




Spark ML Pipeline:线性回归交叉验证实战
需积分: 20 89 浏览量
更新于2024-09-07
收藏 218KB DOCX 举报
本文档详细介绍了使用Spark MLlib库中的Pipeline和CrossValidator组件进行线性回归模型训练和交叉验证的过程。主要关注如何设置参数、构建流水线以及评估模型性能。
在Spark ML中,Pipeline机制允许将多个转换和预测步骤组合成一个单一的可调用对象,简化了机器学习流程。交叉验证(Cross Validation, CV)则是一种统计学方法,用于评估模型的泛化能力,通过将数据集分割成多个折叠并进行多次训练和验证来选择最佳模型参数。
1.1 模型训练
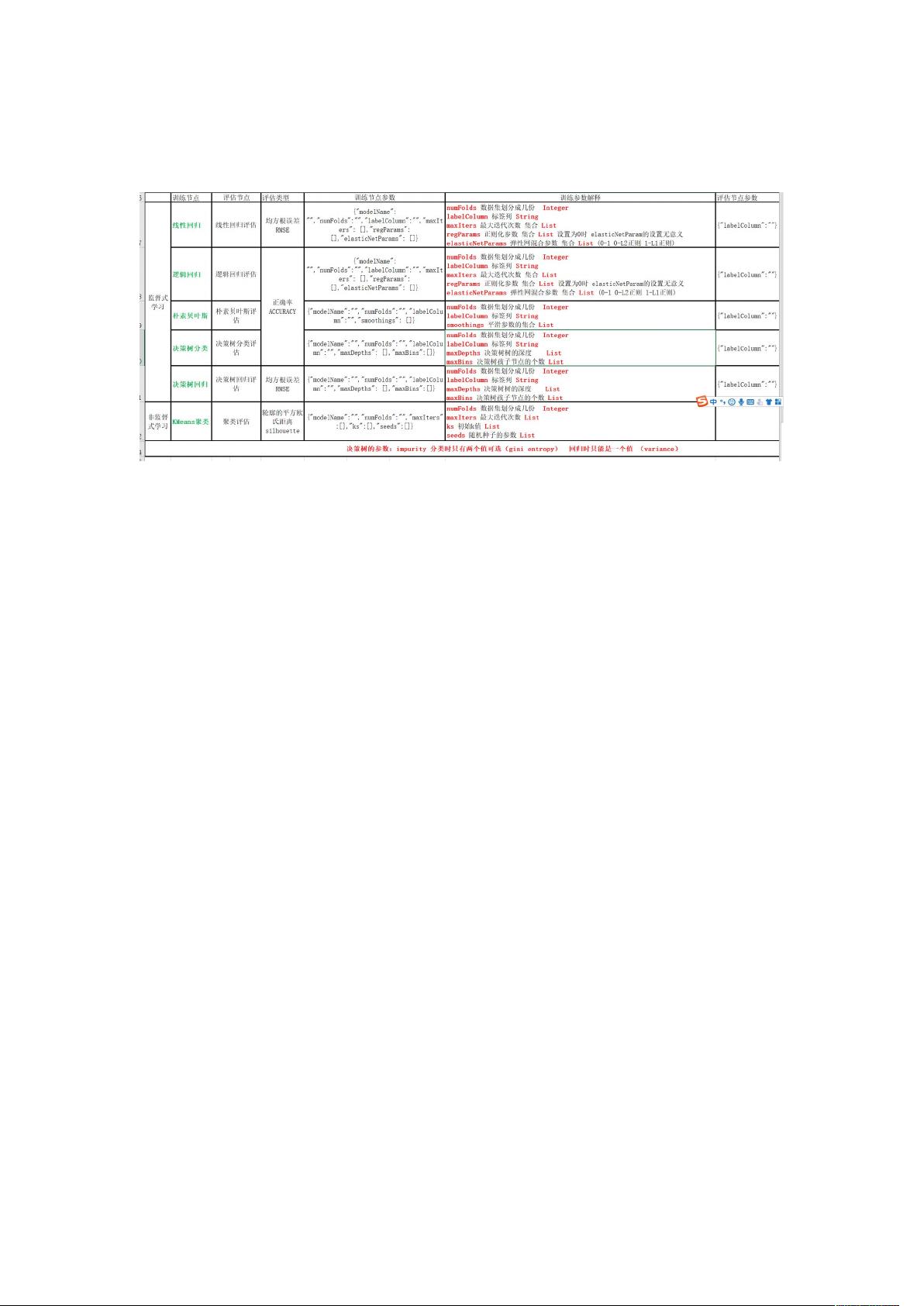
在训练阶段,我们需要定义模型的输入参数,包括:
- "modelName":模型名称,这里是"航班预测"。
- "numFolds":交叉验证的折数,设为5。
- "labelColumn":目标变量,即因变量,此处为"ArrDelay"。
- "maxIters":线性回归模型的最大迭代次数,考虑了10、20、50、100、200这几种值。
- "regParams":正则化参数,用于防止过拟合,值有0.01、0.1、1、10。
- "elasticNetParams":Elastic Net的混合参数,控制L1和L2正则化的相对比例,取值范围是0到1,包含0和1。
1.1.2 训练代码示例
训练代码中,首先引入了必要的Spark ML库,如Pipeline、PipelineModel、RegressionEvaluator等。接下来,使用了以下步骤:
1. 创建特征组装器(VectorAssembler)将数据转换为适合模型训练的向量格式。
2. 使用StandardScaler进行特征缩放,确保特征在同一尺度上。
3. 定义线性回归模型(LinearRegression),并设置参数。
4. 创建参数网格(ParamGridBuilder),结合maxIters、regParams和elasticNetParams构建参数搜索空间。
5. 创建交叉验证器(CrossValidator),指定折数(numFolds)和参数网格。
6. 将特征组装器、标准化器和线性回归模型封装到Pipeline中。
7. 使用交叉验证器和Pipeline进行模型训练,交叉验证会为每个参数组合训练numFolds个模型,并选择最佳模型。
8. 最后,使用RegressionEvaluator评估模型性能,通常通过均方误差(MSE)或R²分数来衡量。
这个过程是自动化的,可以有效地调整模型参数,寻找最佳的线性回归模型,以提高对"ArrDelay"(航班延误)的预测精度。通过交叉验证,我们可以得到一个经过验证的模型,该模型不仅在训练集上表现良好,而且在未见过的数据上也有较好的泛化能力。
Spark ml pipline 交叉验证之线性回归
1.1 模型训练
1.1.1 输入参数
{
"modelName ": "航班预测 ",
"numFolds ": "5 ",
"labelColumn ": "ArrDelay ",
"maxIters ": [
10,
20,
50,
100,
200
],
"regParams ": [
0.01,
0.1,
1,
10
],
"elasticNetParams ": [
下载后可阅读完整内容,剩余5页未读,立即下载
347 浏览量
411 浏览量
470 浏览量
230 浏览量
2022-02-08 上传
134 浏览量
432 浏览量
2024-04-05 上传

码上中年
- 粉丝: 31
 我的内容管理
展开
我的内容管理
展开








最新资源
- TestLink 1.9.4汉化包发布,实现本地化快速替换
- 东北大学电机拖动与控制课程PPT
- 电子科技大学Java面向对象程序设计课件
- 仿新版QQ实现iOS侧边导航栏教程
- C#桌面宠物秀源码分享,学习与欣赏
- 掌握JavaScript核心技术:从零基础到实践应用
- Alloy Team核心资源包:自定义数据格式详解
- ProcessExplorer:全面监控Windows进程文件占用
- UCOS II 1.38版本在LPC2131上的移植指南
- 梯形图形变换:平移、缩放及旋转程序示例
- Java播放器开发实践:使用JMF技术
- STM32F10x硬件IIC程序实现与验证
- 水木清华站Delphi编程精华完全版电子书
- 掌握时间序列分析:北京大学教材精要
- Linux平台嵌入式开发基础教程
- C#图书馆管理系统:源代码与数据库文件详解






















