Hadoop集群上部署Hive步骤详解
 已收录资源合集
已收录资源合集
需积分: 0 114 浏览量
更新于2024-08-04
收藏 255KB DOCX 举报
"该文主要介绍了如何在已安装并运行Hadoop的基础上,部署和配置Hive,以及安装和设置MySQL作为Hive的数据存储后端。整个过程主要在Hadoop集群的主节点上进行,由非root用户hfut执行大部分操作,但在安装MySQL时需要切换到root用户。"
在Hadoop环境中安装Hive首先要求Hadoop系统已经正确安装并且处于运行状态。Hive的安装步骤主要包括解压安装包、配置环境变量以及设置相关的数据库连接。在描述中,我们看到用户首先将Hive的安装包复制到home目录下,然后使用`tar -zxvf`命令解压,并进入解压后的目录。
14.1 安装Hive
解压后的Hive安装文件包括各种库文件、脚本、配置文件等,这些是Hive运行所必需的。为了便于管理和使用,通常会将Hive的安装目录添加到系统PATH环境变量中,这样可以在任何地方通过命令行调用Hive。
14.2 配置MySQL
Hive通常使用关系型数据库如MySQL来存储元数据,即关于数据的数据,例如表名、列名、分区信息等。因此,需要先安装MySQL服务器。在Linux环境下,可以使用`yum install mysql-server`命令进行安装。安装完成后,使用`service mysqld start`启动MySQL服务。确保MySQL服务正常运行对于Hive的后续配置至关重要。
在安装MySQL后,需要以root用户身份登录MySQL数据库,并创建一个用于Hive的用户。在例子中,创建了一个名为hadoop的用户,并为其分配了所有数据库的全部权限,允许这个用户从任何主机(%)、本地主机(localhost)和Hadoop Master主机登录,密码均为'hadoop'。这样的设置使得Hive可以从集群中的任何节点访问MySQL服务。
接下来的步骤可能包括:
- 配置Hive的metastore服务,将Hive元数据存储在MySQL中,需要修改`hive-site.xml`配置文件,指定数据库URL、用户名和密码。
- 初始化metastore数据库,通常使用`schematool`工具生成Hive的元数据表结构。
- 启动Hive服务,这通常包括启动Hive的metastore服务和Hive CLI(命令行界面),以便用户可以开始交互式地使用Hive。
总结来说,本文提供了在Hadoop集群上部署Hive的基本步骤,包括Hive的安装、MySQL的配置以及为Hive创建数据库用户。这些步骤是建立一个能够处理大数据的Hadoop-Hive环境的基础,对于大数据处理和分析项目至关重要。
14 安装部署 Hive
该部分的安装需要在 Hadoop 已经成功安装的基础上,并且要求 Hadoop 已经正常启动。
我们将 Hive 安装在 HadoopMaster 节点上,所以下面的所有操作都在 HadoopMaster 节点上
进行。
除特别说明外,下面的操作使用 hfut 用户。
14.1 解压并安装 Hive
使用下面的命令,解压 Hive 安装包:
[hfut@master ~]$ cp ~/resources/software/hadoop/apache/apache-hive-0.13.1-bin.tar.gz ~/
[hfut@master ~]$ tar -zxvf ~/apache-hive-0.13.1-bin.tar.gz
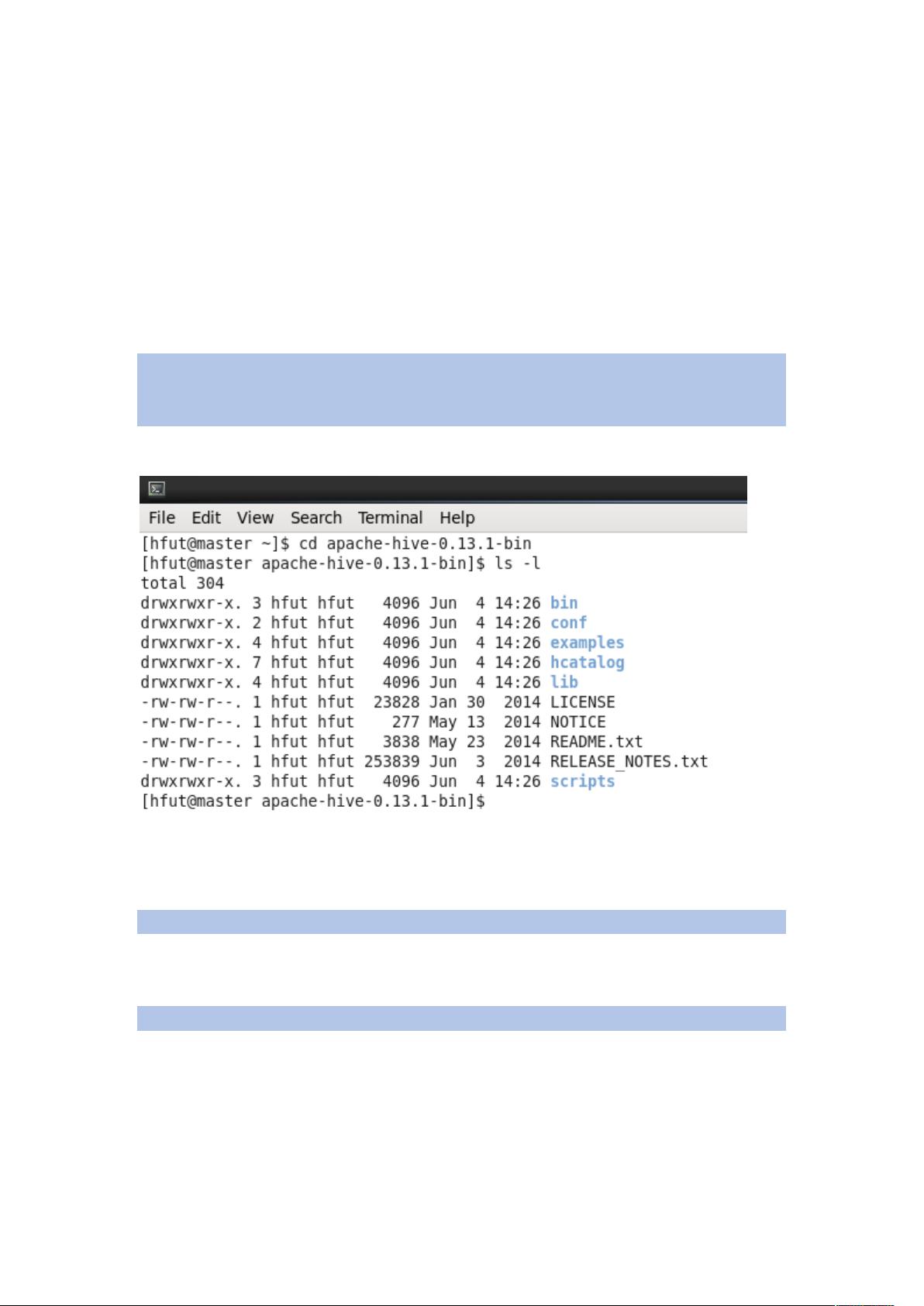
[hfut@master ~]$ cd apache-hive-0.13.1-bin
执行 ls -l 命令看到如下内容,这些是 Hive 包含的文件:
14.2 安装配置 MySQL
注意:安装和启动 MySQL 服务需要 root 权限,切换成 root 用户,命令如下:
[hfut@master ~]$ su root
输入密码:huft
安装 MySQL 服务器:
[root@master hfut]# yum install mysql-server
下载后可阅读完整内容,剩余3页未读,立即下载
2020-06-04 上传
2021-08-09 上传
2022-04-30 上传
2022-04-30 上传
2022-04-30 上传
2022-04-30 上传
2022-04-30 上传

内酷少女
- 粉丝: 20
- 资源: 302
 我的内容管理
展开
我的内容管理
展开







最新资源
- TacoGrid:只是一个网格页面练习
- opcsvrsdk,c语言库函数源码在哪里下载,c语言程序
- Sql-Connection-Variations
- strfind.m:STRFIND 的元胞数组实现-matlab开发
- CMEEProject
- Android应用源码之校园商品交易系统单机版.zip项目安卓应用源码下载
- spark_streaming_with_twitter:使用DStreams与Twitter进行火花流
- base-sort,c语言实训图书管理系统源码,c语言程序
- StratSim:一级方程式策略模拟器,用于优化和计划轮胎和进站策略
- rise_mobile_app
- hadoop:Hadoop
- up-there-
- 酒店自助在线预订平台模板
- MCU-Wireless-Multi-temp,c语言源码编译需要哪些模块,c语言程序
- phpRFT:phpRFT动态地从url下载文件并将其存储到Web服务器。-开源
- TRECA 崔佧智能低代码开发平台源码
