Linux内核链表数据结构详解
需积分: 3 168 浏览量
更新于2024-10-29
1
收藏 104KB DOC 举报
"Linux内核链表是用于组织和管理数据的一种高效数据结构,它通过指针将数据节点串联起来,提供了动态分配空间和高效插入、删除操作的能力。链表包括单链表、双链表和循环链表等类型,各有其特点和应用场景。在Linux内核中,链表被广泛应用于设备列表和其他模块的数据组织。"
一、Linux内核链表基础
Linux内核中的链表实现位于`include/linux/list.h`文件中,它提供了一种灵活且高效的链表操作机制。链表的核心结构是`struct list_head`,由两个指针成员`next`和`prev`组成,这两个指针分别指向链表中的下一个和前一个元素。这样的设计使得插入和删除操作非常快速,因为它们只需要更新相邻节点的指针。
二、链表类型及其特点
1. 单链表:每个节点只有一个指针域指向后继节点,遍历只能从头到尾。在Linux内核中,单链表常用于简单的线性数据组织,如单向队列。
2. 双链表:每个节点包含前驱和后继两个指针,支持双向遍历。这种链表更灵活,可以方便地进行双向操作,例如在链表的头部和尾部添加或删除节点。
3. 循环链表:最后一个节点的指针指向第一个节点,形成环状结构。循环链表允许从任意节点开始遍历,适用于需要循环访问数据的情况。
三、Linux内核链表操作
内核提供的链表API包括初始化链表、插入节点(在头部、尾部或指定位置)、删除节点、检查链表是否为空、遍历链表等操作。这些函数都经过优化,确保在并发环境下正确且高效地工作。
四、链表扩展:RCU和HList
- RCU(Read-Copy-Update):这是一种延迟释放技术,用于处理多读者和单写者场景。RCU保护的链表可以在读取期间不加锁,提高并发性能,而写操作则会等待所有读者完成后再更新链表。
- HList:哈希链表是一种优化的链表实现,适用于哈希表,能提供更快的查找速度。HList通过散列函数将键映射到特定的链表,从而减少查找时间。
五、内核中链表的应用
在Linux内核中,链表被广泛应用于设备驱动模型、进程调度、内存管理等众多模块。例如,设备驱动注册时会被添加到相应的设备链表中,进程间的通信也可能使用链表来维护消息队列。通过链表,内核能够动态地管理和调整系统资源,适应不断变化的系统状态。
总结来说,Linux内核链表是内核实现动态数据组织和管理的重要工具,其高效且灵活的设计使得它在处理大量数据和复杂数据结构时表现出色。无论是基础的`list_head`结构,还是扩展的RCU和HList,都在Linux内核中扮演着不可或缺的角色。理解并熟练使用这些链表机制,对于深入理解和调试Linux内核至关重要。
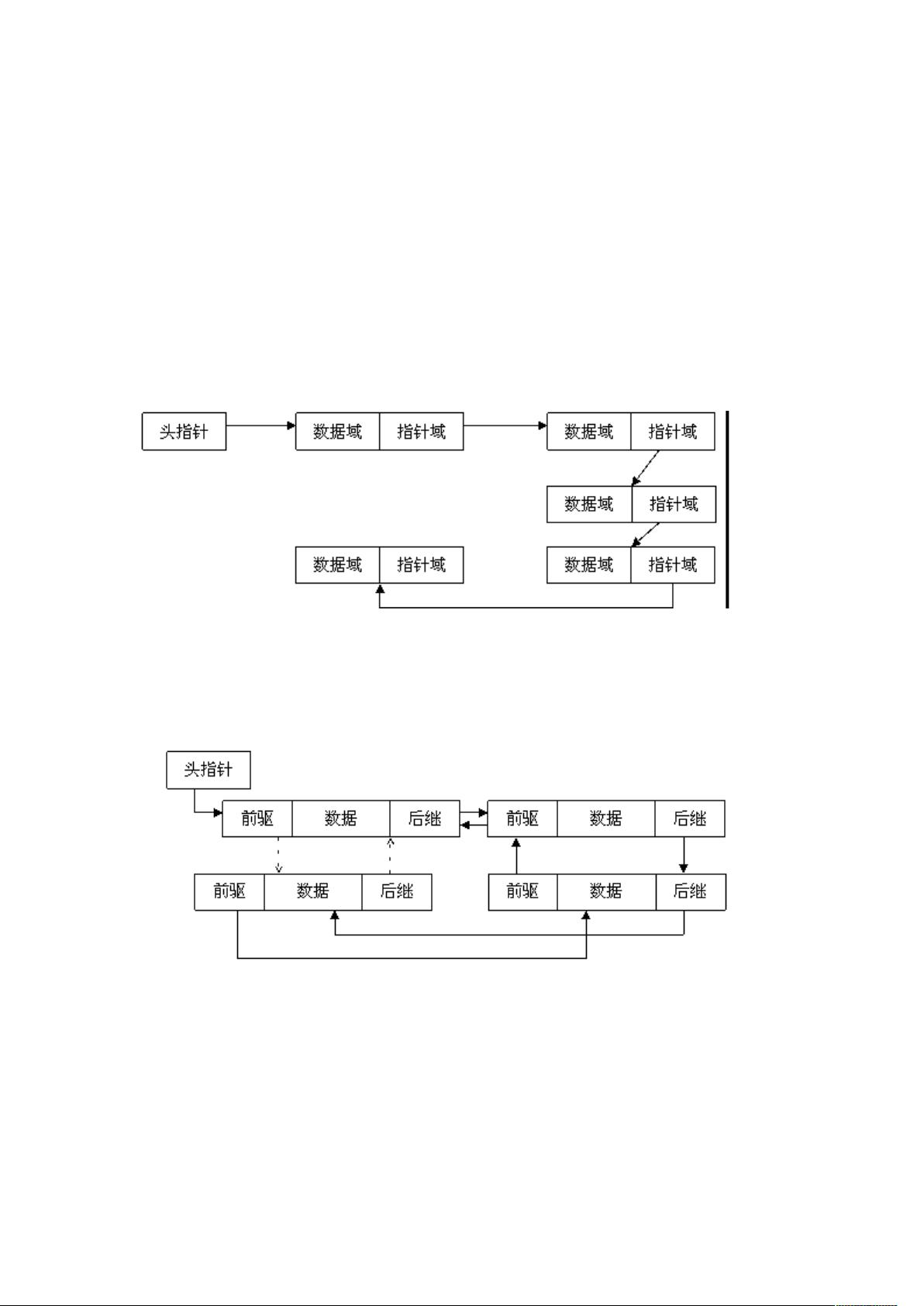
一、 链表数据结构简介
链表是一种常用的组织有序数据的数据结构,它通过指针将一系列数据节点连接成
一条数据链,是线性表的一种重要实现方式。相对于数组,链表具有更好的动态性,
建立链表时无需预先知道数据总量,可以随机分配空间,可以高效地在链表中的任
意位置实时插入或删除数据。链表的开销主要是访问的顺序性和组织链的空间损失。
通常链表数据结构至少应包含两个域:数据域和指针域,数据域用于存储数据,指
针域用于建立与下一个节点的联系。按照指针域的组织以及各个节点之间的联系形
式,链表又可以分为单链表、双链表、循环链表等多种类型,下面分别给出这几类
常见链表类型的示意图:
1. 单链表
图 1 单链表
单链表是最简单的一类链表,它的特点是仅有一个指针域指向后继节点(next),
因此,对单链表的遍历只能从头至尾(通常是 NULL 空指针)顺序进行。
2. 双链表
图 2 双链表
通过设计前驱和后继两个指针域,双链表可以从两个方向遍历,这是它区别于单链
表的地方。如果打乱前驱、后继的依赖关系,就可以构成"二叉树";如果再让首节
点的前驱指向链表尾节点、尾节点的后继指向首节点(如图 2 中虚线部分),就构
成了循环链表;如果设计更多的指针域,就可以构成各种复杂的树状数据结构。
3. 循环链表
循环链表的特点是尾节点的后继指向首节点。前面已经给出了双循环链表的示意图,
它的特点是从任意一个节点出发,沿两个方向的任何一个,都能找到链表中的任意
一个数据。如果去掉前驱指针,就是单循环链表。
下载后可阅读完整内容,剩余9页未读,立即下载
2015-12-21 上传
2023-10-15 上传
2018-09-22 上传
2013-11-11 上传

linuxlw
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
