Python操作Kafka:分布式流处理详解
53 浏览量
更新于2024-08-28
收藏 981KB PDF 举报
"本文主要介绍了Python操作分布式流处理系统Kafka的相关知识,包括Kafka的基本概念、核心组件以及其分布式架构。"
Kafka是一个高效、可扩展且容错的分布式流处理平台,允许数据生产者(Producer)发布消息,而数据消费者(Consumer)则能够订阅并消费这些消息。Kafka设计的目标是提供实时的数据处理能力,同时具备高吞吐量和低延迟的特点。
在Kafka中,数据存储的核心单位是`Topic`,它是一种逻辑上的分类或者频道,用户可以根据需要创建和配置。每个`Topic`可以被划分为多个`Partition`,这是一种水平扩展的方式,每个`Partition`是一个有序且不可变的消息队列。`Partition`内部的消息通过一个唯一的整数`Offset`来定位,它表示消息在`Partition`中的位置。
`Producer`是发布消息到Kafka集群的客户端程序,它可以选择将消息发送到特定的`Partition`,通常是基于消息的键值(key)进行哈希分区,或者使用轮询策略。如果消息没有键值,Kafka会自动进行负载均衡,将消息分发到各个`Partition`。
`Consumer`则是消息的使用者,它们属于一个或多个`Consumer Group`。在一个`Consumer Group`内,多个消费者协同工作,共同消费`Topic`中的消息。每个`Consumer`只处理一部分`Partition`中的消息,从而实现消息的并行消费。如果一个`Consumer`失败,其他组内的成员可以接管它的任务,保证了系统的容错性。
Kafka集群由多个`Broker`组成,每个`Broker`是Kafka服务器的一个实例,负责存储和转发消息。`Broker`之间通过复制保持数据的一致性,增强了系统的可用性和可靠性。
Kafka的分布式架构使得它能够在大型分布式环境中高效地工作,支持高并发和大数据量的处理。通过合理地设计`Partition`和`Consumer Group`,可以实现数据的均衡分布和高效的读写操作。在Python中,可以通过各种库,如`kafka-python`,方便地与Kafka进行交互,实现消息的生产和消费。
Python操作Kafka涉及到的知识点包括Kafka的基本概念、核心组件(Producer、Consumer、Topic、Partition、Broker、Consumer Group和Offset)以及其分布式架构的设计原理。掌握这些知识,开发者就能够有效地利用Kafka构建实时数据流处理系统,实现大规模数据的可靠传输和处理。
Python操作分布式流处理系统操作分布式流处理系统Kafka
什么是Kafka
Kafka是一个分布式流处理系统,流处理系统使它可以像消息队列一样publish或者subscribe消息,分布式提供了容错性,并发
处理消息的机制。
Kafka的基本概念
kafka运行在集群上,集群包含一个或多个服务器。kafka把消息存在topic中,每一条消息包含键值(key),值(value)和时
间戳(timestamp)。
kafka有以下一些基本概念:
Producer - 消息生产者,就是向kafka broker发消息的客户端。
Consumer - 消息消费者,是消息的使用方,负责消费Kafka服务器上的消息。
Topic - 主题,由用户定义并配置在Kafka服务器,用于建立Producer和Consumer之间的订阅关系。生产者发送消息到指定的
Topic下,消息者从这个Topic下消费消息。
Partition - 消息分区,一个topic可以分为多个 partition,每个
partition是一个有序的队列。partition中的每条消息都会被分配一个有序的
id(offset)。
Broker - 一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
Consumer Group - 消费者分组,用于归组同类消费者。每个consumer属于一个特定的consumer group,多个消费者可以共
同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也
被称为消费者集群。
Offset - 消息在partition中的偏移量。每一条消息在partition都有唯一的偏移量,消息者可以指定偏移量来指定要消费的消息。
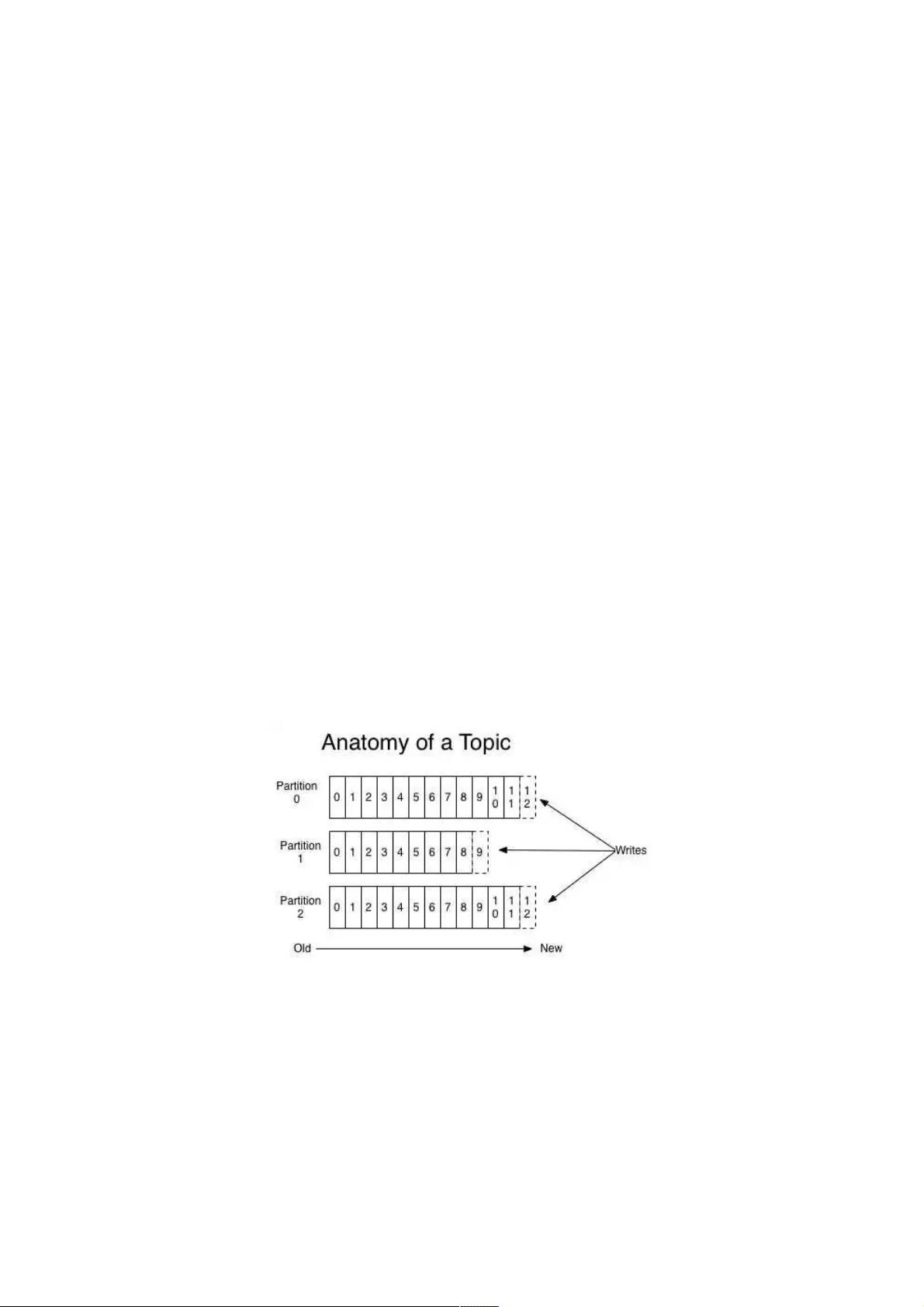
Kafka分布式架构
如上图所示,kafka将topic中的消息存在不同的partition中。如果存在键值(key),消息按照键值(key)做分类存在不同的
partiition中,如果不存在键值(key),消息按照轮询(Round Robin)机制存在不同的partition中。默认情况下,键值
(key)决定了一条消息会被存在哪个partition中。
partition中的消息序列是有序的消息序列。kafka在partition使用偏移量(offset)来指定消息的位置。一个topic的一个partition
只能被一个consumer group中的一个consumer消费,多个consumer消费同一个partition中的数据是不允许的,但是一个
consumer可以消费多个partition中的数据。
kafka将partition的数据复制到不同的broker,提供了partition数据的备份。每一个partition都有一个broker作为leader,若干个
broker作为follower。所有的数据读写都通过leader所在的服务器进行,并且leader在不同broker之间复制数据。
下载后可阅读完整内容,剩余7页未读,立即下载
2019-08-11 上传
2021-08-31 上传
2023-09-07 上传
2024-07-03 上传
2023-06-02 上传
2023-07-27 上传
2023-08-13 上传
2023-11-15 上传
2023-07-27 上传

冷月鱼
- 粉丝: 294
- 资源: 944
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
