
Generate to Adapt: Resolution Adaption Network for Surveillance Face
Recognition
Abstract
尽管深度学习技术已大大改善了人脸识别,但由于训练数据有限和域分布的差距,无约束的监视环境的人
脸识别仍然是一个尚未解决的挑战。先前的方法大多匹配不同域中的低分辨率和高分辨率人脸,这在普通
识别场景中往往会破坏原始特征空间。为避免此问题,我们提出了分辨率自适应网络(RAN),其中包含多
分辨率生成对抗网络(MR-GAN),然后是特征自适应网络。MR-GAN 学习多分辨率表示,并随机选择一种分
辨率以生成可避免下采样人脸产生伪影的逼真的低分辨率(LR)人脸。开发了一种新颖的带有翻译门的特
征自适应网络,将 LR 人脸的判别信息融合到骨干网络中,同时保留了原始人脸表示的判别能力。在 IJB-C
TinyFace,SCface 和 QMUL SurvFace 数据集上的实验结果证明,与常规的监视人脸识别方法相比,我们的
方法具有优越性,同时在常见的识别场景下表现出稳定的性能。
Introduction
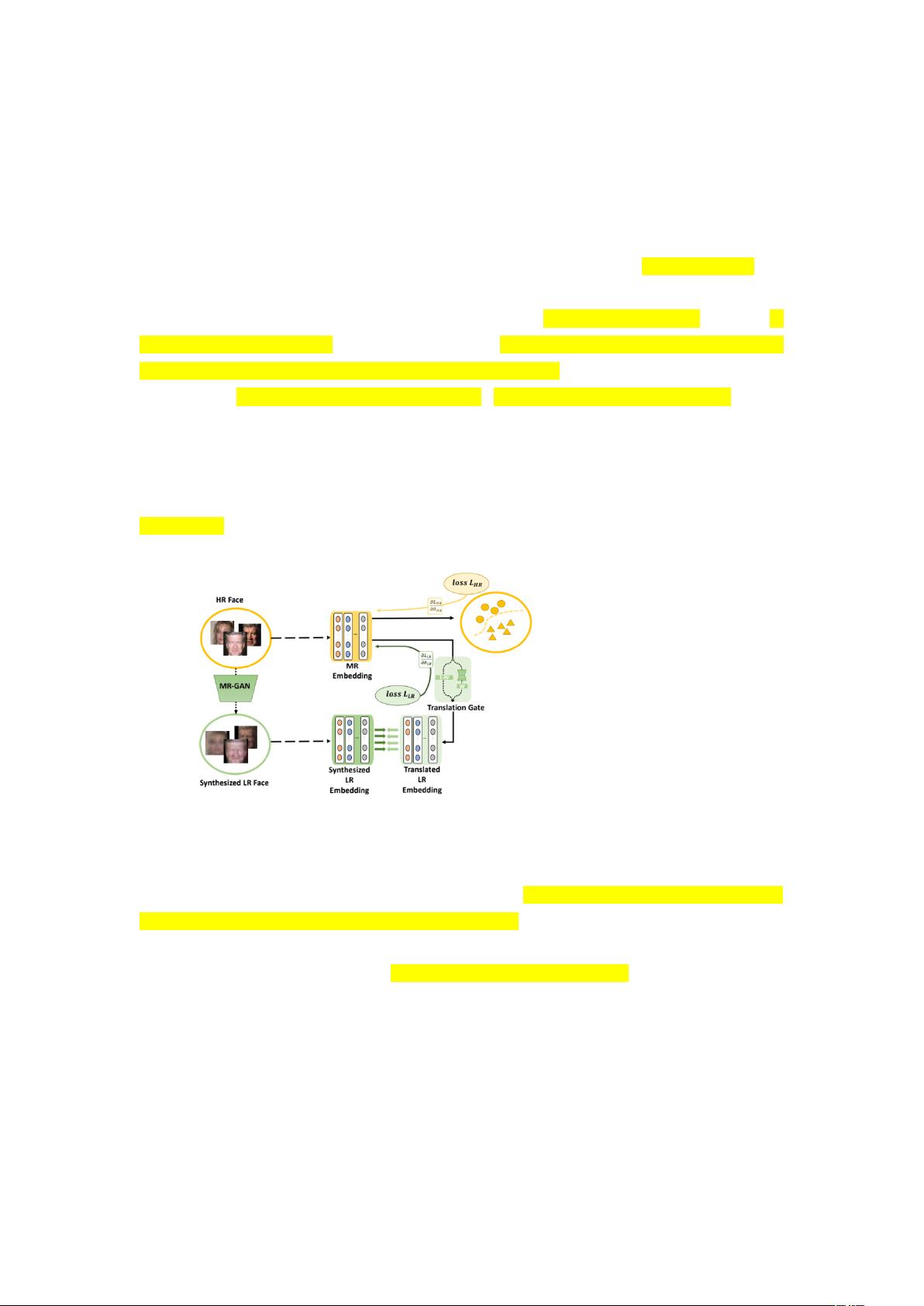
我们提出了一种新颖的分辨率适应网络(RAN),其中包括用于合成逼真的 LR 人脸的多分辨率生成对抗网
络(MR-GAN)。然后包括特征自适应网络,以逐步学习多分辨率(MR)知识。该框架如图 1 所示。与[3]不
同,它采用 GAN 生成 LR 图像作为中间步骤实现图像超分辨率。我们的 MR-GAN 旨在直接生成可在大型数据
集中进行增强的逼真的 LR 人脸,并提供先前的多分辨率表示。生成器采用全局和局部机制来关注不同的区
域。在生成器的全局流中,将输入人脸降采样为三个比例,然后传递以提取特定知识。然后,将多分辨率
表示逐渐组合并收敛到最低分辨率流中,以通过空间注意力获得精细的全局人脸。通过重复连接来自高分
辨率子编码器的信息来进行多分辨率融合,并且可以随机选择一种分辨率以细化现实的 LR 人脸。同时,使
用最低尺度人脸的局部区域来获得蒸馏区域,将其与全局人脸聚合以生成逼真的 LR 人脸。因此,可以使用
粗糙但仍具有判别力的人脸来提供低分辨率表示。
遵循生成适应的概念,我们提出了一种新颖的特征自适应网络来指导 HR 模型融合所生成的 LR 脸部的判别
信息,并保持 HR 脸部的稳定判别能力。 因此,可以防止通过强制拉近不同域的特征而引起的域移位问题。
具体来说,提出了翻译门以平衡翻译嵌入的来源并逐步保留 LR 表示。 为了使翻译后的 LR 嵌入和合成的 LR
下载后可阅读完整内容,剩余9页未读,立即下载

赵小杏儿
- 粉丝: 25
- 资源: 314
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


