分布式Web爬虫系统:原理、策略与实现
版权申诉
156 浏览量
更新于2024-07-02
收藏 1.2MB PDF 举报
"分布式Web Crawler系统研究与实现.pdf"
这篇文档主要探讨了分布式Web Crawler系统的各个方面,从搜索引擎的基本理论到爬虫系统的核心技术,再到系统的设计与实现。以下是详细的知识点概述:
1. **搜索引擎相关理论**:
- 搜索引擎简介:搜索引擎是互联网用户查找信息的主要工具,它通过索引网页并提供查询服务来帮助用户找到所需内容。
- 发展历史:搜索引擎经历了从早期的简单索引到现在的复杂排名算法,如PageRank等的演变。
- 主要需求:高效的信息搜集、准确的预处理(如HTML解析、关键词提取)、快速的查询响应和高质量的搜索结果。
- 系统组成:包括信息搜集(爬虫)、预处理(索引生成)和信息查询服务(查询处理和结果展示)。
2. **爬虫系统基本原理**:
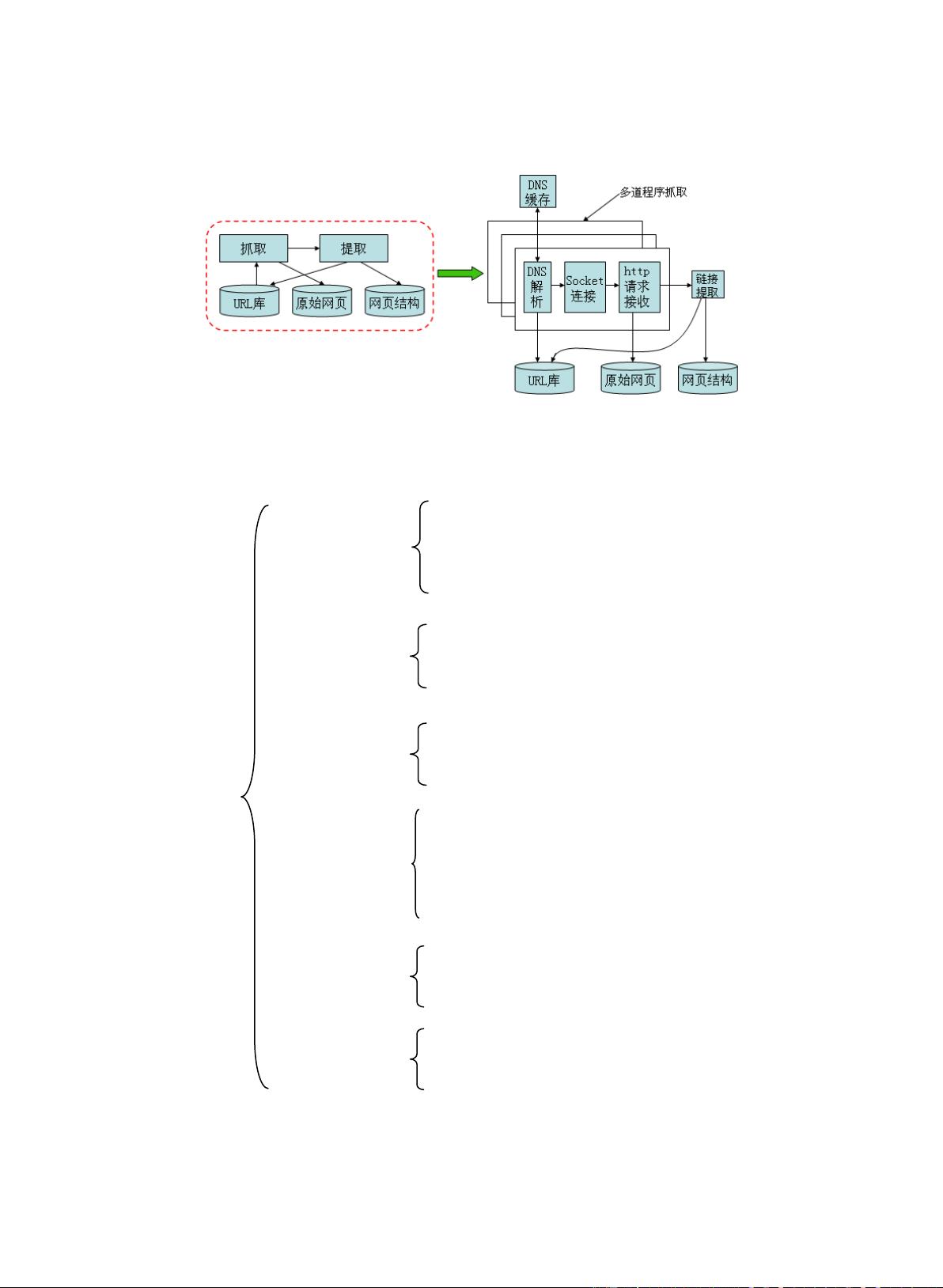
- 超文本传输协议(HTTP/HTTPS):爬虫通过这些协议与服务器交互,获取网页内容。
- 爬虫系统雏形:从单线程逐步演变为多线程和分布式系统,以提高爬取效率和范围。
- 通信信道建立:爬虫如何建立和管理与服务器的连接,以及请求和接收数据的过程。
- HTML解析:爬虫解析HTML以提取有价值的信息,并构建URL队列。
3. **分布式Web Crawler核心技术**:
- 网页抓取策略:深度优先(DFS)、广度优先(BFS)和最佳优先(如PageRank),每种策略有其优缺点和适用场景。
- 万维网的直径:理解网络的规模和复杂性,对于设计爬虫的抓取策略至关重要。
- 网页重要性判定:PageRank和其他算法用于评估网页的重要性,决定抓取顺序。
- 不重复抓取策略:避免重复抓取同一网页,常用算法包括基于B-树和哈希的方法。
- 网页重访策略:根据网页更新频率和重要性制定重访计划,确保信息新鲜。
- Robots协议:遵循网站的Robots.txt文件,尊重网站的抓取权限。
4. **分布式Web Crawler系统设计**:
- 系统结构设计:通常采用主从结构,多个爬虫节点协作工作,共享URL队列和抓取结果。
- 抓取流程设计:包括URL发现、请求、接收、解析、存储和重访等步骤。
- 分布式合作抓取算法:确保负载均衡和高效抓取,可能涉及任务调度和数据同步机制。
- 分布式实现策略:包括分布式架构的选择(如MapReduce或P2P)和具体实施步骤。
- 网页存储结构设计:考虑存储效率和查询性能,可能采用B-Tree、哈希表等数据结构。
5. **分布式Web Crawler系统实现**:
- 实现细节涵盖了系统构建的实际步骤,可能包括服务器部署、代码编写、调试和性能优化等。
这份文档深入探讨了分布式Web Crawler的理论基础、关键技术、系统设计和实现方法,对于理解大规模网络信息搜集和搜索引擎的工作原理具有很高的价值。
8
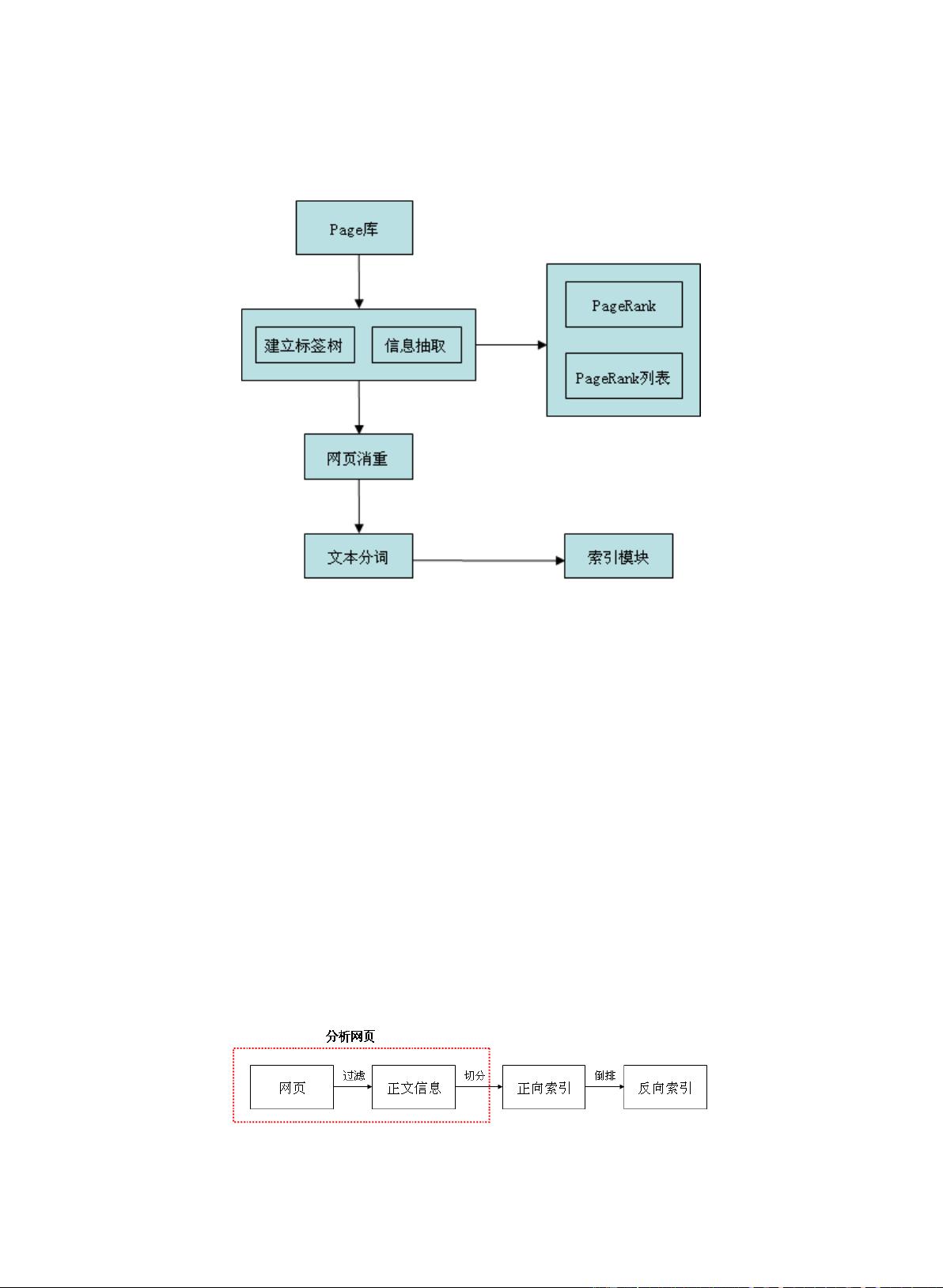
2.4 搜索引擎的系统组成
搜索引擎的工作由三个主要阶段构成
[6]
,他们分别是:
(1) web 信息的搜集
(2) 对搜索信息的预处理
(3) 信息查询服务
图2.1 搜索引擎系统组成
搜
索
引
擎
系
统
组
成
网页搜集
定期搜集
增量搜集
遍历策略的选择及其结果的优劣
预处理
工作目的:
“倒排文件”是用文档中所含的关键词作为索引,
文档作为索引目标的一种结构。
工作中的
四个主要问题
1.关键词的提取
2.重复或转载网页的消除
3.链接分析
4.网页重要程度的计算
查询服务
工作目的:根据倒排文件结构实现从集合到列表的转换
工作中的
三个方面的问题
1.查询方式和匹配
2.结果排序
3.文档摘要的生成
网页集合
“倒排文件”
形成

剩余70页未读,继续阅读
2011-12-12 上传
2021-08-08 上传
2021-08-11 上传
2021-08-08 上传
2011-07-25 上传
2019-05-16 上传
2021-10-08 上传

programmh
- 粉丝: 4
- 资源: 2162
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
