回顾Pascal VOC对象挑战:2008-2012年目标检测竞赛总结
需积分: 12 108 浏览量
更新于2024-07-16
收藏 5.78MB PDF 举报
《Pascal视觉对象类别挑战:回顾与反思》(The Pascal Visual Object Classes Challenge – a Retrospective)是一篇发表在《计算机视觉国际期刊》上的文章,着重回顾了2008年至2012年间举行的目标检测PASCAL VOC(Visual Object Classes)系列挑战。该挑战由Mark Everingham、S.M.Ali Eslami、Luc Van Gool、Christopher K.I. Williams、John Winn和Andrew Zisserman等人组织,分为五个主要任务:图像分类、目标检测、分割、动作识别和人体布局。
挑战的核心是提供一个公开的图像数据集,其中包括精确的标注信息以及标准化的评估工具,这使得研究人员能够衡量算法的性能并推动技术进步。PASCAL VOC数据集因其广泛的应用和多样化的场景而受到广泛关注,它包含了多个难度级别,从简单的物体识别到复杂的实例级目标检测,为算法设计者提供了丰富的测试平台。
在这篇文章中,作者首先介绍了PASCAL VOC挑战的历史背景和目标,接着详细阐述了每年竞赛中的关键发现和技术趋势。对于算法设计者来说,文中深入剖析了各年度参赛队伍所展示的最佳实践和创新方法,以及这些方法如何提升模型在VOC数据集上的性能。同时,作者也揭示了当时技术的局限性和挑战,如小物体检测、复杂背景干扰、多目标跟踪等问题。
对于挑战设计师而言,文章讨论了作为组织者的经验教训,包括数据集的更新策略、评估指标的优化、以及如何更好地促进学术界和工业界的交流与合作。此外,文章还给出了对未来挑战的建议,例如如何平衡公平性和技术创新,如何处理实时性问题,以及如何适应不断变化的计算机视觉领域需求。
《Pascal视觉对象类别挑战:回顾与反思》不仅提供了对过去五年内计算机视觉领域重大进展的回顾,而且为未来类似挑战的设计提供了宝贵的参考,帮助研究者了解当前算法的优势和挑战,同时也为挑战的持续改进和创新指明了方向。

The Pascal Visual Object Classes Challenge – a Retrospective 7
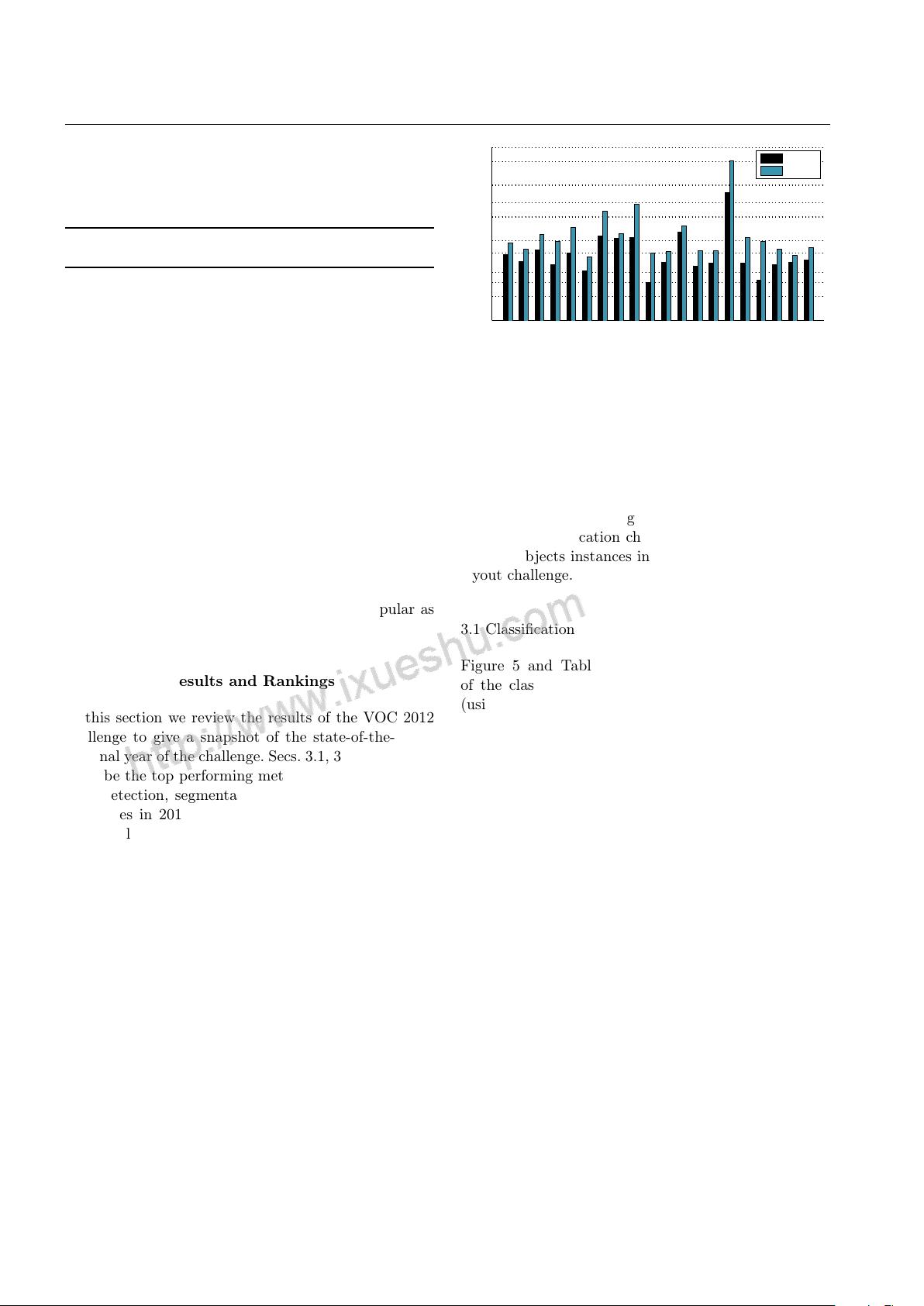
2.4.3 Classification and detection
Both the classification and detection tasks were eval-
uated as a set of 20 independent two-class tasks: e.g.
for classification “is there a car in the image?”, and for
detection “where are the cars in the image (if any)?”.
A separate ‘score’ is computed for each of the classes.
For the classification task, participants submitted re-
sults in the form of a confidence level for each image
and for each class, with larger values indicating greater
confidence that the image contains the object of in-
terest. For the detection task, participants submitted
a bounding box for each detection, with a confidence
level for each bounding box. The provision of a confi-
dence level allows results to be ranked such that the
trade-off between false positives and false negatives can
be evaluated, without defining arbitrary costs on each
type of classification error.
In the case of classification, the correctness of a class
prediction depends only on whether an image contains
an instance of that class or not. However, for detec-
tion a decision must be made on whether a prediction
is correct or not. To this end, detections were assigned
to ground truth objects and judged to be true or false
positives by measuring bounding box overlap. To be
considered a correct detection, the area of overlap a
o
between the predicted bounding box B
p
and ground
truth bounding box B
gt
must exceed 50% by the for-
mula:
a
o
=
area(B
p
∩ B
gt
)
area(B
p
∪ B
gt
)
, (1)
where B
p
∩B
gt
denotes the intersection of the predicted
and ground truth bounding boxes and B
p
∪ B
gt
their
union.
Detections output by a method were assigned to
ground truth object annotations satisfying the overlap
criterion in order ranked by the (decreasing) confidence
output. Ground truth objects with no matching detec-
tion are false negatives. Multiple detections of the same
object in an image were considered false detections, e.g.
5 detections of a single object counted as 1 correct de-
tection and 4 false detections – it was the responsibility
of the participant’s system to filter multiple detections
from its output.
For a given task and class, the precision-recall
curve is computed from a method’s ranked output.
Up until 2009 interpolated average precision (Salton
and Mcgill, 1986) was used to evaluate both classifi-
cation and detection. However, from 2010 onwards the
method of computing AP changed to use all data points
rather than TREC-style sampling (which only sampled
the monotonically decreasing curve at a fixed set of
uniformly-spaced recall values 0, 0.1, 0.2, ..., 1). The in-
tention in interpolating the precision-recall curve was
to reduce the impact of the ‘wiggles’ in the precision-
recall curve, caused by small variations in the ranking of
examples. However, the downside of this interpolation
was that the evaluation was too crude to discriminate
between the methods at low AP.
2.4.4 Segmentation
The segmentation challenge was assessed per class on
the intersection of the inferred segmentation and the
ground truth, divided by the union (commonly referred
to as the ‘intersection over union’ metric):
seg. accuracy =
true pos.
true pos. + false pos. + false neg.
(2)
Pixels marked ‘void’ in the ground truth (i.e. those
around the border of an object that are marked as nei-
ther an object class or background) are excluded from
this measure. Note, we did not evaluate at the individ-
ual object level, even though the data had annotation
that would have allowed this. Hence, the precision of
the segmentation between overlapping objects of the
same class was not assessed.
2.4.5 Action classification
The task is assessed in a similar manner to classifica-
tion. For each action class a score for that class should
be given for the person performing the action (indicated
by a bounding box or a point), so that the test data can
be ranked. The average precision is then computed for
each class.
2.4.6 Person layout
At test time the method must output the bounding
boxes of the parts (head, hands and feet) that are visi-
ble, together with a single real-valued confidence of the
layout so that a precision/recall curve can be drawn.
From VOC 2010 onwards, person layout was evalu-
ated by how well each part individually could be pre-
dicted: for each of the part types (head, hands and feet)
a precision/recall curve was computed, using the confi-
dence supplied with the person layout to determine the
ranking. A prediction of a part was considered true or
false according to the overlap test, as used in the detec-
tion challenge, i.e. for a true prediction the bounding
box of the part overlaps the ground truth by at least
50%. For each part type, the average precision was used
as the quantitative measure.
This method of evaluation was introduced following
criticism of an earlier evaluation used in 2008, that was
剩余39页未读,继续阅读
2021-07-05 上传
2022-09-23 上传
2022-09-24 上传
2022-09-19 上传
2019-06-23 上传
2012-03-27 上传
2019-07-12 上传
2022-09-21 上传
2019-05-30 上传

Ziko_AI
- 粉丝: 104
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
