深度学习优化:交叉熵误差与梯度消失问题解析
需积分: 49 78 浏览量
更新于2024-07-19
收藏 684KB PPTX 举报
"本文主要探讨了深度学习中的交叉熵误差原理及其在神经网络优化中的作用。交叉熵作为损失函数能够有效解决二次代价函数在接近最优解时梯度更新缓慢的问题,尤其适用于二分类问题。此外,文章还提到了深度神经网络在训练过程中遇到的梯度消失和梯度爆炸问题,以及这些问题对网络学习效率的影响。"
深度学习中的交叉熵误差原理是优化神经网络学习过程的关键。传统的二次代价函数在接近最优解时,其梯度会变得很小,导致网络更新缓慢,学习进程受阻。而交叉熵代价函数能够有效地解决这一问题。它对神经网络的输出和目标输出之间的差异敏感,当神经元的实际输出接近目标值时,交叉熵误差会趋向于0,因此在网络犯明显错误时,能更快地调整权重,加快学习进程。
交叉熵函数来源于信息论,它是衡量两个概率分布之间差异的指标,可以理解为预测分布与真实分布之间的不确定性。在二分类问题中,交叉熵误差函数是理想的损失函数,因为它确保了非负性,并且当预测值与目标值一致时,误差最小。
然而,深度神经网络在训练过程中可能会遇到梯度消失和梯度爆炸问题。前者是指随着网络层数增加,反向传播时梯度逐渐减小,导致深层网络的学习速率降低,而后者则是梯度异常增大,使得权重更新剧烈,模型训练不稳定。这两种现象都会阻碍网络的有效学习。
梯度消失通常与权重初始化、激活函数的选择以及网络结构有关。例如,sigmoid和tanh激活函数在饱和区的导数值极小,可能导致后层的梯度很小。相反,ReLU等激活函数可以缓解这个问题,但过度使用也可能导致“死亡ReLU”现象,即部分神经元不再参与学习。
为了解决这些问题,可以采取一些策略,如使用批量归一化、残差连接、权重初始化技术(如Xavier初始化或He初始化)以及优化器(如RMSprop、Adam等),这些都能在一定程度上改善梯度流动,使深度网络训练更加稳定和高效。
此外,权重初始化对于避免梯度消失和梯度爆炸至关重要。使用均值为0、标准差为1的高斯分布初始化权重,可以帮助保持梯度在一个合适的范围内。同时,选择适合的优化算法,如随机梯度下降(SGD)的变体,也能影响网络的训练效果。
理解和应用交叉熵误差以及应对深度学习中的梯度问题,对于优化神经网络性能至关重要。通过不断探索和实验,我们可以找到更有效的训练策略,以提升深度学习模型的准确性和泛化能力。
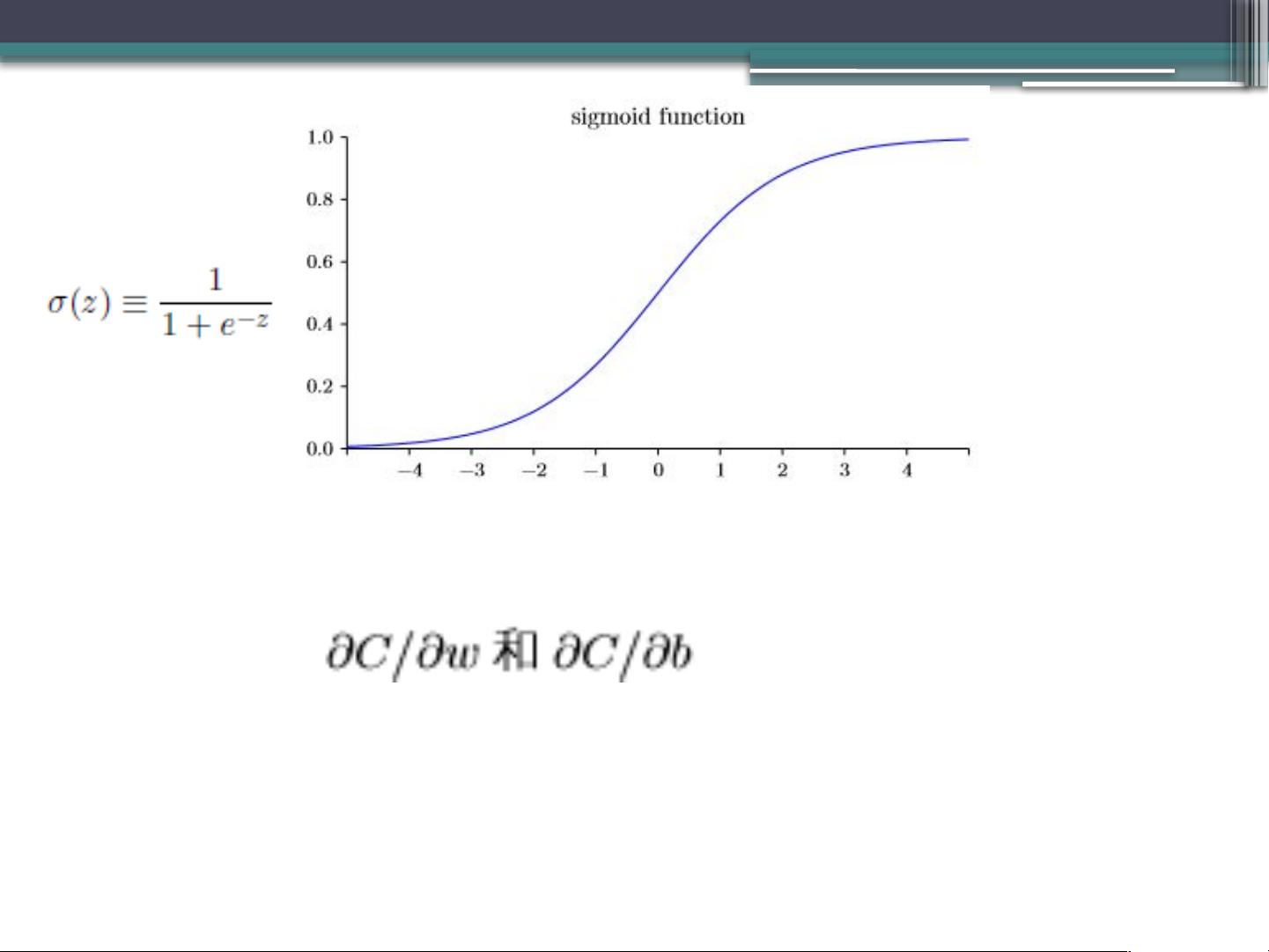
•
当输入接近为 1 时,函数会变得较为平缓,则
接近为 0 , 也会较为小,从
而更新缓慢
z
剩余21页未读,继续阅读
2021-05-30 上传
2021-01-06 上传
2022-07-14 上传
点击了解资源详情
2018-05-28 上传
2022-04-13 上传
2021-09-03 上传
点击了解资源详情

2008qianyg2008
- 粉丝: 4
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- Struts快速学习指南
- 新型 求真 有效 值芯片 AD536的应 用
- Convex Optimization book (pdf)
- Web Service配置示例(例子)
- ajax方式载入外部页面数据的层打开效果.txt
- AJAX开发简略-简体中文教程
- 图书管理系统可行性分析
- STL_Tutorial_Reference.pdf
- GNU make中文手册
- How to Break MD5 and Other Hash Functions
- js精确定位HTML标签的TOP和LEFT值
- 高质量C编程指南 编程时我们经常忽视的地方
- QQ2440之初体验.pdf
- at89s52中文资料
- SAP人力资源管理功能概述
- S3C2440数据手册
