可以在Python2文件头部申明字符编码的格式。如下图
这里 #-*-coding:utf-8 -*- 是用来申明下面的代码是用什么编码来解释;
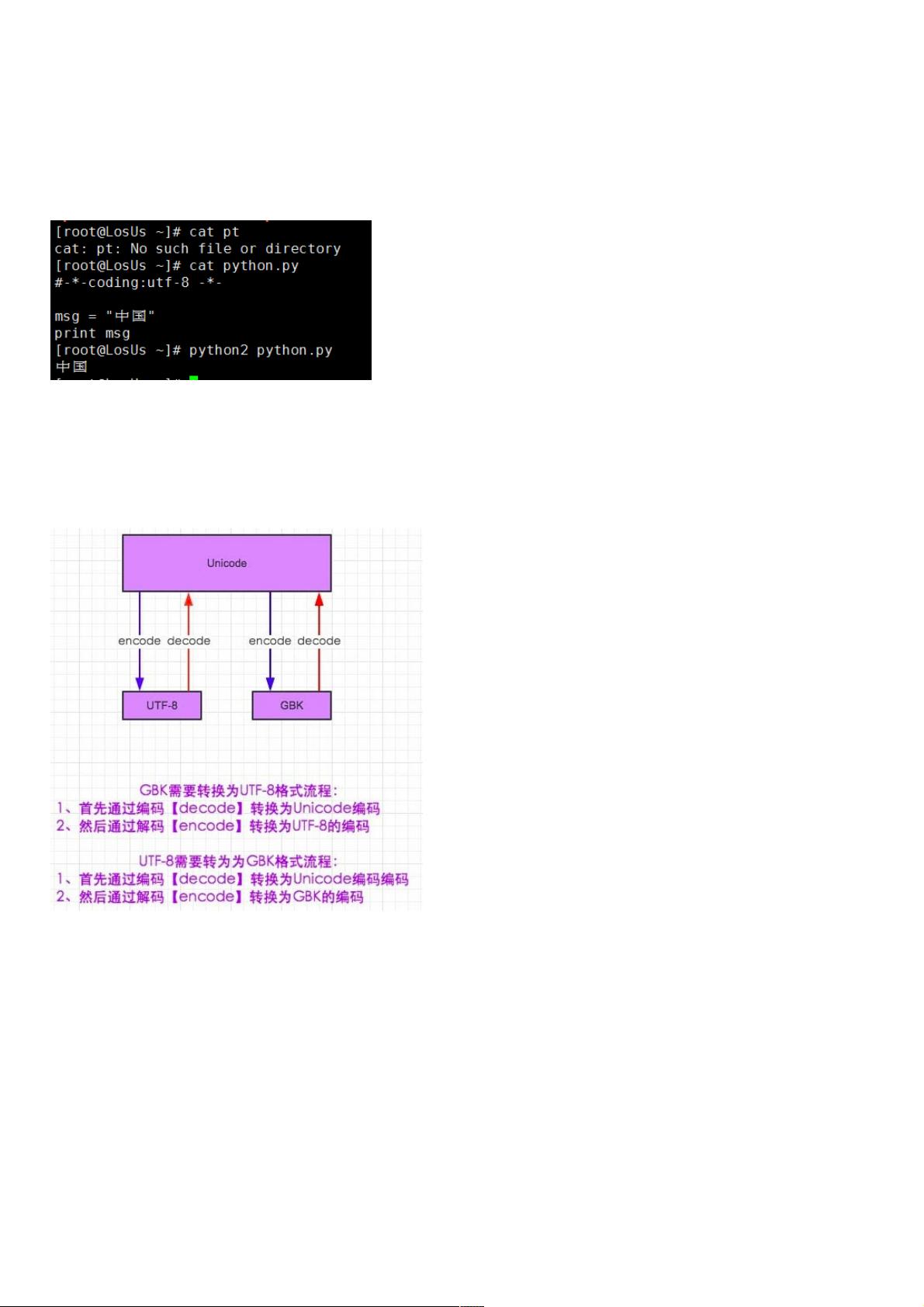
1.1.Python2中的解码和编码:中的解码和编码:
在编码和解码的世界中,我们得需要找一个大家都知道的文字。也可以这么理解。我是一个中国人现在和一个日本人沟通,我肯定是无法理
解他说的是什么,他同样也无法理解,但是这样就没有办法了吗?或许我们需要一个国际的语言——英语。这样来自不同国家的人也可以进
行沟通了(虽然我知道 are you ok 0-0)。在编码中也是一样,gbk和utf-8都不知道对方的格式是什么吊意思。所以如果要上gbk读懂utf-8的
编码就得将utf-8 decode成 Unicode,而Unicode有知道gkb,这里需要将Unicode在encode成gbk就行了
#-*- coding:utf-8 -*-
msg = "中国"
print msg
#解码在编码的过程,encoding是申明用申明这段代码是什么编码
gbk_str = msg.decode(encoding='utf-8').encode(encoding='gbk')
print gbk_str
#其实两种输出的结果是一样的
在Python2中默认是使用gbk来解释IDE中的代码的,所以无法直接在Python命令行中直接输入中文,所以我们才会使用 #-*-coding:utf-8 -*-
来申明头部,我们到底需要使用什么语言来解释下面代码。细心的人肯定是发现了一个问题,申明头部只是使用utf-8来解释下面的话,按理
说命令行中虽然不报错,但是应该也是乱码才是,这里为啥会直接输出中文呢毕竟DOS命令行中默认支持的是gbk格式的字符代码呀?这里
就涉及到另外的一个概念了。Python到内存解释器里面,默认是用的Unicode,文件加载到内存后自动解码成Unicode,而Unicode是外国
码,自然也就可以翻译来自utf-8的编码,也可以翻译成gbk的编码了。顾可以显示中文了。
PS:这里我们得出一个结论:python2 中解码动作是必须的,但是编码可以不用,因为内存就是中解码动作是必须的,但是编码可以不用,因为内存就是Unicode
1.2、、Python3中字符编码的问题:中字符编码的问题:
额,这还有什么可以说的呢?Python3默认就是使用utf-8解释代码的。也就是行首自带 #-*-coding:utf-8 -*-(GBM),所以也就不存在解码
下载后可阅读完整内容,剩余7页未读,立即下载
2020-08-18 上传
2019-07-19 上传
2021-01-20 上传
2020-09-24 上传
2020-12-25 上传
2021-09-15 上传
2020-12-22 上传
2020-12-26 上传
点击了解资源详情

weixin_38670700
- 粉丝: 1
- 资源: 917
 我的内容管理
展开
我的内容管理
展开







