支持向量回归机(SVR)原理与应用
版权申诉
"(完整版)支持向量回归机.pdf"
支持向量回归机(Support Vector Regression,SVR)是机器学习领域中一种重要的预测模型,它源于最初的支持向量机(Support Vector Machine, SVM),主要应用于连续数值型数据的预测问题。与传统的SVM主要解决分类问题不同,SVR关注的是连续变量的回归分析,即寻找一个能够尽可能准确预测输出值的函数。
在SVR中,模型的目标不是寻找将样本分为两个类别的最大间隔超平面,而是构建一个能够使得所有样本点距离超平面的偏差总和最小的最优回归超平面。这个偏差被定义为ε不灵敏度,即模型允许的预测误差范围。当样本点的预测值与真实值的差距在这个范围内时,模型不会对其施加惩罚;超出这个范围,则会产生相应的惩罚。
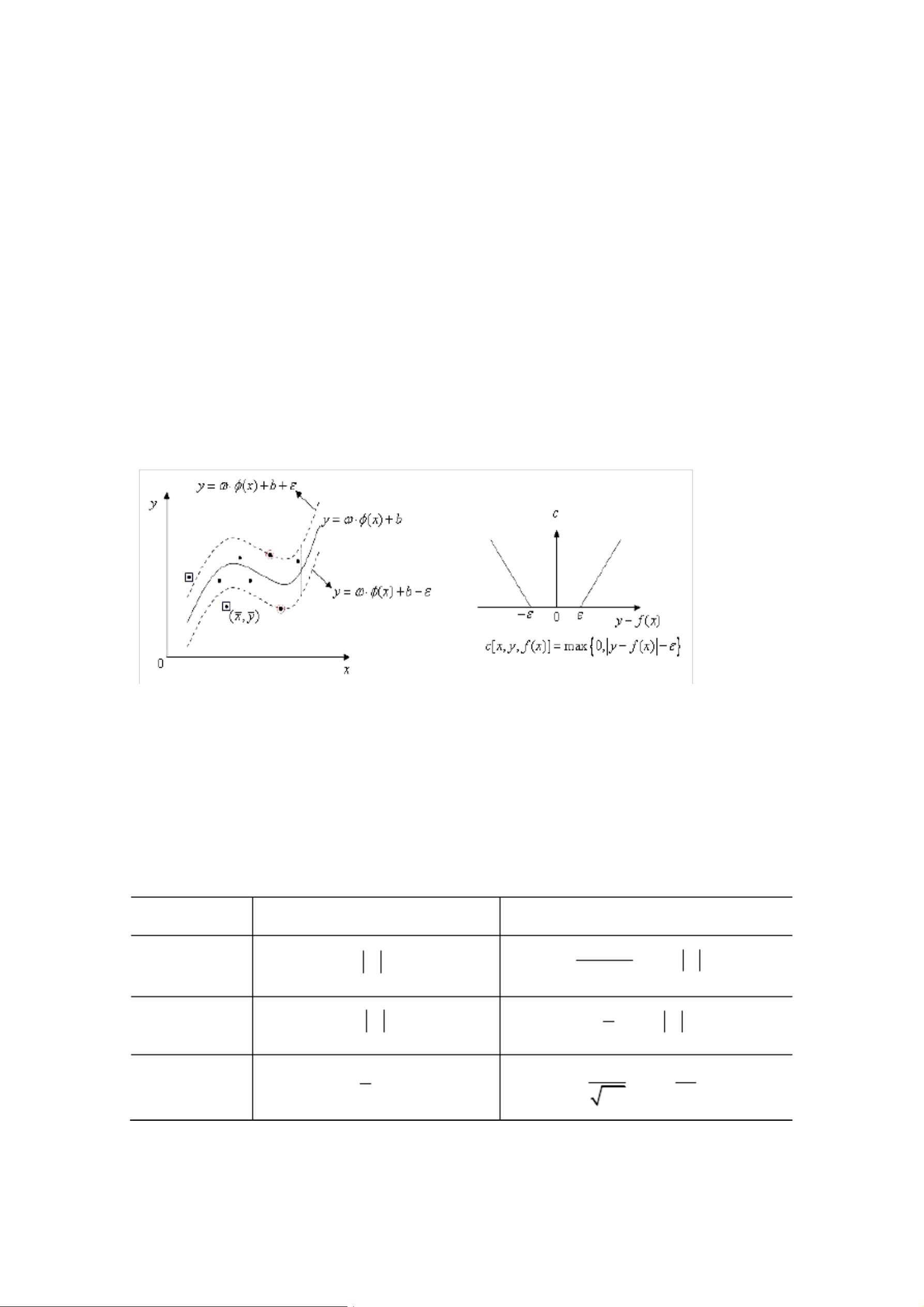
SVR的基本模型是通过线性回归函数f(x) = ω·x + b来拟合数据点 (x_i, y_i),其中x_i是输入特征,y_i是对应的输出值。模型参数ω和b需要通过优化算法来确定,以最小化总的误差。图3-3a展示了SVR的结构,其中ε是不灵敏度参数,用来控制模型对预测误差的容忍程度。
在训练过程中,SVR引入了惩罚函数来衡量模型的预测误差。惩罚函数的选择直接影响到模型的性能。表3-1列举了一些常用的损失函数及其对应的密度函数,例如ε-不敏感损失函数,拉普拉斯损失函数,高斯损失函数,鲁棒损失函数以及分段多项式损失函数等。这些函数在处理不同类型的数据分布和噪声时有不同的效果。
ε-不敏感损失函数是SVR的标准选择,它对误差小于ε的样本点不进行惩罚,而对大于ε的误差则按照线性比例进行惩罚。这种设计使得模型更加关注大误差的样本,从而避免了因小误差样本过多而导致的过拟合问题。
在实际应用中,通过调整ε和惩罚参数C,可以控制模型的复杂度和泛化能力。较小的ε值和较大的C值会使得模型更倾向于拟合数据,可能导致过拟合;相反,较大的ε值和较小的C值可能会导致模型过于简单,欠拟合数据。
SVR的优势在于它能够处理非线性问题,通过核函数变换将原始的低维输入空间映射到高维特征空间,从而可能在高维空间中找到线性的回归超平面。常用的核函数包括线性核、多项式核、径向基函数(RBF)核和sigmoid核等,它们能够处理各种复杂的数据关系。
支持向量回归机(SVR)是基于支持向量机理论的一种回归分析方法,通过ε-不灵敏度损失函数和合适的惩罚策略来寻找最优的回归超平面,能够在保证预测精度的同时,具备良好的泛化能力。在面对非线性和噪声较大的回归问题时,SVR表现出了强大的建模和预测能力。
3.3 支持向量回归机
SVM
本身是针对经典的二分类问题提出的,支持向量回归机(
Support Vector
Regression
,
SVR
)是支持向量在函数回归领域的应用。
SVR
与
SVM
分类有以
下不同:
SVM
回归的样本点只有一类,所寻求的最优超平面不是使两类样本点
分得“最开”,而是使所有样本点离超平面的“总偏差”最小。这时样本点都在
两条边界线之间,求最优回归超平面同样等价于求最大间隔。
3.3.1 SVR 基本模型
对 于 线 性 情 况 , 支 持 向 量 机 函 数 拟 合 首 先 考 虑 用 线 性 回 归 函 数
f (x)
x b
拟合
(x
i
, y
i
),i 1,2,..., n
,
x
i
R
n
为输入量,
y
i
R
为输出量,即
需要确定
和
b
。
图 3-3a SVR 结构图 图 3-3b
不灵敏度函数
惩罚函数是学习模型在学习过程中对误差的一种度量,一般在模型学习前己
经选定,不同的学习问题对应的损失函数一般也不同,同一学习问题选取不同的
损失函数得到的模型也不一样。常用的惩罚函数形式及密度函数如表
3-1
。
表 3-1 常用的损失函数和相应的密度函数
损失函数名称
%
(
i
)
损失函数表达式
c
噪声密度
p(
i
)
-不敏感
i
1
exp(
i
)
2(1
)
拉普拉斯
i
1
exp(
i
)
2
高斯
1
2
i
2
i
2
1
exp( )
2
2
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-10-29 上传
2022-11-28 上传
2022-11-26 上传
2018-11-19 上传
2022-06-22 上传
2022-06-22 上传

赵鲁宾
- 粉丝: 0
- 资源: 2908
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
