Anumita: 挖掘粗粒度推测并行性的框架
122 浏览量
更新于2024-07-14
收藏 857KB PDF 举报
"Exploiting Coarse-Grain Speculative Parallelism" 论文主要探讨了在现代计算机架构中利用粗粒度推测性并行执行(Coarse-Grain Speculative Parallelism)作为提高程序性能的编程模型。该模型允许在代码块、方法或算法级别进行推测性执行,以挖掘潜在的并行性。
作者Hari K. Pyla、Calvin Ribbens和Srinidhi Varadarajan来自弗吉尼亚理工学院的高端计算系统中心和计算机科学系。他们提出了一种名为Anumita的框架,该框架包括编程构造和一个支持运行时系统,目的是在不增加程序员复杂负担的情况下,利用粗粒度推测来提升程序性能。Anumita允许程序员在任意粒度上指定代理代码块(surrogate code blocks),这些代码块可以并发执行,最后只有一个赢家的结果会修改程序状态。
Anumita的关键特性在于其提供了丰富的胜者选择语义,这超越了简单的解决时间,还包含了用户自定义的解决方案质量概念。这意味着,不仅考虑哪个推测结果最先得出,而且可以根据预定义的质量标准选择最佳解。通过这种方式,Anumita能够对那些难以并行化的算法性能进行优化。
粗粒度推测并行执行与传统的细粒度推测执行相比,通常能更有效地利用硬件资源,因为它减少了推测状态的创建和管理开销。Anumita框架通过提供一种编程模型,使得程序员能够在不深入底层细节的情况下,利用这种并行性,从而有可能显著提升那些在现有架构下表现不佳的程序的效率。
论文中可能会详细讨论Anumita框架的具体实现,包括编程接口、推测执行的管理机制、并发控制策略以及如何处理错误推测(speculation failure)。此外,可能会通过实际案例研究或基准测试来展示Anumita在提升特定类型计算任务性能方面的效果,以证明其有效性和适用性。这样的技术对于推动软件开发适应多核和异构计算环境的发展具有重要意义。
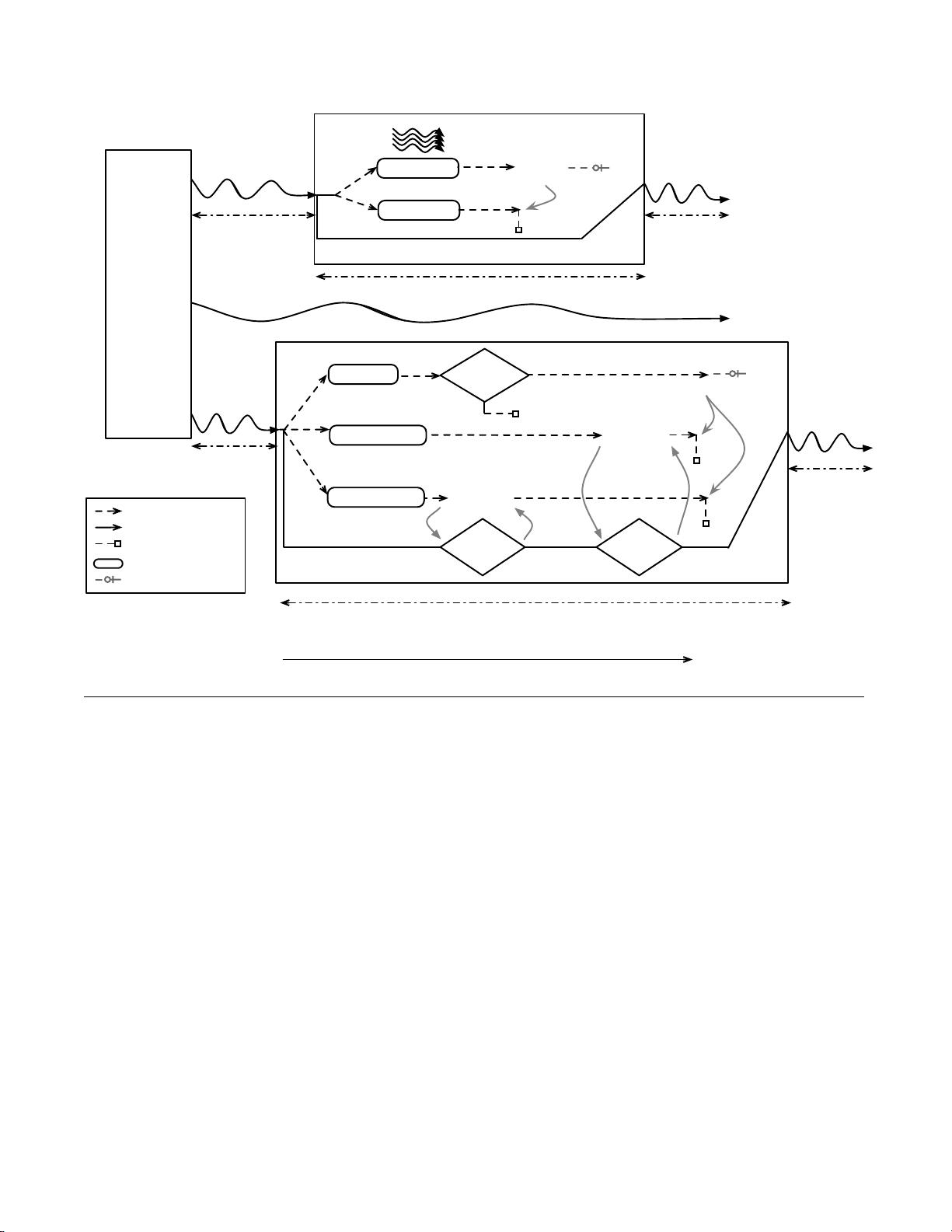
multi-threaded
application
thread-1
program execution
thread-2
begin
speculation
estimation
monte-carlo
0
1
commit
speculation
thread-2
resumes
from commit
cancel
speculation
thread-2 enters
evaluation context
multi-threaded
code block
non speculative
region
non speculative
region
evaluation
function
adaptive
conservative
extrapolation
0
1
2
begin
speculation
thread-0 enters
evaluation context
evaluate
speculation
area!=42
abort
speculation
thread-0
commit
speculation
cancel
speculation
speculative flow
abort speculative flow
non-speculative flow
surrogate
winning speculation
speculative region
speculative region
thread-0
resumes
from commit
non speculative
region
non speculative
region
evaluation
function
evaluate
speculation
Figure 1. A typical use case scenario for composing coarse-grain speculations. Anumita supports both sequential and multi-
threaded applications.
e.g., surrogate adaptive in the figure, when area != 42.
More generally, each surrogate may define success in terms
of an arbitrary user-defined evaluation function, passed to
an evaluation interface supplied by the parent flow (labeled
“evaluation context” in Figure 1). The evaluation context
safely maintains state that it can use to steer the composi-
tion, deciding which surrogates should continue and which
should terminate. In our example, surrogates conservative
and extrapolation use the evaluation interface to communi-
cate with their parent flow.
3.1 Program Correctness
Any concurrent programming model needs well-defined se-
mantics for propagation of memory updates. Anumita sup-
ports concurrency at three levels: (1) between surrogates in
a speculative composition, (2) between threads in a single
multithreaded surrogate, and (3) between threads in non-
speculative regions of an existing multithreaded application.
We consider each in turn.
Unlike the traditional threads model, where any conflict-
ing accesses to shared memory must be properly synchro-
nized, Anumita avoids synchronization and its associated
complexity by providing isolation among speculative flows
through privatization of the shared address space (global
data and heap). Furthermore, a copy of the stack frame of
the parent flow is passed to each speculative flow. Since up-
dates are isolated, “conflicting” accesses do not require syn-
chronization. Anumita’s commit construct implements a rel-
atively straightforward propagation rule: for a given com-
position, only the updates of a single winning speculative
flow are made visible to its parent flow at the completion
of a composition. Furthermore, compositions within a single
control flow are serialized, in that a control flow cannot start
a speculative composition without completing prior compo-
sitions in program order. Cumulatively, these two proper-
ties are sufficient to ensure program correctness in sequen-
tial applications (a single control flow) even in the presence
of nested speculations. We do not present a formal proof of
558
剩余18页未读,继续阅读
2007-11-05 上传
2015-11-16 上传
2021-02-10 上传
2022-01-02 上传
2007-07-04 上传
2021-02-08 上传
2021-02-08 上传
2021-02-08 上传
2022-01-23 上传

weixin_38722607
- 粉丝: 5
- 资源: 863
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
