Transformer:编码器-解码器架构的革命性设计
版权申诉
163 浏览量
更新于2024-07-04
收藏 599KB PDF 举报
Transformer是一种基于编码器-解码器架构的深度学习模型,它最初由 Vaswani 等人在2017年的论文《Attention is All You Need》中提出,为解决传统神经网络在处理变长序列时的局限性提供了新的解决方案。相比于传统的CNN(卷积神经网络)和RNN(循环神经网络),Transformer通过注意力机制显著提高了并行计算能力,同时保持了对长距离依赖的有效捕捉。
1. **编码器-解码器架构**:
Transformer的核心结构与seq2seq(sequence-to-sequence)模型类似,但使用了Transformer块(Transformer Blocks)替代了RNN的循环结构。这种结构由多头注意力层(Multi-head Attention Layers)和位置感知的前馈神经网络(Position-wise Feed-Forward Networks,FFN)组成。编码器负责处理输入序列,而解码器则在编码器的基础上添加了一个额外的多头注意力层,用于接收编码器的输出。
2. **注意力机制**:
多头注意力层是Transformer的主要创新点,它允许多个注意力机制同时处理输入序列的不同部分,提高了模型的全局理解和上下文捕捉能力。每个注意力头负责关注输入的不同子集,通过线性变换和加权求和的方式融合这些信息。
3. **残差连接与层归一化**:
在Transformer中,每个Transformer块之后都有一个“add and norm”层,包含了残差连接(Residual Connections)和层归一化(Layer Normalization),这有助于模型的学习和优化过程,加速了梯度传播并提高了训练稳定性。
4. **位置编码**:
自注意力机制本身不考虑元素的相对顺序,因此引入了位置编码(Positional Encoding)来提供序列信息,确保模型能够理解输入序列中不同位置的元素特征。常用的位移编码方法有Sinusoidal Positional Encoding,它通过正弦和余弦函数将位置信息嵌入到词嵌入中。
5. **实现细节**:
代码示例中提到的`SequenceMask`函数用于处理填充(padding)问题,通常在序列到序列模型中,当遇到变长输入时,会用一个特定值(如-1e6)填充序列的末尾,以避免在计算过程中混淆实际数据和填充部分。
在实践中,Transformer已广泛应用于机器翻译、自然语言处理和语音识别等领域,其高效性和性能使得它成为了现代深度学习中的标志性模型之一。后续的章节将详细介绍如何实现Transformer的各个组件,并通过实际的神经机器翻译任务来展示其工作原理。
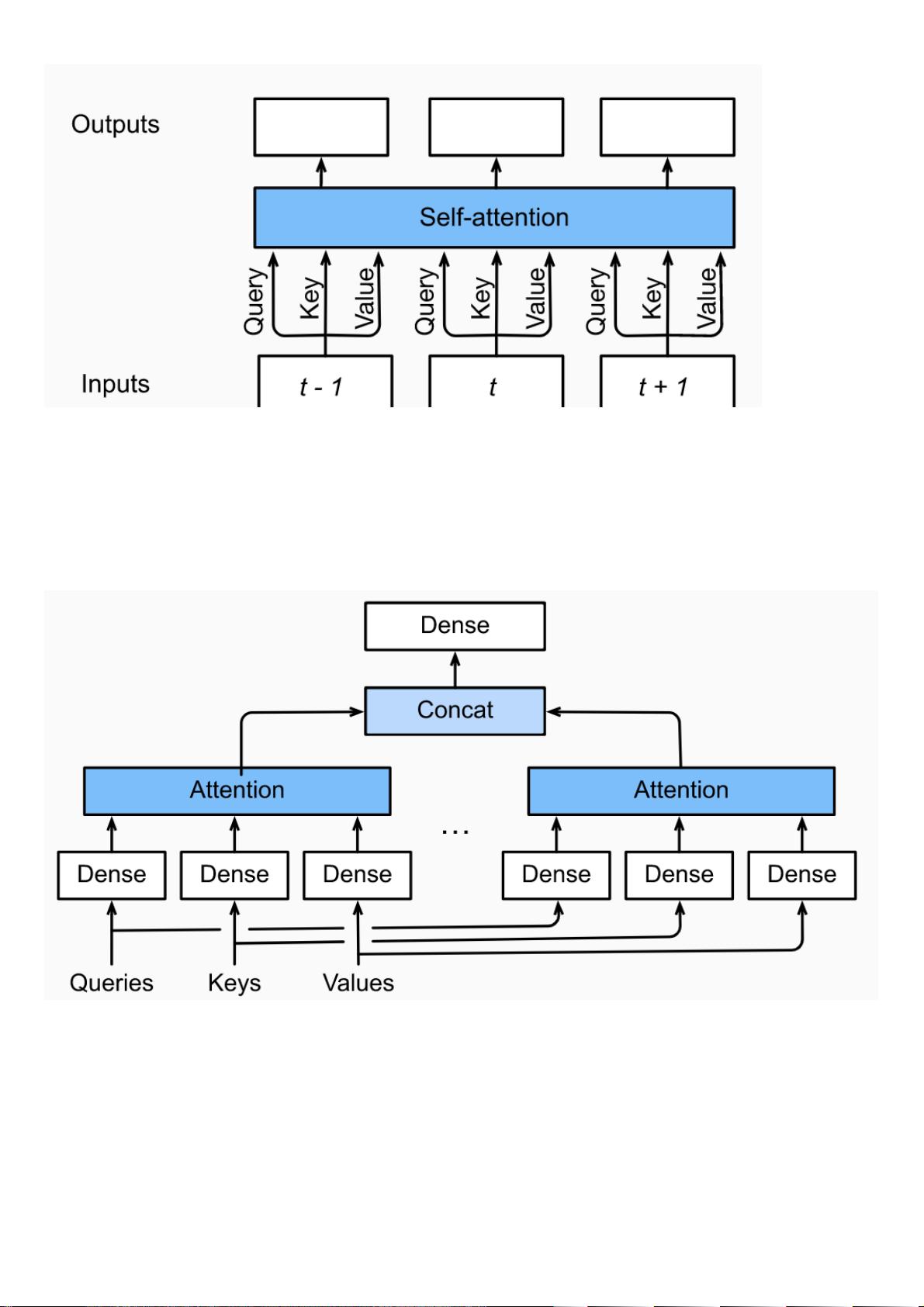
多头注意⼒层包含 个并⾏的⾃注意⼒层,每⼀个这种层被成为⼀个head。对每个头来说,在进⾏注意⼒计算之前,我们会将query、key
和value⽤三个现⾏层进⾏映射,这 个注意⼒头的输出将会被拼接之后输⼊最后⼀个线性层进⾏整合。
假设query,key和value的维度分别是 、 和 。那么对于每⼀个头 ,我们可以训练相应的模型权重 、
和 ,以得到每个头的输出:
Fig.10.3.2 ⾃注意⼒结构
h
h
Fig.10.3.3 多头注意⼒
d
q
d
k
d
v
i = 1, … , h W ∈
q
(i)
R
p ×d
q q
W ∈
k
(i)
R
p ×dk k
W ∈v
(i)
R
p ×d
v v
o =
(i)
attention(W q, W k, W v)
q
(i)
k
(i)
v
(i)
剩余14页未读,继续阅读
2021-02-14 上传
2021-01-06 上传
2021-02-13 上传
2021-03-22 上传
2021-05-20 上传
2024-05-24 上传
2021-03-07 上传
点击了解资源详情
点击了解资源详情

Aamboo
- 粉丝: 19
- 资源: 560
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
