人工智能通用大模型ChatGPT:进展、风险与应对策略
需积分: 1 132 浏览量
更新于2024-06-26
收藏 3.24MB PDF 举报
“人工智能通用大模型(ChatGPT)的进展、风险与应对。发布单位:华东政法大学政治学研究院、华东政法大学人工智能与大数据指数研究院。”
本文主要探讨了人工智能通用大模型,特别是ChatGPT的最新进展、潜在风险及其应对策略。首先,通用大模型被定义为具有大量参数和复杂架构的深度学习模型,它们通过预训练在大规模数据集上学习,然后通过微调适应各种复杂任务,如计算机视觉和自然语言处理。
大模型的发展经历了从单语言到多语言再到多模态的演变。早期的模型专注于自然语言处理,随后发展到能处理多种语言的任务,而现在的大模型甚至可以整合文本、图像和视频,实现跨模态的理解和处理。这种发展体现了大模型的扩展性、复合性和涌现性,它们能够集成多种AI核心技术,提高解决问题的效率,并支持更广泛的应用场景。
然而,随着大模型能力的提升,也带来了显著的风险。其中包括数据隐私问题,因为大模型需要大量的个人数据进行训练;模型的公平性和偏见问题,模型可能会反映训练数据中的社会偏见;以及安全问题,恶意用户可能利用模型的漏洞进行攻击。此外,大模型的运行成本高、能耗大,对环境造成的影响也不容忽视。
为了应对这些风险,文中提出了几种策略。首先,加强数据保护,实施严格的隐私政策和数据加密措施。其次,建立公平性和透明度的标准,对模型进行审计,减少偏见。再者,需要研发更安全的模型架构,防止模型被滥用。最后,推动绿色AI的研究,降低大模型的能耗。
各国也在比较和竞争大模型的能力,这可能导致技术竞赛,同时也会促进全球合作,共同制定大模型的治理规则和标准。政府和企业需要联合起来,制定相应的法规和行业准则,确保人工智能技术的健康发展。
人工智能通用大模型,如ChatGPT,展示了巨大的潜力,但同时也带来了新的挑战。通过深入理解这些模型的工作原理,评估其风险,并采取有效的应对措施,我们可以更好地利用这项技术,同时保护公众利益和社会稳定。
1 通用大模型的近期进展
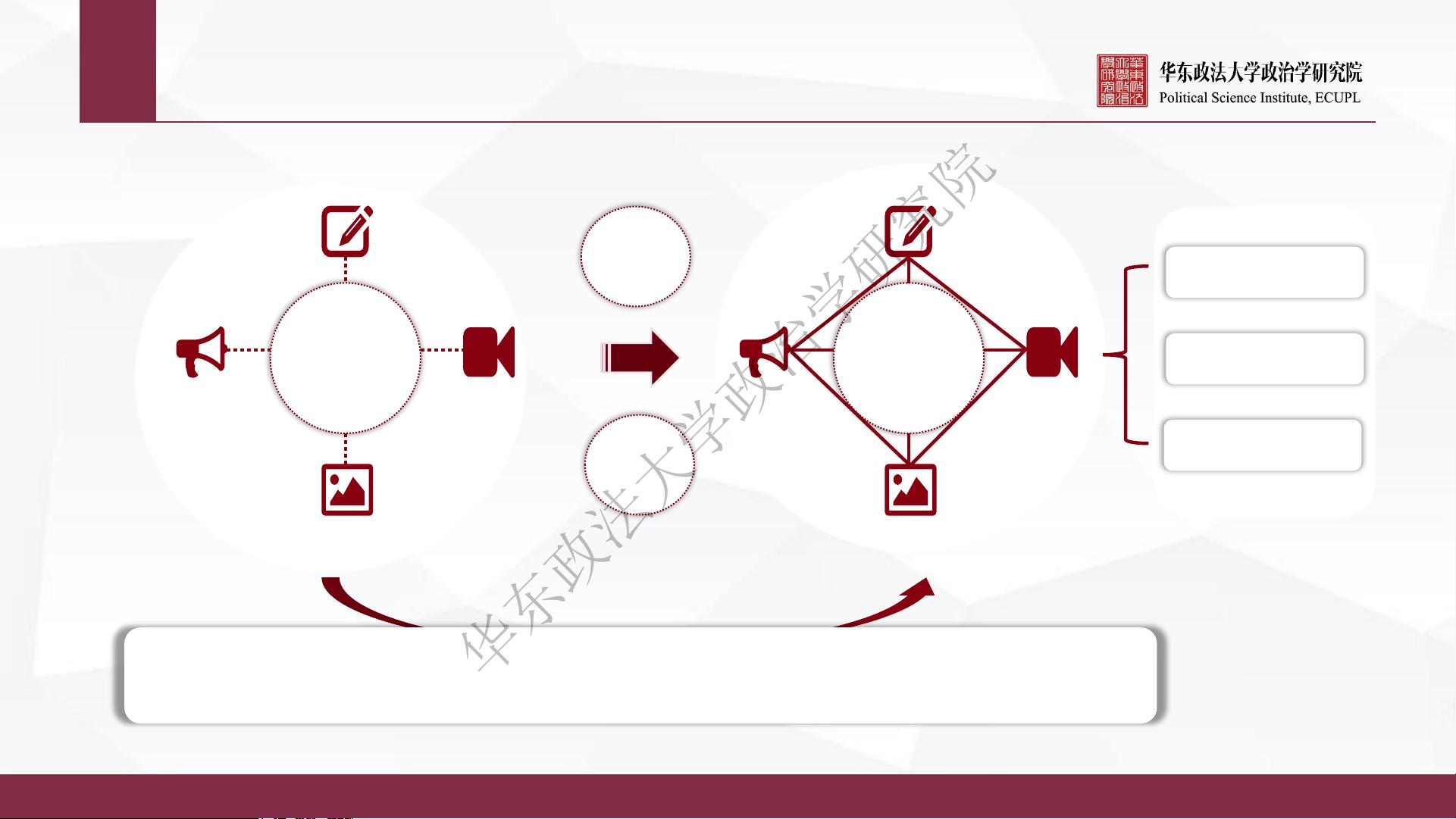
发展趋势:“大模型”和“小模型”协进
大模型
小模型
借助知识蒸馏等技术,大模型的能力可以传给小模型
改进知识蒸馏等技术,大模型一次可以产出多个小模型
利用小模型作为 Teacher,可以帮助大模型快速收敛
如
何
实
现
大
模
型
和
小
模
型
的
联
动
和
互
助
作为样本价值判断模型,小模型可以帮助大模型快速学习
1.3
10/55
华东政法大学政治学研究院
剩余54页未读,继续阅读
2023-03-10 上传
2023-05-22 上传
2023-03-09 上传
2023-08-14 上传
2023-09-15 上传
2023-04-21 上传
2023-11-16 上传
2023-05-28 上传

苏书QAQ
- 粉丝: 152
- 资源: 1049
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
