Hive安装部署与运维实战指南
需积分: 12 118 浏览量
更新于2024-07-09
收藏 1.49MB PDF 举报
"04-Hive安装部署及运维使用.pdf"
Hive是一个基于Hadoop的数据仓库工具,它允许用户使用类SQL(HiveQL)语言来查询、管理和处理存储在HDFS(Hadoop Distributed File System)中的大数据集。Hive的设计目标是提供一个方便的、可扩展的和容错性强的系统,使得非Java背景的用户也能对大数据进行分析。Hive的核心特性包括:
1. 可扩展性:Hive能够轻松地扩展到更大的集群规模,而无需重启服务,这使得它能适应不断增长的数据量。
2. 延展性:Hive支持用户自定义函数(UDF),这意味着用户可以根据实际需求编写自己的函数,以处理特定的数据分析任务。
3. 容错性:Hive具有良好的容错机制,即使在节点出现故障的情况下,SQL查询也可以正常执行,确保了系统的稳定性。
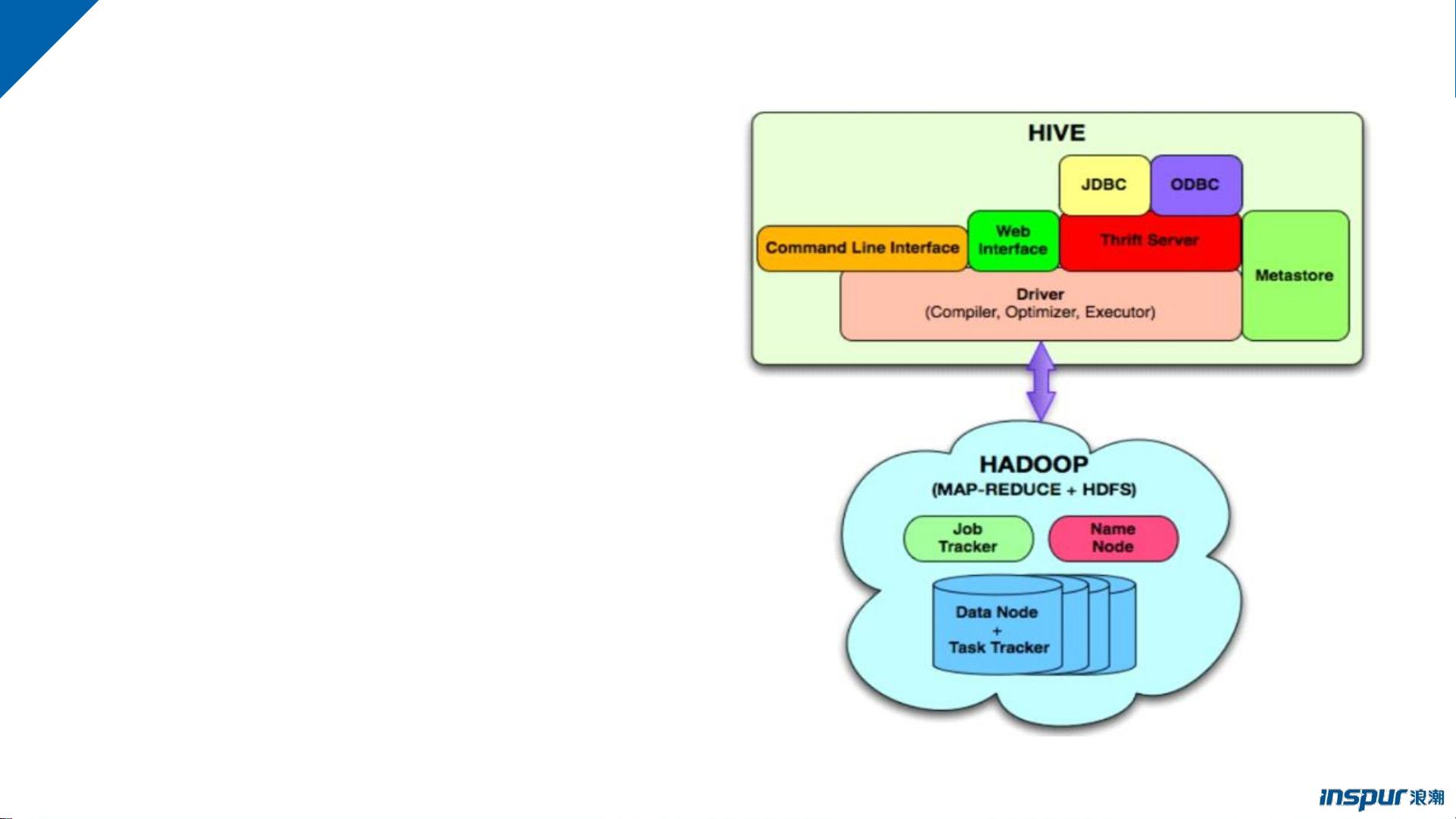
Hive的架构主要包括以下几个组件:
1. 用户接口:包括命令行接口(CLI)、JDBC/ODBC接口和WebGUI。CLI是通过命令行与Hive交互,JDBC/ODBC接口让Hive可以像传统数据库一样被Java应用程序访问,WebGUI则提供了浏览器访问Hive的界面。此外,ThriftServer允许不同编程语言通过Thrift协议调用Hive的接口。
2. 元数据存储:Hive的元数据通常存储在关系数据库中,如MySQL或PostgreSQL。元数据包含了表的定义、列信息、分区、属性以及数据所在的目录等。
3. 解释器、编译器、优化器和执行器:Hive查询首先经过词法分析、语法分析,然后被编译成一系列操作符,接着经过优化器进行优化,最后生成MapReduce或Spark任务执行计划,这些任务在Hadoop集群上运行。
4. 数据存储与计算:Hive将数据存储在HDFS上,大部分查询由MapReduce处理,但也有部分查询(如`SELECT * FROM table`)不会生成MapReduce任务。
在部署Hive时,需要注意以下几点:
1. HiveServer2高可用:为了保证服务的连续性,通常需要设置HiveServer2的高可用,这可能涉及复制元数据服务和负载均衡策略。
2. Hive客户端配置:用户需要正确配置Hive客户端,包括设置Hive服务器的地址、数据库连接信息以及相关安全认证参数。
运维方面,要关注Hive性能优化,如查询优化、元数据管理、日志监控、资源调度等,确保系统的高效运行。同时,定期备份元数据和监控Hadoop集群健康状态也是运维工作的重要组成部分。
Hive作为一个大数据处理工具,其强大的数据处理能力和灵活性使其成为大数据分析领域的重要选择。了解并掌握Hive的安装部署、运维使用以及其核心组件的工作原理,对于大数据工程师来说至关重要。
5
• 用户接口,包括CLI,Client,
WUI
• ThirftServer
• 元数据存储,通常是存储在关系数
据库如Mysql,Postgresql中
• 解释器、编译器、优化器、执行器
• Hadoop:用 HDFS 进行存储,利
用 MapReduce、Spark 进行计算
hive组成和架构
剩余20页未读,继续阅读
2022-06-22 上传
2022-06-10 上传
2022-06-20 上传
2018-11-07 上传
2022-05-31 上传
2021-12-10 上传
2023-08-30 上传
2019-11-18 上传
2022-12-24 上传

baidongd
- 粉丝: 4
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
