超详细Flume搭建指南:从安装到日志采集实战
需积分: 0 87 浏览量
更新于2024-08-04
收藏 991KB PDF 举报
"这篇教程详细介绍了如何使用Flume来采集日志数据并将其传输到HDFS。内容涵盖了Flume的安装、配置、测试以及一个实际案例,适合初学者入门。"
在大数据领域,Flume是一个可靠且分布式的数据收集系统,常用于高效地聚合、移动和加载大量日志数据。本教程通过一个具体的实验,逐步指导读者如何设置和运行Flume,以从多个节点采集日志数据并存入HDFS。
首先,安装Flume涉及到以下几个步骤:
1. 解压缩Flume的安装包,并重命名Flume目录。
2. 配置`flume-env.sh`文件,设置环境变量。
3. 将配置和Flume目录分发到所有参与节点。
4. 激活环境变量并在所有节点上检查Flume的安装是否成功。
接着,为了测试数据传输,安装了netcat工具。利用netcat可以创建一个简单的通信端口,用于模拟数据发送和接收,以验证Flume的配置是否正确。
然后,创建Flume配置文件是整个流程的关键部分:
1. 创建`log`配置文件,定义数据源、通道和接收器。
2. 编写一个Shell脚本,定期生成日志数据。
3. 配置Flume以从各个节点收集这些日志数据,并将其发送到HDFS。
在配置文件中,需要指定数据源(source),例如使用`exec` source来执行生成日志的Shell脚本;通道(channel),如内存通道或文件通道,用于临时存储数据;以及接收器(sink),如`hdfs` sink,将数据写入HDFS。
运行配置时,可能遇到版本兼容性问题,例如Guava库的版本差异。在这种情况下,需要检查Hadoop和Flume的Guava版本,替换或调整版本以确保兼容性。
最后,启动Hadoop(仅需启动HDFS服务即可),然后依次启动Flume配置,监控HDFS以确认日志数据是否成功传输并存储。
通过这个实验,读者不仅学会了如何安装和配置Flume,还了解了如何解决常见问题,如版本冲突,以及如何通过Flume将数据流式传输到HDFS。这个过程对于理解Flume的工作原理及其在日志管理和大数据处理中的作用至关重要。
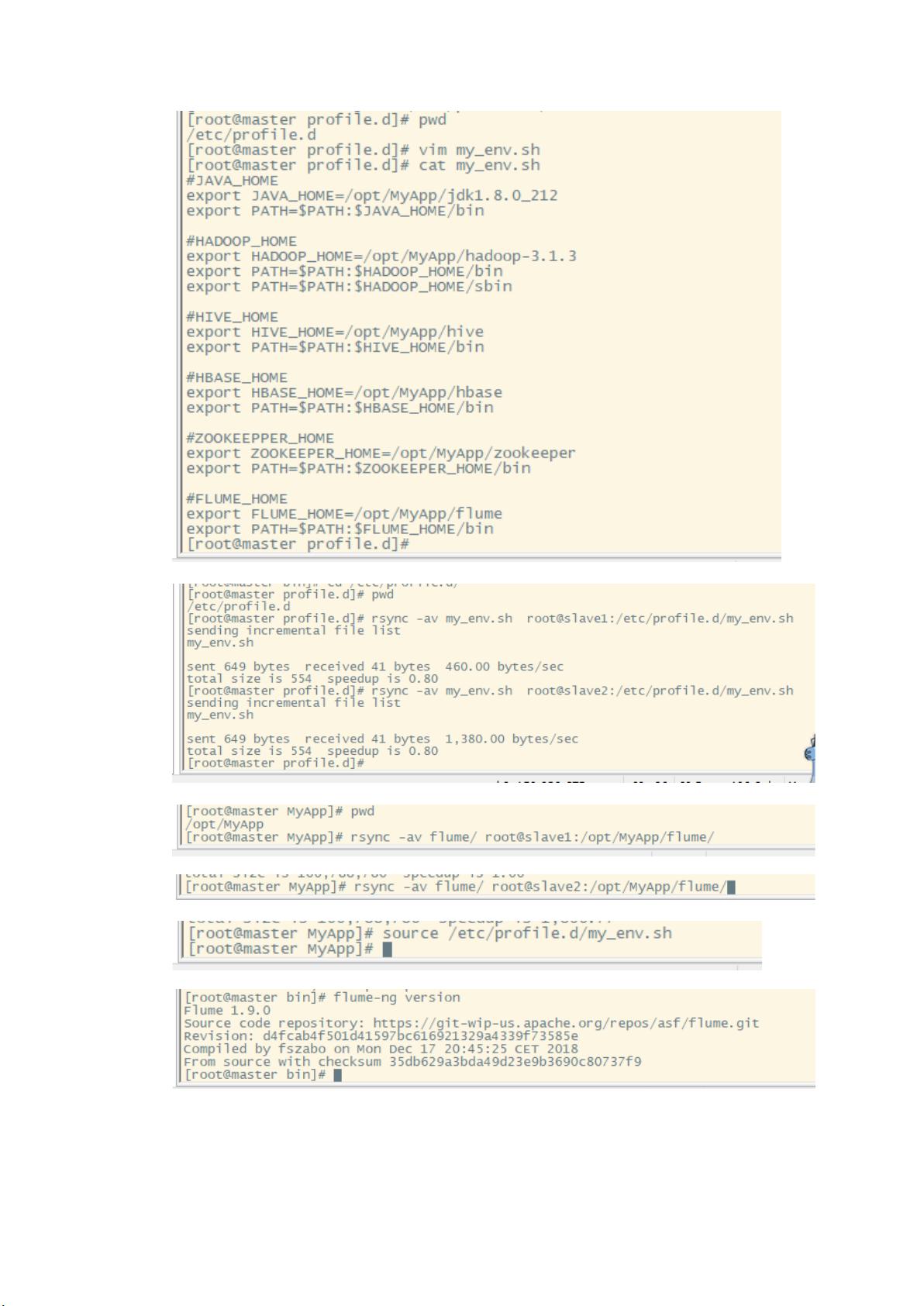
分发环境变量至 slave1,slave2 两个节点
分发 flume 目录至 slave1,slave2 两个节点
使其三台节点环境变量生效,并查看 flume 环境是完好(三台节点都需操作)
如果 flume-ng version 报错,更改 flume-ng 的 110 行(添加 2>/dev/null | grep hbase)
剩余10页未读,继续阅读
2015-05-19 上传
2024-02-23 上传
2023-05-31 上传
2023-05-11 上传
2023-12-01 上传
2023-05-20 上传
2023-08-29 上传
2023-05-11 上传
2023-06-12 上传

万物皆可盘!
- 粉丝: 4
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
