构建Flink-Kafka实验环境与部署教程
需积分: 0 191 浏览量
更新于2024-06-30
收藏 1.97MB PDF 举报
本篇文章主要介绍了如何在Flink中使用Kafka进行数据消费的实验过程,包括实验环境的搭建、华为云上的资源购买以及具体的实验步骤。首先,实验者在一台Centos7.6(基于鲲鹏aarch64架构)的虚拟机上运行,该环境包含了Hadoop 2.7.7、JDK 1.8.0、Flink 1.8.0、Zookeeper 3.4.12和Kafka 0.8.2.1版本。实验涉及到了在华为云上创建弹性云服务器ECS,选择了2vCPUs和4GB内存的配置,以及公共镜像CentOS 7.6,每台服务器配置40GB系统盘,并选择了全动态BGP网络。
在资源购买阶段,用户需要创建3台ECS,其中1台作为主节点,2台作为从节点,都采用按需计费模式。具体操作包括登录华为云、选择弹性云服务器、配置CPU架构、操作系统、磁盘、网络、云备份,最后设置SSH免密钥登录。在免密钥登录过程中,用户生成RSA密钥对,将公钥复制到`authorized_keys`文件,并确保其权限正确设置。
在开始实验之前,如果服务器已经预装了JDK和Hadoop,可以直接跳过这部分的安装步骤。对于Hadoop的安装,文章提到了两个关键步骤:一是修改主机名,例如将master主机的hostname改为"slave01"或"slave02",其他从节点也进行类似操作;二是配置SSH免密钥登录,通过生成密钥对、复制公钥和设置权限来简化后续的远程连接。
整个实验流程旨在为读者提供一个清晰的操作指南,帮助他们在实际环境中使用Flink与Kafka进行数据处理,特别是针对分布式环境下的部署和管理。这包括了从云计算平台的资源选择到本地环境的配置优化,确保了大数据处理的高效和稳定。
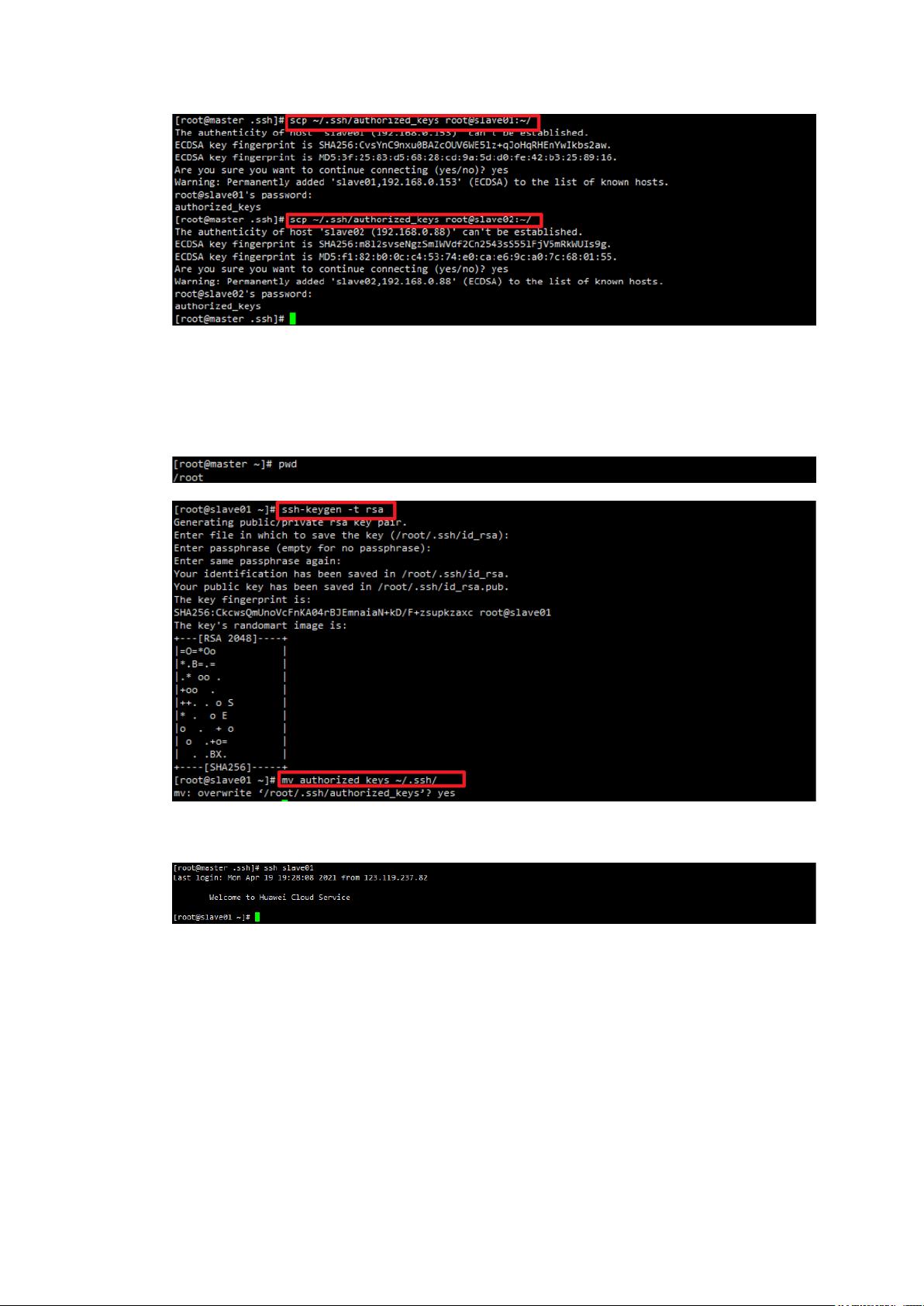
3.1.2.5 在 slave01、slave02 节点分别执行如下操作
ssh-keygen -t rsa(一直回车)
mv authorized_keys ~/.ssh/(输入 yes)
3.1.2.6 如果出现下图的内容表示免密钥配置成功
3.1.3 配置 hosts 列表
3.1.3.1 先分别在各服务器中运行 ifconfig 命令,获得当前节点的 ip 地址,如
下图是 master 的 ip 地址

剩余32页未读,继续阅读

柔粟
- 粉丝: 34
 我的内容管理
展开
我的内容管理
展开







最新资源
- Linux平台PSO服务器管理工具集:简化安装与维护
- Swift仿百度加载动画组件BaiduLoading
- 传智播客C#十三季完整教程下载揭秘
- 深入解析Inter汇编架构及其基本原理
- PHP实现QQ群聊天发言数统计工具 v1.0
- 实用AVR驱动集:IIC、红外与无线模块
- 基于ASP.NET C#的学生学籍管理系统设计与开发
- BEdita Manager:官方BEdita4 API网络后台管理应用入门指南
- 一天掌握MySQL学习笔记及实操练习
- Sybase数据库安装全程图解教程
- Service与Activity通信机制及MyBinder类实现
- Vue级联选择器数据源:全国省市区json文件
- Swift实现自定义Reveal动画播放器效果
- 仿53KF在线客服系统源码发布-多用户版及SQL版
- 利用Android手机实现远程监视系统
- Vue集成UEditor实现双向数据绑定
