"高扩展性数据科学:SparkR技术在藏经阁的应用"
需积分: 5 141 浏览量
更新于2024-03-15
收藏 662KB PDF 举报
In the document "Scalable Data Science with SparkR" by Felix Cheung, Principal Engineer at Microsoft, the focus is on the use of SparkR for scalable data analysis. SparkR is a powerful tool that combines the flexibility of R programming with the scalability and speed of Apache Spark.
Cheung begins by discussing the benefits of using SparkR for data analysis, including its ability to process large datasets efficiently and its integration with existing R libraries and tools. He then provides a detailed overview of the SparkR architecture, explaining how it leverages the distributed computing capabilities of Spark to handle big data analytics.
The document also covers various data science tasks that can be accomplished with SparkR, such as data manipulation, machine learning, and visualization. Cheung demonstrates how to use SparkR to perform common data science operations, such as data cleaning, transformation, and model building. He also provides examples of how SparkR can be used for more advanced machine learning tasks, such as clustering and regression analysis.
Cheung emphasizes the importance of scalability in data science, highlighting how SparkR enables users to analyze large datasets that would be impractical to process with traditional tools. He also discusses best practices for using SparkR in a production environment, such as optimizing code for performance and handling errors and exceptions effectively.
Overall, the document provides a comprehensive overview of SparkR and its applications in scalable data science. Cheung's expertise as a Principal Engineer at Microsoft shines through in the clear and concise explanations of complex concepts, making this document a valuable resource for data scientists looking to leverage SparkR for their analytics projects.
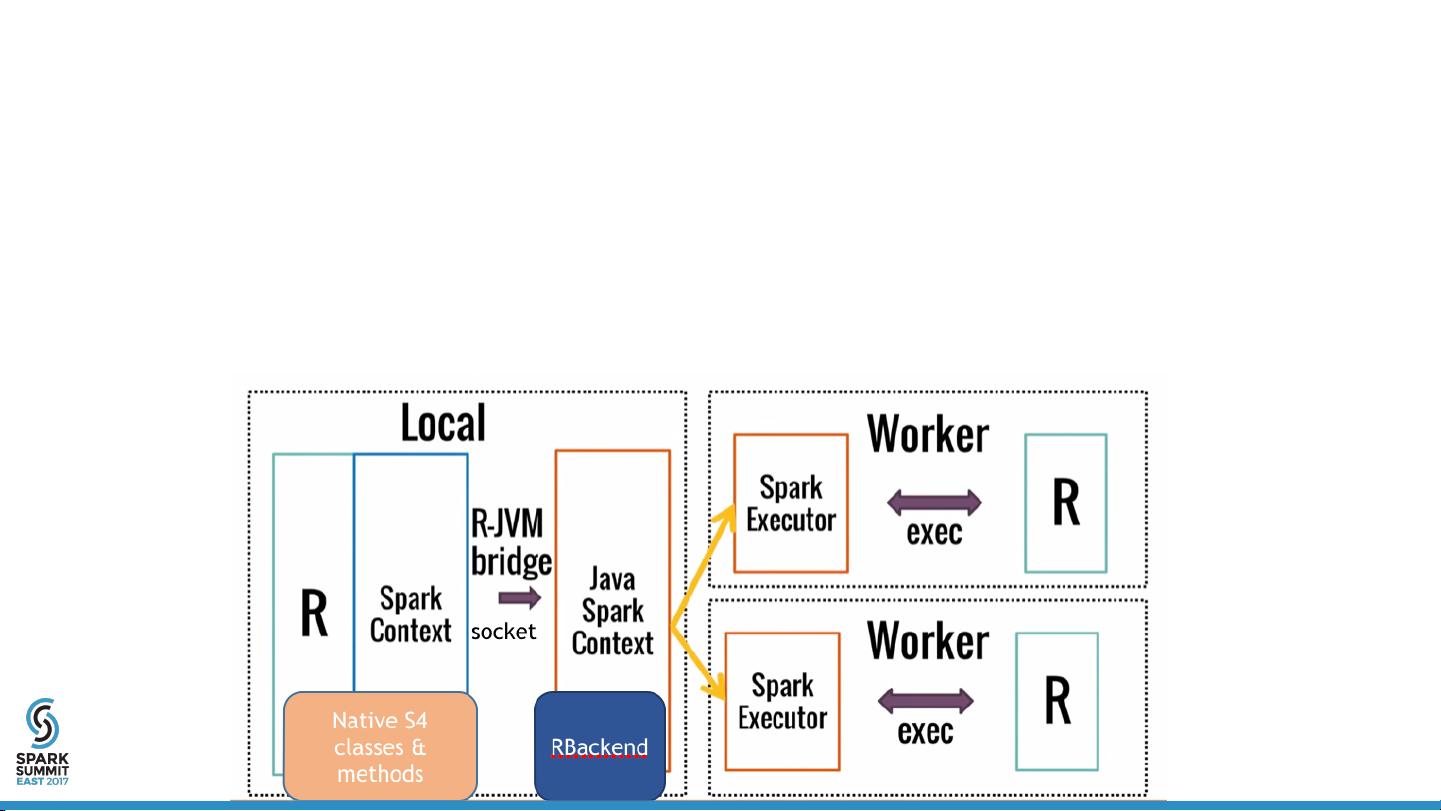
Architecture
•
Native R classes and methods
•
RBackend
•
Scala “helper” methods (ML pipeline etc.)
www.slideshare.net/SparkSummit/07-venkataraman-sun


剩余45页未读,继续阅读
2023-09-05 上传
2023-08-26 上传
2023-08-26 上传
2023-04-01 上传
2023-04-04 上传
2023-03-29 上传
2023-04-21 上传
2024-04-27 上传
2023-05-10 上传
2023-10-06 上传

weixin_40191861_zj
- 粉丝: 85
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
