"这篇文章主要探讨了Elasticsearch与Spark之间的集成,主要集中在数据处理管道的构建、使用Spark Streaming作为推送到Elasticsearch的数据流,并介绍了如何优化查询Elasticsearch的方法。作者提到了Streaming Pro项目,这是一个方便将数据转换并推送到Elasticsearch的工具。此外,还讨论了通过优化引擎来提升查询性能的策略,如根据SQL分析选择操作和分片到分区以优化数据加载。"
在大数据处理和分析领域,Elasticsearch和Spark是两个非常关键的组件。Elasticsearch是一个实时的分布式搜索和分析引擎,而Spark则是一个用于大规模数据处理的快速、通用且可扩展的计算系统。两者的结合可以实现高效的数据处理、存储和查询。
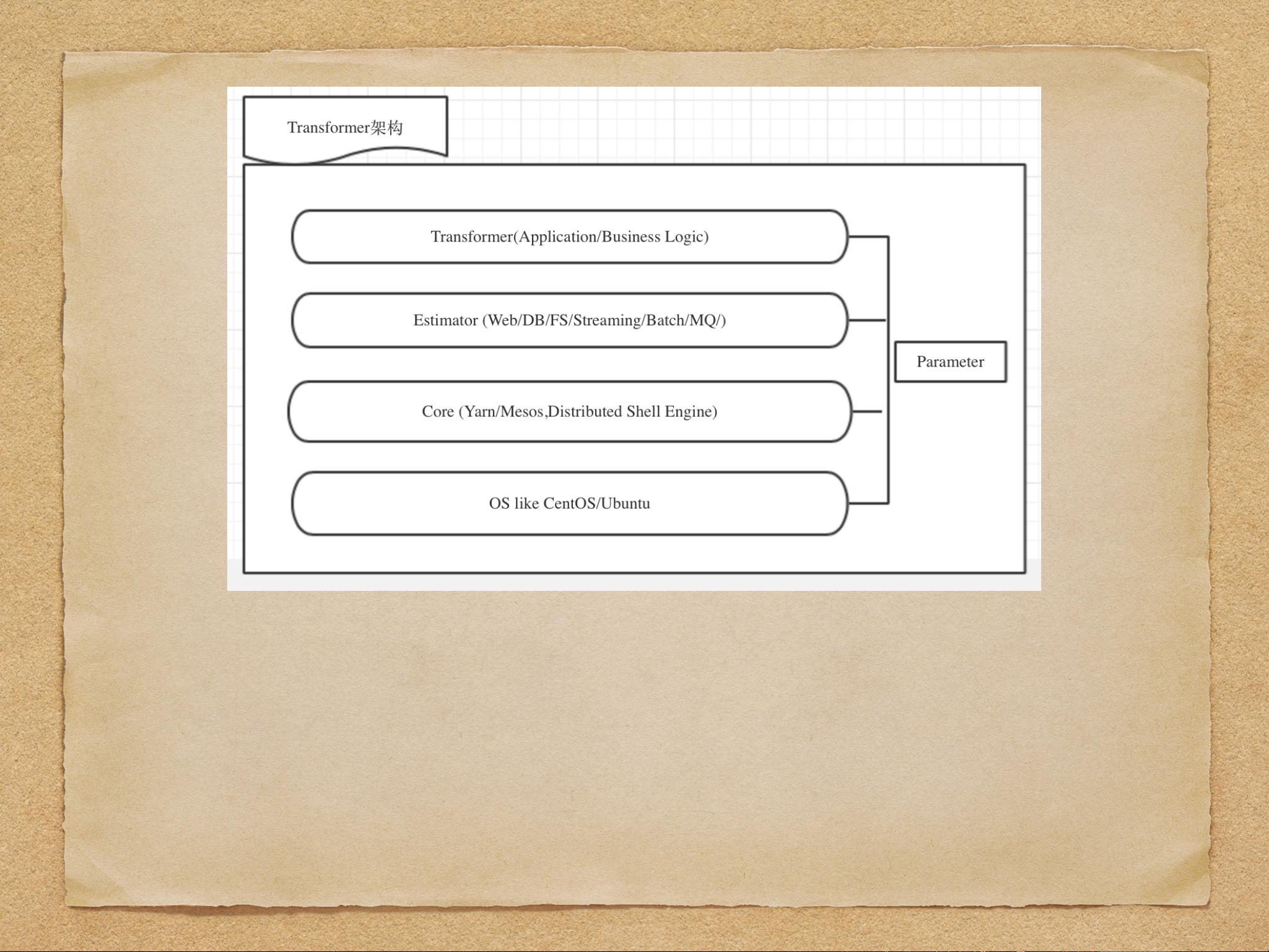
1. **Elasticsearch与Spark的集成**:
- 数据推送管道:在描述中提到,数据从源经过Transformator(转换器)到达Elasticsearch(ES)。首先,使用Spark Streaming作为数据推送的Estimator,因为它支持多种数据源,如Kafka、Socket、HDFS/S3、Kinesis/Twitter等。
- 使用Elasticsearch-hadoop项目,可以连接Spark Streaming和Elasticsearch,使得数据处理和存储变得更加流畅。
- Spark Streaming提供了强大的转换操作,允许用户编写SQL,串联操作,并提交任务。
2. **Streaming Pro项目**:
- 为了简化数据到Elasticsearch的转换和推送过程,作者创建了一个名为Streaming Pro的项目。这个项目的目标是使数据处理和存储更易于实现,详细信息可以在其GitHub页面上找到。
3. **查询Elasticsearch**:
- 直接基于SQL查询ES:用户可以直接基于Elasticsearch的SQL(es-sql)进行查询。
- 通过Spark的es-hadoop库从Spark查询ES:这允许用户利用Spark的强大计算能力来处理ES中的数据。
- 优化引擎结合:通过分析SQL,选择最佳的操作执行策略,同时可以通过分片到分区的方式优化从ES加载数据的效率。
4. **优化策略**:
- SQL分析:对SQL进行分析以确定执行的最佳行动,这是提高查询效率的关键步骤。
- 分片到分区:通过对ES的分片进行分区,可以优化从ES加载数据的过程,提高数据读取速度。
Elasticsearch与Spark的集成提供了强大的数据处理和分析能力,而Streaming Pro和优化策略则进一步提升了这种能力,使其成为大数据处理场景中的重要工具。对于处理实时数据流和高效查询的需求,这样的集成方案是十分有价值的。


 我的内容管理
展开
我的内容管理
展开









