深度学习与图神经网络综述
需积分: 31 68 浏览量
更新于2024-07-16
收藏 1.65MB PDF 举报
"这篇文档是关于图神经网络的综合调查,版本三,更新于2019年8月8日。作者包括Zonghan Wu、Shirui Pan、Fengwen Chen、Guodong Long、Chengqi Zhang以及Philip S. Yu,他们都是在机器学习领域有影响力的专家。文章探讨了深度学习如何在各种任务中取得突破,但同时也指出非欧几里得数据(如图数据)的处理是当前的一大挑战。作者们对现有的图神经网络(GNNs)进行了全面的概述,并提出了一种新的分类方法,将最新的GNN技术分为四个类别。"
正文:
图神经网络(GNNs)是近年来机器学习领域中的一个重要研究方向,特别是在处理非欧几里得结构数据,如社交网络、化学分子结构、交通网络等复杂关系数据时,GNNs展现出了强大的潜力。传统的深度学习模型主要针对欧几里得空间中的数据,如图像、语音和文本,而图数据则包含了对象之间的复杂关系和相互依赖,这使得传统算法在处理此类数据时遇到困难。
在这篇综合调查中,作者首先介绍了深度学习在图像分类、视频处理、语音识别和自然语言理解等领域取得的成功。然而,随着越来越多的应用涉及到图数据,例如社交网络分析、药物发现和推荐系统,需要新的学习方法来处理这些非结构化的数据。GNNs应运而生,它们能够对图中的节点和边进行建模,通过信息传播和聚合机制来学习节点的表示。
作者提出了一个新的分类框架,将GNNs分为四大类。第一类是基于消息传递的GNNs,这种类型的网络通过在图上迭代地传播和聚合邻居节点的信息来更新每个节点的特征表示。第二类是基于图卷积的GNNs,其灵感来源于卷积神经网络,但在图结构上进行卷积操作。第三类是基于图自编码器的GNNs,这类模型利用自编码器框架对图数据进行编码和解码,以实现节点嵌入学习或图重建。最后,第四类是基于图注意力网络的GNNs,它们引入了注意力机制,允许模型在不同节点之间分配不同的权重,以更灵活地捕捉图中的关键信息。
在讨论这些类别时,作者详细阐述了每种类型的关键技术和代表性模型,包括它们的工作原理、优缺点以及在实际应用中的表现。此外,还对GNNs在图分类、节点分类、链接预测等任务上的应用进行了深入分析,并指出了当前研究中的挑战和未来的研究方向,如可解释性、效率优化和图生成。
这篇综述为读者提供了全面了解图神经网络的窗口,不仅梳理了GNNs的发展历程,还为研究人员和实践者提供了深入理解和应用GNNs的宝贵资源。随着图数据的不断增长,GNNs的研究将继续推动机器学习领域的边界,为处理复杂网络问题提供更高效和精确的解决方案。
JOURNAL OF L
A
T
E
X CLASS FILES, VOL. XX, NO. XX, AUGUST 2019 5
Grap h
𝑋
𝑅𝑒𝐿𝑢 𝑅𝑒𝐿𝑢
Outputs
Gconv
…
Gconv
…
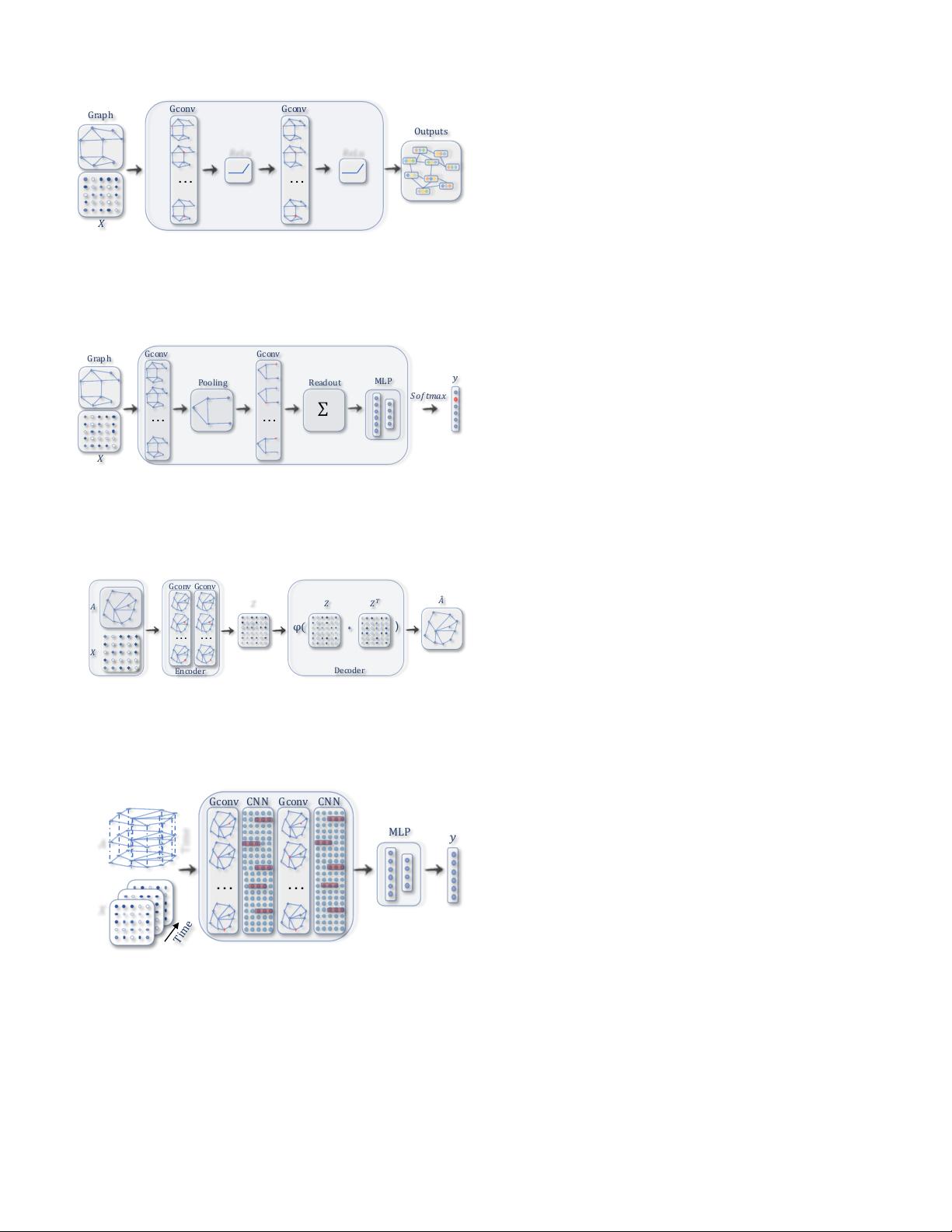
(a) A ConvGNN with multiple graph convolutional layers. A graph convo-
lutional layer encapsulates each node’s hidden representation by aggregating
feature information from its neighbors. After feature aggregation, a non-linear
transformation is applied to the resulted outputs. By stacking multiple layers,
the final hidden representation of each node receives messages from a further
neighborhood.
Gconv
Grap h
Readout
Gconv
Pooling
𝑆𝑜𝑓𝑡𝑚𝑎𝑥
𝑋
… …
MLP
𝑦
∑
(b) A ConvGNN with pooling and readout layers for graph classification
[21]. A graph convolutional layer is followed by a pooling layer to coarsen
a graph into sub-graphs so that node representations on coarsened graphs
represent higher graph-level representations. A readout layer summarizes the
final graph representation by taking the sum/mean of hidden representations
of sub-graphs.
𝑍"
φ(
𝑍
%
𝑍
∗
)
𝐴
𝑋
𝐴
)
Decode r
Encoder
…
Gconv"Gconv
…
(c) A GAE for network embedding [61]. The encoder uses graph convolutional
layers to get a network embedding for each node. The decoder computes the
pair-wise distance given network embeddings. After applying a non-linear
activation function, the decoder reconstructs the graph adjacency matrix. The
network is trained by minimizing the discrepancy between the real adjacency
matrix and the reconstructed adjacency matrix.
𝐴
𝑋
Time
'''Gconv'''CNN''''Gconv ''''CNN
… …
MLP
𝑦
Time
(d) A STGNN for spatial-temporal graph forecasting [74]. A graph convolu-
tional layer is followed by a 1D-CNN layer. The graph convolutional layer
operates on A and X
(t)
to capture the spatial dependency, while the 1D-CNN
layer slides over X along the time axis to capture the temporal dependency.
The output layer is a linear transformation, generating a prediction for each
node, such as its future value at the next time step.
Fig. 2: Different Graph Neural Network Models built with
graph convolutional layers. The term Gconv denotes a graph
convolutional layer (e.g., GCN [22]). The term MLP denotes
multilayer perceptrons. The term CNN denotes a standard
convolutional layer.
latent representation upon which a decoder is used to re-
construct the graph structure [61], [62]. Another popular
way is to utilize the negative sampling approach which
samples a portion of node pairs as negative pairs while
existing node pairs with links in the graphs are positive
pairs. Then a logistic regression layer is applied after the
convolutional layers for end-to-end learning [42].
In Table III, we summarize the main characteristics of
representative RecGNNs and ConvGNNs. Input sources, pool-
ing layers, readout layers, and time complexity are compared
among various models.
IV. RECURRENT GRAPH NEURAL NETWORKS
Recurrent graph neural networks (RecGNNs) are mostly pi-
oneer works of GNNs. They apply the same set of parameters
recurrently over nodes in a graph to extract high-level node
representations. Constrained by computation power, earlier
research mainly focused on directed acyclic graphs [13], [80].
Graph Neural Network (GNN*
2
) proposed by Scarselli et
al. extends prior recurrent models to handle general types of
graphs, e.g., acyclic, cyclic, directed, and undirected graphs
[15]. Based on an information diffusion mechanism, GNN*
updates nodes’ states by exchanging neighborhood information
recurrently until a stable equilibrium is reached. A node’s
hidden state is recurrently updated by
h
(t)
v
=
X
u∈N(v)
f(x
v
, x
e
(v,u)
, x
u
, h
(t−1)
u
), (1)
where f(·) is a parametric function, and h
(0)
v
is initialized
randomly. The sum operation enables GNN* to be applicable
to all nodes, even if the number of neighbors differs and no
neighborhood ordering is known. To ensure convergence, the
recurrent function f(·) must be a contraction mapping, which
shrinks the distance between two points after mapping. In the
case of f(·) being a neural network, a penalty term has to
be imposed on the Jacobian matrix of parameters. When a
convergence criterion is satisfied, the last step node hidden
states are forwarded to a readout layer. GNN* alternates the
stage of node state propagation and the stage of parameter
gradient computation to minimize a training objective. This
strategy enables GNN* to handle cyclic graphs. In follow-up
works, Graph Echo State Network (GraphESN) [16] extends
echo state networks to improve efficiency. GraphESN consists
of an encoder and an output layer. The encoder is randomly
initialized and requires no training. It implements a contractive
state transition function to recurrently update node states until
the global graph state reaches convergence. Afterward, the
output layer is trained by taking the fixed node states as inputs.
Gated Graph Neural Network (GGNN) [17] employs a gated
recurrent unit (GRU) [81] as a recurrent function, reducing the
recurrence to a fixed number of steps. The advantage is that it
no longer needs to constrain parameters to ensure convergence.
2
As GNN is used to represent broad graph neural networks in the survey,
we name this particular method GNN* to avoid ambiguity.
剩余21页未读,继续阅读
2019-08-22 上传
2020-02-27 上传
2022-02-14 上传
2021-08-25 上传
2019-10-29 上传
2019-09-03 上传
2023-03-16 上传
2020-03-29 上传
2022-04-19 上传

不务正业的土豆
- 粉丝: 1812
- 资源: 47
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
