均值漂移算法Mean-Shift详解与应用
"这篇资源是关于meanshift算法的个人总结,包括了算法的基本概念、发展历史、应用以及算法的推导。文中提到了meanShift算法的起源和在追踪领域的应用,以及如何通过迭代过程找到数据的密度峰值。"
Meanshift算法是一种无参数的聚类和追踪方法,它通过不断迭代寻找数据分布的局部峰值或高密度区域。最初由Fukunaga在1975年提出,早期仅是一个简单的统计概念,随着时间推移,其内涵得到了丰富和发展。
在Yizong Cheng于1995年的论文中,meanShift算法引入了核函数的概念,这意味着不同距离的样本点对均值偏移的贡献可以有所不同。此外,通过设定权重系数,可以考虑不同样本点的重要性,从而增强了算法的适应性和灵活性。这项改进使得meanShift算法在图像处理、物体追踪等领域得到了广泛应用,尤其是在实时追踪中表现突出。
Mean-shift算法的核心思想是一个向量从当前点移动到其周围数据点的加权平均位置,这个过程称为“向重心偏移”。算法通过反复迭代这一过程,最终会收敛到概率密度最高的区域,即数据的局部峰值。这个特性使得meanShift特别适合用于寻找数据集中的模式或集群。
算法的推导过程中,初始的偏移向量计算涉及到一个半径为h的高维球区域内的所有点。然而,原始公式中所有点的权重相等,这并不符合实际情况,因为靠近当前点的样本应具有更大的影响力。因此,引入了核函数,如高斯核,来解决这个问题。核函数能够根据样本点与当前点的距离给予不同的权重,距离越近的点权重越大,从而更准确地反映出数据的局部结构。
meanShift算法是一种强大的工具,尤其在处理高维数据和需要寻找密集区域的问题时。其优势在于无需预先确定簇的数量,且能自动适应数据的分布。尽管如此,算法的效率和准确性可能受到选择的窗口大小(h)和核函数类型的影响,需要根据具体问题进行调整。通过理解算法的原理和优化策略,我们可以更好地应用meanShift解决实际问题。
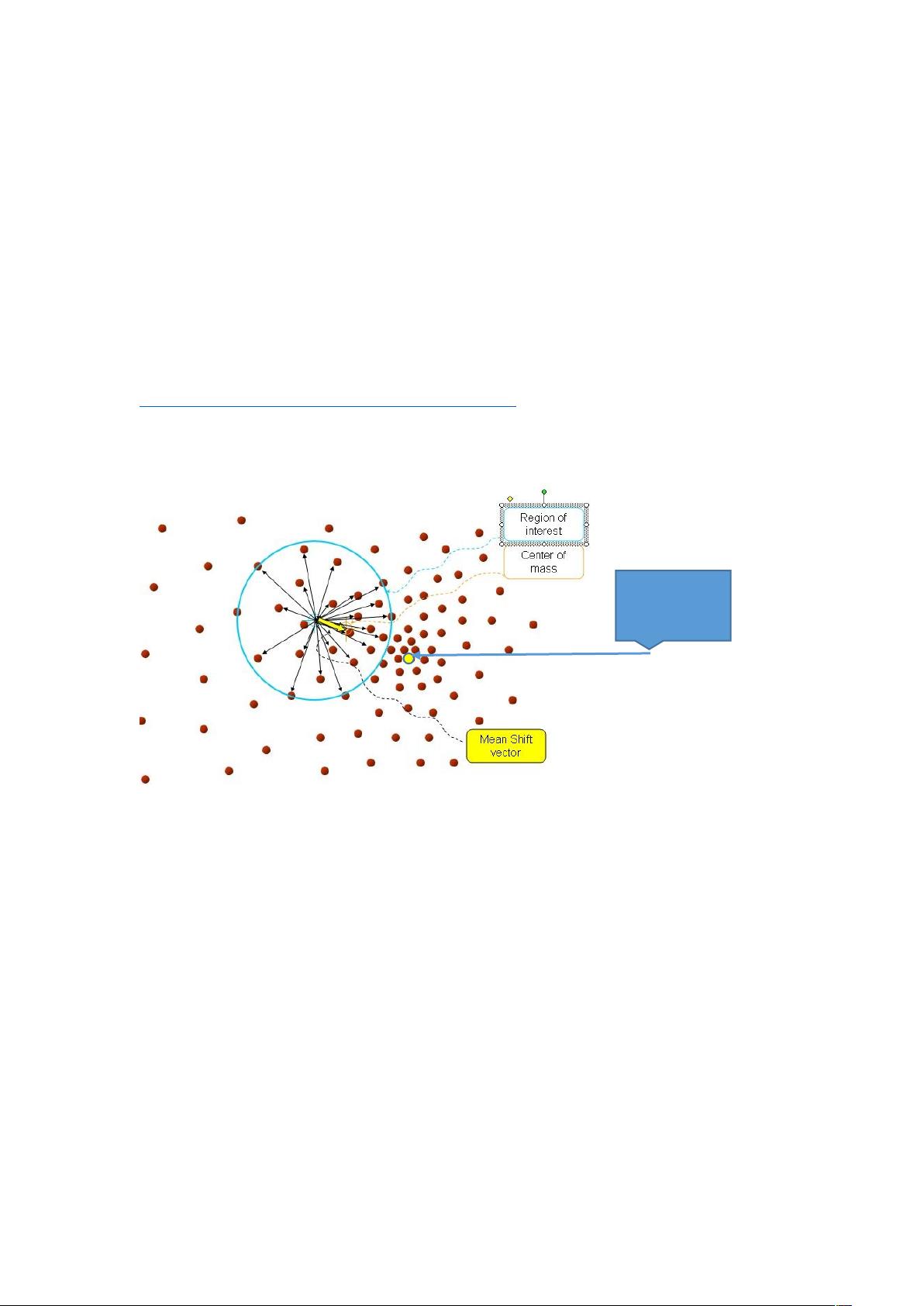
Mean-shi 即均值漂移算法。meanShi 这个概念最早是由 Fukunage 在 1975 年提出的,其
最初的含义正如其名:偏移的均值向量;但随着理论的发展,meanShi 的含义已经发生了
很多变化。如今,我们说的 meanShi 算法,一般是指一个迭代的步骤,即先算出当前点的
偏移均值,然后以此为新的起始点,继续移动,直到满足一定的结束条件。
在很长一段时间内,meanShi 算法都没有得到足够的重视,直到 1995 年另一篇重要论文
的发表。该论文的作者 Yizong Cheng 定义了一族核函数,使得随着样本与被偏移点的距离
不同,其偏移量对均值偏移向量的贡献也不同。其次,他还设定了一个权重系数,使得不
同样本点的重要性不一样,这大大扩展了 meanShi 的应用范围。此外,还有研究人员将非
刚体的跟踪问题近似为一个 meanShi 的最优化问题,使得跟踪可以实时进行。目前,利用
meanShi 进 行 跟 踪 已 经 相 当 成 熟 。 From
hp://blog.csdn.net/carson2005/ar&cle/details/7337432
Mean-shi 是一个向重心偏移的过程,一种快速寻找到最接近重心的地方,我感觉很类似
于一种最优化算法。
再以 meanshift 向量的终点为圆心,再做一个高维的球。如下图所以,重复以上步骤,
就可得到一个 meanshift 向量。如此重复下去,meanshift 算法可以收敛到概率密度
最大得地方。也就是最稠密的地方。
重心点
下载后可阅读完整内容,剩余8页未读,立即下载
305 浏览量
148 浏览量
2010-04-16 上传
140 浏览量
2009-05-12 上传
2010-03-26 上传
101 浏览量
2015-08-11 上传
2012-10-25 上传

wejoncy
- 粉丝: 68
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
