水下机器人单目SLAM算法实现与评估
需积分: 50 66 浏览量
更新于2024-07-18
5
收藏 36.79MB PDF 举报
"这篇硕士论文主要探讨了水下机器人单目SLAM(Simultaneous Localization and Mapping,同时定位与建图)的实现与评估。作者Chris Kahlefendt在论文中详细介绍了SLAM的基本概念、数学模型、不同类型的SLAM算法,并特别关注了水下环境下的SLAM挑战和解决方案。此外,还对ORBSLAM算法进行了深入的研究,包括特征提取、数据关联、初始化和跟踪等关键步骤。"
SLAM是机器人技术中的一个重要领域,它允许机器人在未知环境中构建地图的同时进行自我定位。在水下环境,由于光线散射、能见度低以及传感器性能受限,SLAM的实现变得更加复杂和具有挑战性。
论文首先介绍了SLAM的基本原理,包括数学模型的建立。SLAM问题通常通过滤波器(如EKF-SLAM)或图优化(如GraphSLAM)的方法来解决。EKF-SLAM使用扩展卡尔曼滤波进行状态估计,而GraphSLAM则将SLAM问题表示为一个优化问题,通过最小化误差图来找到最佳估计。
接着,论文讨论了多种具体的SLAM实现,例如:
1. FastSLAM:这是一种粒子滤波器方法,用于实时地估计机器人轨迹和地图。
2. DTAM( Dense Tracking and Mapping):该算法实现了稠密的实时三维重建和运动估计。
3. RatSLAM:受老鼠导航启发,适用于资源有限的机器人系统。
4. ORBSLAM:这是一种基于特征的SLAM系统,使用ORB(Oriented FAST and Rotated BRIEF)特征进行跟踪和地图构建,具有高效和鲁棒性。
5. LSDSLAM(Large-Scale Direct Monocular SLAM):侧重于大规模场景的直接法SLAM,无需预先计算特征点,而是直接处理图像像素。
在水下环境下,SLAM面临更多独特挑战,如光学畸变、水下目标的模糊以及水体的动态特性等。论文中提到了现有的一些水下SLAM方法,但同时也指出这些方法的局限性,并分析了这些挑战如何影响SLAM的性能。
最后,作者选择了ORBSLAM作为水下机器人的SLAM算法,详细分析了其工作流程,包括特征提取(如ORB特征检测)、数据关联(确保新观测到的特征与已知地图点匹配)、初始化(建立初始位姿估计)和跟踪(持续更新机器人位置并维护地图的完整性)等步骤。
这篇论文全面地探讨了水下环境中的SLAM问题,提供了对不同SLAM算法的理解,并且对ORBSLAM在水下应用中的潜力进行了深入研究,对于水下机器人技术和SLAM算法的发展具有重要的参考价值。

8 2.2 Example Implementations
In EKF-SLAM the motion model is modelled as:
P (x
k
|x
k−1
, u
k
) ⇐⇒ x
k
= f(x
k−1
, u
k
) + w
k
(2.6)
and the observation model as:
P (z
k
|x
k
, m) ⇐⇒ z
k
= h(x
k
, m) + v
k
(2.7)
where
w
k
and
v
k
resemble zero-mean, white Gaussian noise,
f
models the robot’s kinematics
and
h
describes the geometry of the observation [6]. The added noise values are used to
deal with the uncertainty in the measurements.
Implementing an EKF back-end comes with a couple of problems as pointed out by [5] and
[6]. First, the computational costs rise quadratically with the amount of landmarks kept
in the map [9]. This leads to problems when wanting to create feature rich or large maps.
This can however be reduced to a linear relationship as explained in [10]. Second, due to
the assumption that
w
k
and
v
k
are zero-mean, white and Gaussian the linearization used in
the EKF can cause intolerable errors in the estimation. Third, the EKF cannot incorporate
negative observations
2
in its estimations due to its Gaussian nature. Consequently it does
not process all available information.
Even though EKF-SLAM has these limitations EKFs are a widely used back-end and can
be regarded as a well researched topic that can achieve very good results when used under
the right conditions.
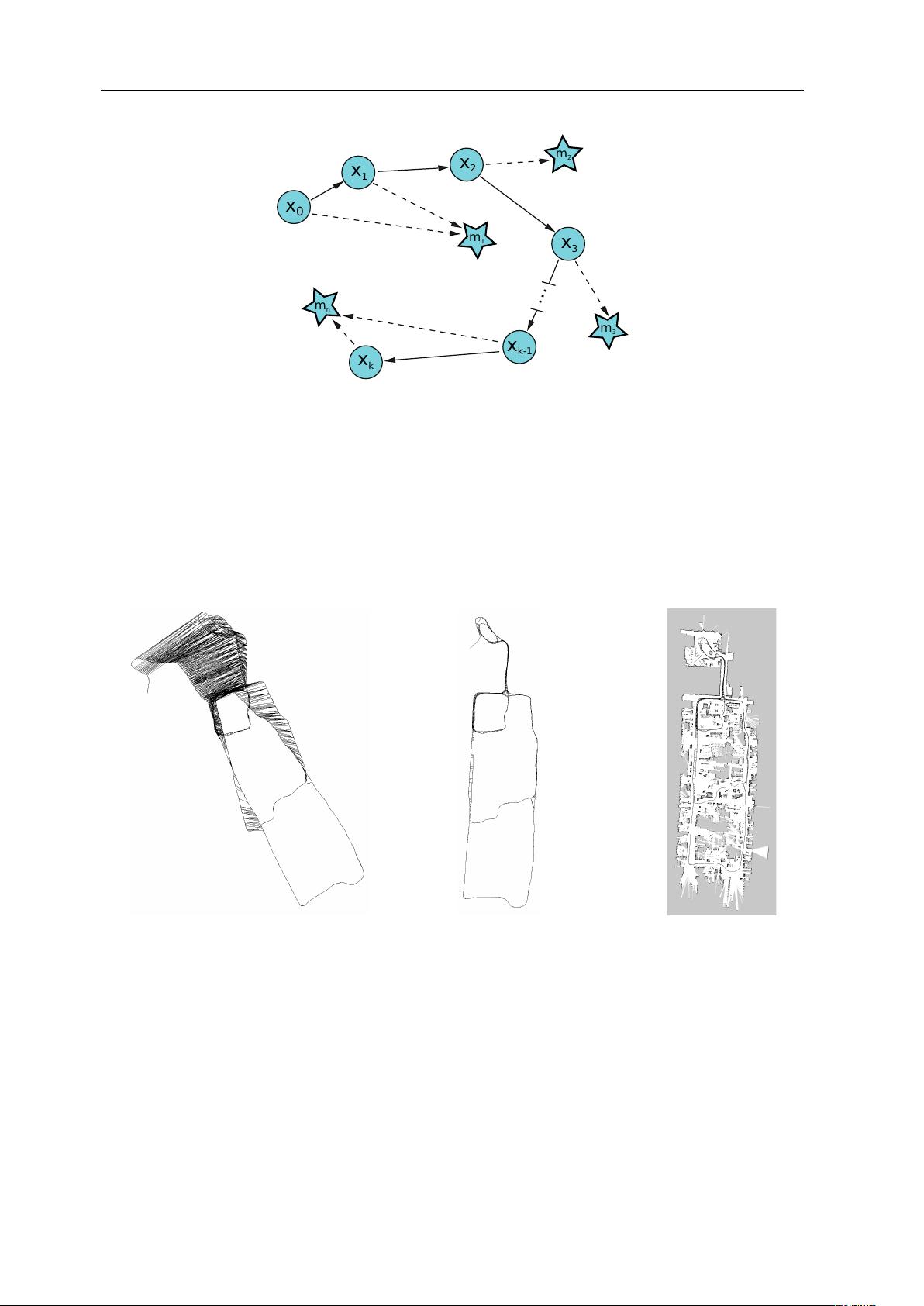
2.2.2 FastSLAM
The idea of FastSLAM was first introduced by Montemerlo et al. [11] in 2002. This section
will explain what is known as FastSLAM2.0, since this implementation has been proven to
be superior [12]. What makes FastSLAM possible is a structural property of the SLAM
problem: “correlations in the uncertainty among different map features [landmark position
estimates] arise only through robot pose uncertainty” [13]. Thanks to this, the problem
can be split into two subproblems. First: the robot localization which is done with the
help of particle filters
3
in FastSLAM. Second: estimating the landmark locations. In order
to be able to split the SLAM problem into these two parts the assumption has to be made
that the exact robot pose history is known.
Doing this the SLAM problem 2.1 can be rewritten as:
P (X
0:k
, m|Z
0:k
, U
0:k
, x
0
) = P (m|X
0:k
, Z
0:k
)P (X
0:k
|Z
0:k
, U
0:k
, x
0
) (2.8)
X
0:k
= {x
0
, x
1
, ..., x
k
} : Robot pose history
2
The absence of a landmark that is expected to be there.
3
A probabilistic approach to solving the localization problem. Each particle represents a hypothesis for
the current robot location. Over time, given enough data, particles in wrong locations are removed
while those that are most likely to be correct remain. An explanation is given in [14].


剩余126页未读,继续阅读
2021-06-03 上传
2022-08-04 上传
点击了解资源详情
点击了解资源详情
2024-10-28 上传
2022-08-03 上传

ab1233123
- 粉丝: 4
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
