自动化设计选择:贝叶斯优化方法的全面概述与应用
需积分: 12 9 浏览量
更新于2024-07-15
收藏 1.37MB PDF 举报
"《从人类手中夺回控制权:贝叶斯优化的综述》一文深入探讨了在大数据应用中如何通过自动化过程提高系统性能和开发者效率。随着大数据系统的发展,这些系统通常涉及众多用户、复杂软件架构和大规模异构计算与存储资源,其构建过程中涉及到众多分布式设计决策。例如,在推荐系统、医学分析工具、实时游戏引擎和语音识别器等产品中,有许多可调整的配置参数。这些参数常常由不同开发者或团队硬编码设定,优化它们的协同作用可以显著提升系统的整体效能。
贝叶斯优化作为一种强大的机器学习方法,近年来在全球范围内受到广泛关注。它基于贝叶斯统计理论,通过迭代地构建概率模型来预测和优化设计选择。这种方法的核心思想是利用先验知识和观测数据来不断更新对目标函数(如性能指标)的估计,以此找到最优参数组合。相比于传统的网格搜索或随机搜索,贝叶斯优化在高维参数空间中表现出更高的效率,尤其适用于存在局部最优的复杂优化问题。
本文详细介绍了贝叶斯优化的原理,包括其概率建模、优化策略(如 Expected Improvement 或 Upper Confidence Bound)以及适应性特征。作者鲍巴克·沙赫拉里、凯文·斯沃斯基、齐玉·王、瑞安·阿德勒斯和南多·德弗雷塔斯等人不仅阐述了其基本算法流程,还展示了该技术在实际项目中的广泛应用,比如在搜索引擎排名优化、网络架构调优、深度学习模型参数调整等领域取得的显著成果。
通过贝叶斯优化,系统能够自动进行配置参数的调优,减少了人为干预,从而提高了产品质量,同时也提升了开发人员的生产力。这种自动化过程使得工程师可以从繁琐的调参工作中解脱出来,集中精力于更具创新性和战略性的任务。《Taking the Human Out of the Loop》这篇论文为理解并利用贝叶斯优化在大数据时代下的价值提供了全面的视角。"
number of patients who received a but were unfortunately
not cured; that is
n
a;0
¼
X
n
i¼1
Iðy
i
¼ 0; a
i
¼ aÞ (4)
n
a;1
¼
X
n
i¼1
Iðy
i
¼ 1; a
i
¼ aÞ: (5)
The convenient conjugate prior then leads to a posteriori
distribution which is also a product of betas
pðw jDÞ¼
Y
K
a¼1
bet a ðw
a
j þn
a;1
;þ n
a;0
Þ: (6)
Note that this makes it clear how the hyperparameters ;
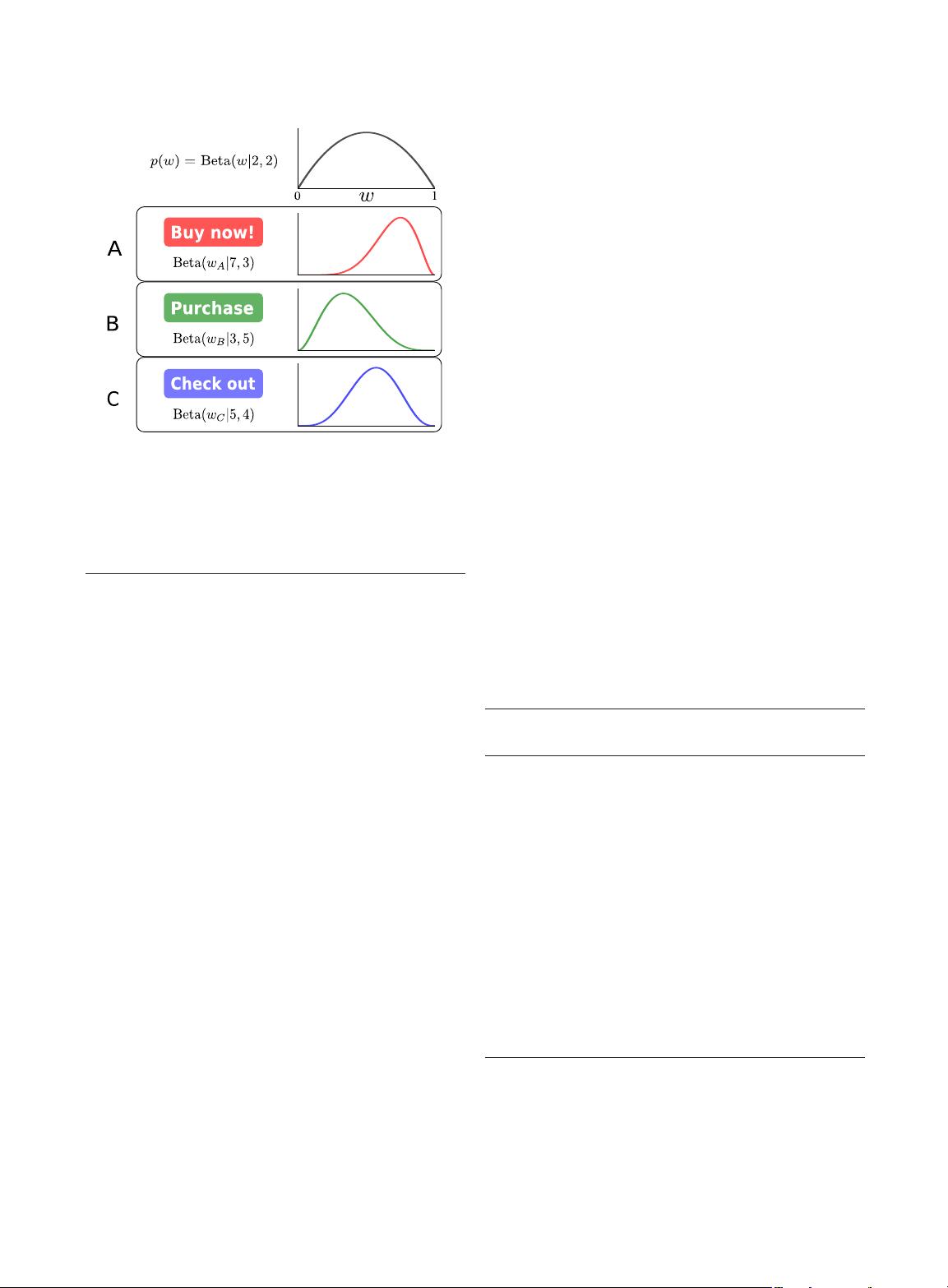
>0 in the prior can be interpreted as pseudocounts. Fig. 2
provides a visualization of the posterior of a three-armed
beta-Bernoulli bandit model with a beta(2, 2) prior.
In Section IV, we will introduce various strategies for
selecting the next arm to pull within models like the beta-
Bernoulli, but for the sake of illustration, we introduce TS
[150], the earliest and perhaps the simplest nontrivial
bandit strategy. This strategy is also commonly known as
randomized probability matching [135] because it selects
the arm based on the posterior probability of optimality,
here given by a beta distribution. In simple models like the
beta-Bernoulli, it is possible to compute this distribution
in closed form, but more often it must be estimated via,
e.g., MC.
After observing n patients in our drug example, we can
think of a bandit strategy as being a rule for choosing
which drug to administer to patient n þ 1, i.e., choosing
a
nþ1
among the K options. In the case of TS, this can be
done by drawing a single sample
~
w from the posterior and
then maximizing the resulting surrogate f
~
w
,i.e.,
a
nþ1
¼ arg max
a
f
~
w
ðaÞ; where
~
w pðw jD
n
Þ: (7)
For the beta-Bernoulli, this corresponds to simply drawing
~
w from (6) and then choosing the action with the largest
~
w
a
. This procedure, shown in pseudocode in Algorithm 2,
is also commonly called posterior sampling [127]. It is
popular for several reasons: 1) there are no free parameters
other than the prior hyperparameters of the Bayesian
model; 2) the strategy naturally trades off between
exploration and exploitation based on its posterior beliefs
on w; arms are explored only if they are likely (under the
posterior) to be optimal; 3) the strategy is relatively easy to
implement as long as MC sampling mechanisms are
available for the posterior model; and 4) the randomiza-
tion in TS makes it particularly appropriate for batch or
delayed feedback settings where many selections a
nþ1
are
based on the identical posterior [38], [135].
Algorithm 2: Thompson Sampling for Beta-Bernoulli
Bandit
Require: ; : hyperparameters of the beta prior
1: Initialize n
a;0
¼ n
a;1
¼ i ¼ 0foralla
2: repeat
3: for a ¼ 1; ...; K do
4: ~w
a
betað þ n
a;1
;þ n
a;0
Þ
5: end for
6: a
i
¼ arg max
a
~w
a
7: Observe y
i
by pulling arm a
i
8: if y
i
¼ 0 then
9: n
a
i
;0
¼ n
a
i
;0
þ 1
10: else
11: n
a
i
;1
¼ n
a
i
;1
þ 1
12: end if
13: i ¼ i þ 1
14: until stopping criterion reached
B. Linear Models
In many applications, the designs available to the
experimenter have components that can be varied
independently. For example, in designing an advertise-
ment, one has choices such as artwork, font style, and size;
if there are five choices for each, the total number of
possible configurations is 125. In general, this number
Fig. 2. Example of the beta-Bernoulli model for A/B testing. Three
different buttons are being tested with various colors and text. Each
option is given two successes (click-throughs) and two failures as a
prior (top). As data are observed, each option updates its posterior
over
w. Option A is the current best with five successes and only one
observed failure.
Shahriari et al.: Taking the Human Out of the Loop: A Review of Bayesian Optimization
Vol. 104, No. 1, January 2016 | Proceedings of the IEEE 153
剩余27页未读,继续阅读
2020-02-14 上传
2019-10-15 上传
2021-05-22 上传
2022-07-15 上传
2024-04-07 上传
2021-05-28 上传
2019-08-12 上传
2022-09-15 上传
2022-07-13 上传

GanD.GanD
- 粉丝: 3
- 资源: 90
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
