迁移学习在细粒度实体分类中的应用与挑战
版权申诉
80 浏览量
更新于2024-06-27
收藏 529KB DOCX 举报
"基于迁移学习的细粒度实体分类方法的研究"
本文主要探讨了命名实体识别(Named Entity Recognition, NER)这一自然语言处理(Natural Language Processing, NLP)领域的核心任务,它涉及到识别文本中的特定实体并将其分类到预定义的类别中。NER对于信息抽取、信息检索、机器翻译、问答系统等NLP应用至关重要。
命名实体识别分为两部分:实体识别和实体类型分类。早期的NER方法主要包括基于规则的方法,这种方法依赖于人工构造规则,虽然性能较好,但需要大量的领域专业知识,且移植性较差。其次是基于传统机器学习的方法,如HMM、ME和CRF等序列标注模型,这些方法对语料库的依赖较大,而可用的大规模通用语料库相对较少。
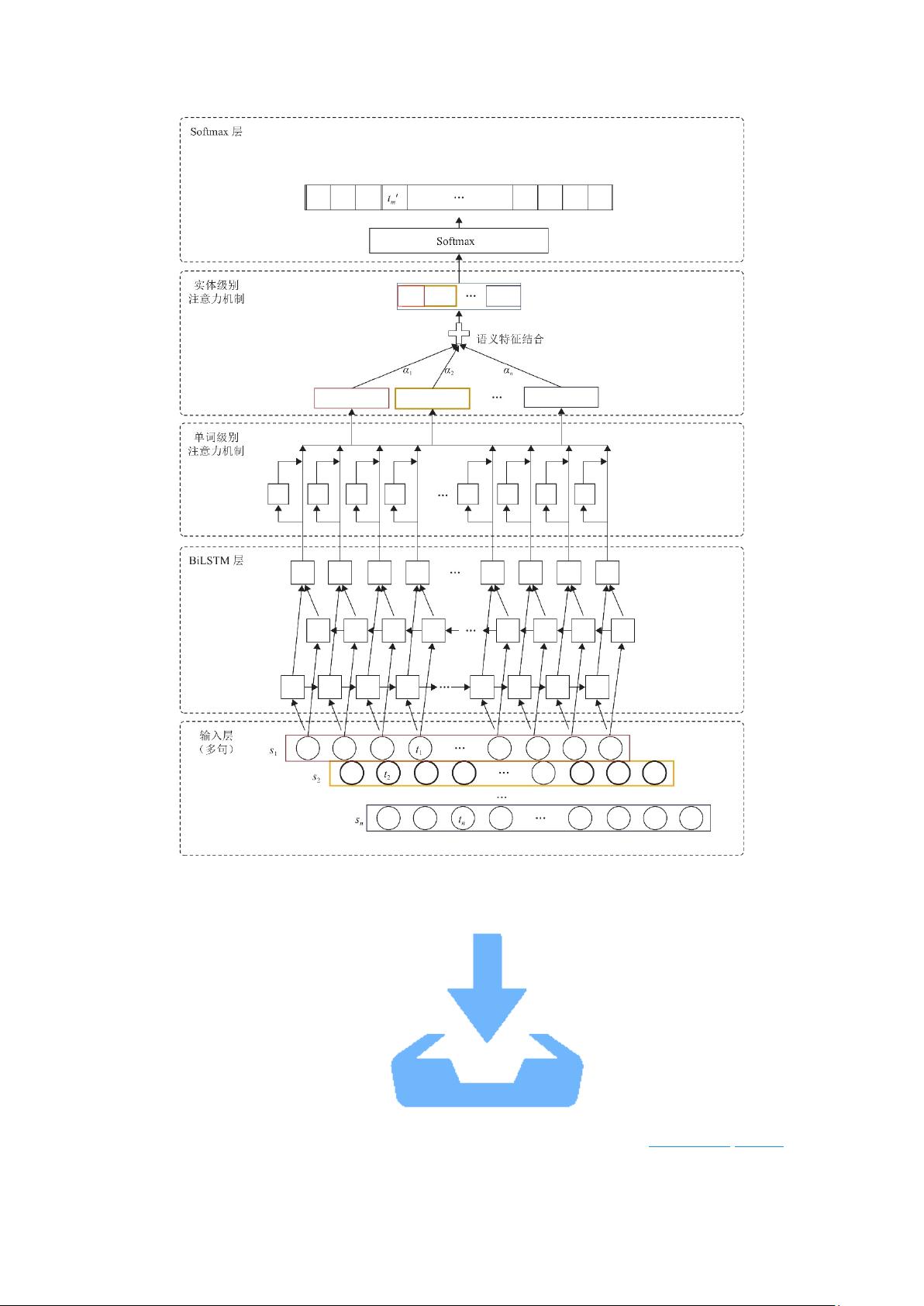
近年来,随着深度学习的兴起,NER的研究重点转向了使用深度学习模型,例如BiLSTM模型,通过双向长短期记忆网络捕获上下文信息,显著提升了NER的性能。随后,结合CRF的BiLSTM、CNN+BiLSTM+CRF以及引入注意力机制的CNN+Attention+Bi-LSTM+CRF等复合模型相继出现,进一步优化了结果。不过,这些深度学习模型同样属于有监督学习,需要大量标注数据支持。
此外,针对有监督学习对标注数据的高需求,半监督和无监督学习方法也在NER任务中得到应用。半监督学习利用少量标注数据作为种子集,通过迭代从大量未标注数据中扩展知识。BootStrapping是半监督学习的一种主要技术,通过不断迭代提升模型的识别能力。
迁移学习作为一种有效的学习策略,也被引入到细粒度实体分类中。它利用预训练模型(如BERT、ELECTRA等)在大规模数据集上的知识,迁移到目标任务,减少对特定任务标注数据的依赖,提高模型的泛化能力。这种迁移学习的方法在处理细粒度实体分类时,能捕捉到更微妙的实体特征,特别是在处理罕见实体和多义词时表现出优势。
NER研究经历了从基于规则到基于统计,再到基于深度学习的发展,当前的挑战在于如何在有限的标注数据下提升模型性能,并利用迁移学习等技术解决小样本和细粒度分类问题。未来的研究可能还会探索无监督或弱监督学习,以及如何更好地融合领域知识和上下文信息,以实现更加精准的实体识别。
剩余15页未读,继续阅读
2022-12-15 上传

罗伯特之技术屋
- 粉丝: 4494
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







