Spark架构深度解析:速度提升与全面处理框架
Apache Spark是一个高效的大数据处理框架,由加州大学伯克利分校的AMPLab在2009年开发,2010年成为Apache开源项目。相比于Hadoop和MapReduce,Spark以其显著的速度提升(内存中提升100倍,磁盘上提升10倍)在易用性和复杂分析方面表现出色。Spark的核心设计围绕着Resilient Distributed Datasets (RDDs),这是一种抽象数据结构,使得数据可以在分布式计算环境中进行高效处理。
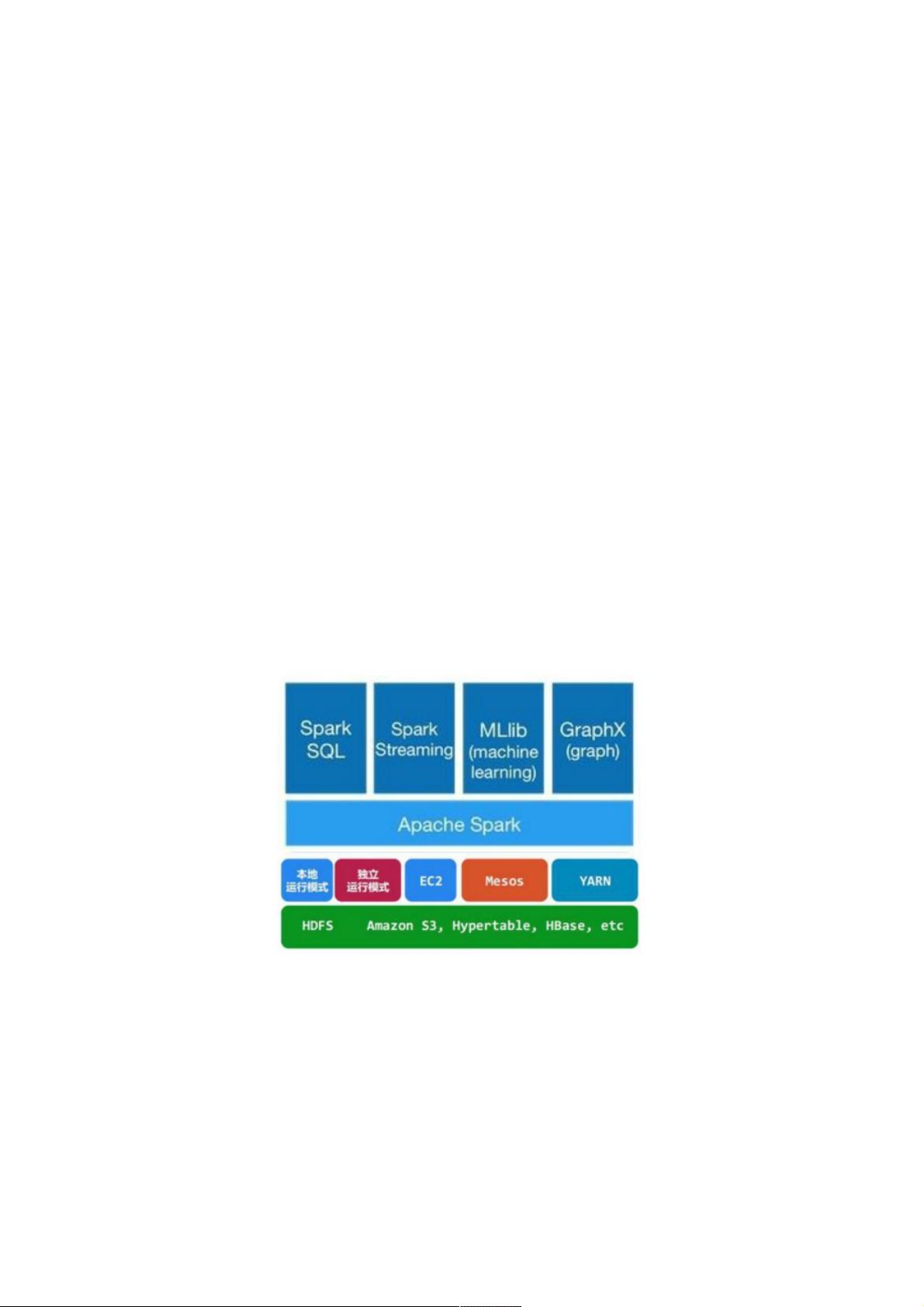
Spark架构分为以下几个关键组件:
1. **Spark Core**:这是Spark的基础,提供了定义和操作RDD的核心API,包括创建、转换、操作以及执行动作等功能。它构建了Spark其他库的基础,如Spark SQL、Spark Streaming、MLlib和GraphX。
2. **Spark SQL**:它允许用户通过HiveQL与Spark交互,将数据库表视为RDD,从而支持SQL查询和数据处理。这使得Spark能够支持结构化的数据处理,增强了数据的查询和分析能力。
3. **Spark Streaming**:专注于实时数据流处理,使程序能够像处理批处理数据一样处理连续的数据流,支持窗口函数和其他流处理特性。
4. **MLlib**:是Spark提供的机器学习库,包含一系列扩展的机器学习算法,如分类、回归等,这些算法都是以RDD操作的形式实现的,适用于大规模数据集的迭代训练。
5. **GraphX**:专为图形处理和图算法设计,扩展了RDD API,支持图的创建、操作和分析,例如图的并行计算和路径查找。
在部署模式上,Spark支持两种主要方式:
- **Standalone模式**:这是一种简单的模式,适合小型测试环境,只有一个Master节点负责协调工作。
- **YARN集群模式**:在大型分布式环境中,Spark通过YARN(Yet Another Resource Negotiator)与Hadoop YARN集成,提供更强大的资源管理和调度功能,Master节点在YARN中表现为一个应用程序管理器。
运行流程方面,Spark遵循一种“拉式”(pull-based)计算模型,数据驱动任务执行。当用户发起一个操作时,Spark会将任务划分为更小的部分,然后将这些任务分发到Worker节点,Worker节点执行任务并将结果返回给Driver节点,Driver节点再进一步聚合结果。
总结来说,Spark的架构设计注重性能优化,通过内存计算加速,提供了丰富的API和工具集,支持实时和批量数据处理,以及机器学习和图处理等多种应用场景,使得大数据分析变得更加高效和灵活。
Spark基本架构及原理基本架构及原理
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab
开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优
势:
Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实
时的流数据)的大数据处理的需求
官方资料介绍Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10
倍
目标:
1.架构及生态
2.spark 与 hadoop
3.运行流程及特点
4.常用术语
5.standalone模式
6.yarn集群
7.RDD运行流程
架构及生态:
通常当需要处理的数据量超过了单机尺度(比如我们的计算机有4GB的内存,而我们需要处理100GB以上的数据)这时我们可以
选择spark集群进行计算,有时我们可能需要处理的数据量并不大,但是计算很复杂,需要大量的时间,这时我们也可以选择
利用spark集群强大的计算资源,并行化地计算,其架构示意图如下:
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和
Spark Core之上的
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个
RDD,Spark SQL查询被转换为Spark操作。
Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需
要对大量数据集进行迭代的操作。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径
上所有顶点的操作
Spark架构的组成图如下:
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-12-02 上传
2018-05-29 上传
点击了解资源详情
2023-05-17 上传
2024-11-08 上传
2018-01-23 上传

weixin_38712416
- 粉丝: 8
- 资源: 938
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
