2014年多标签学习算法综述:最新进展与关键方法
需积分: 13 37 浏览量
更新于2024-07-16
收藏 2.21MB PDF 举报
本文档《936-A Review on Multi-Label Learning Algorithms》是一篇关于多标签学习算法的综述论文,发表于2014年8月的IEEE Transactions on Knowledge and Data Engineering。多标签学习是一种新兴的机器学习方法,其核心概念是每个样本实例与一组标签相关联,而非单一的二分类问题。近年来,这一领域取得了显著进展,文章旨在对当前最先进的多标签学习算法进行系统阐述。
首先,作者介绍了多标签学习的基本概念,包括正式定义和评估指标。多标签学习的正式定义强调了每个样本可能关联多个标签的特性,这与传统的单标签学习(如每个样本仅对应一个正确答案)形成对比。评估指标对于衡量算法性能至关重要,常见的有精度、召回率、F1分数等,这些在文中都有详细的解释和应用讨论。
其次,文章的核心部分着重分析了八个具有代表性的多标签学习算法。这些算法涵盖问题转换(如Binary Relevance、Classifier Chains)、模型融合(如Label Powerset、Ranking SVM)、特征选择(如Feature Bagging)、以及更高级的方法如神经网络和深度学习的多标签版本。每种算法的原理、优缺点及适用场景都被深入剖析,并通过实例对比来展示它们在实际问题中的表现。
接着,作者还简要概述了几种相关的学习设置,例如半监督学习、在线学习和迁移学习在多标签情境下的应用,这些扩展了传统方法的边界,展示了多标签学习的灵活性和多样性。
最后,论文总结了当前领域的在线资源和未解决的研究问题。这包括可供学习者和研究者参考的开源库、工具,以及多标签学习中尚未完全解决的挑战,如如何处理大规模数据、处理高维稀疏标签空间、以及如何更好地捕捉和利用标签间的相互关系等问题。
这篇论文为多标签学习领域的研究人员和实践者提供了宝贵的参考,梳理了该领域的最新进展,同时也指出了未来研究的方向,对于理解和发展多标签学习技术具有重要意义。
1822 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 26, NO. 8, AUGUST 2014
∈
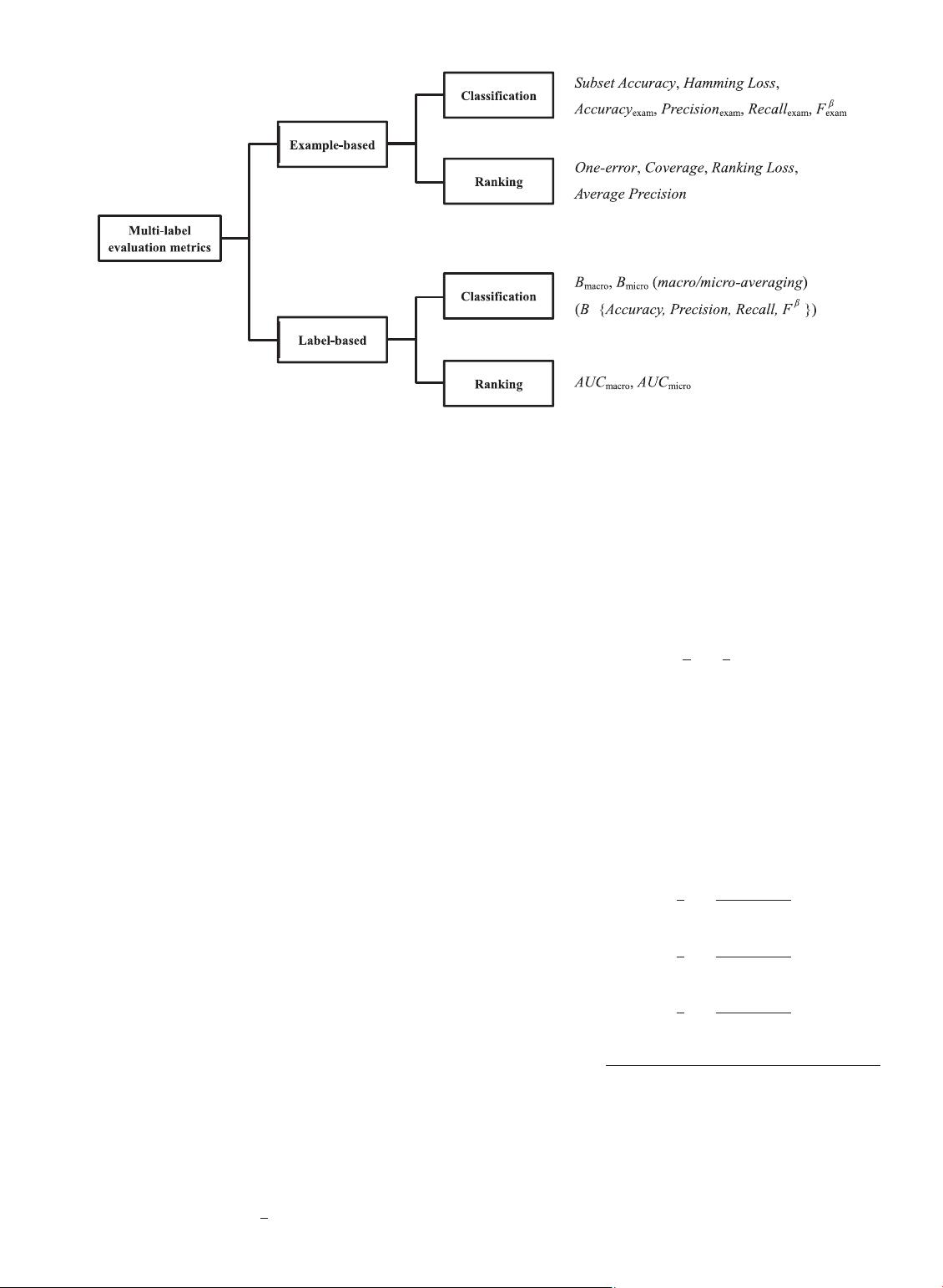
Fig. 1. Summary of major multi-label evaluation metrics.
2.2 Evaluation Metrics
2.2.1 Brief Taxonomy
In traditional supervised learning, generalization perfor-
mance of the learning system is evaluated with conven-
tional metrics such as accuracy, F-measure, area under
the ROC curve (AUC), etc. However, performance eval-
uation in multi-label learning is much complicated than
traditional single-label setting, as each example can be asso-
ciated with multiple labels simultaneously. Therefore, a
number of evaluation metrics specific to multi-label learn-
ing are proposed, which can be generally categorized into
two groups, i.e. example-based metrics [33], [34], [75]and
label-based metrics [94].
Following the notations in Table 1,let
S ={(x
i
, Y
i
)
| 1 ≤ i ≤ p)} be the test set and h(·) be the learned multi-
label classifier. Example-based metrics work by evaluating
the learning system’s performance on each test exam-
ple separately, and then returning the mean value across
the test set. Different to the above example-based met-
rics, label-based metrics work by evaluating the learning
system’s performance on each class label separately, and
then returning the macro/micro-averaged value across all class
labels.
Note that with respect to h(·), the learning system’s gen-
eralization performance is measured from classification per-
spective. However, for either example-based or label-based
metrics, with respect to the real-valued function f(·, ·) which
is returned by most multi-label learning systems as a com-
mon practice, the generalization performance can also be
measured from ranking perspective. Fig. 1 summarizes the
major multi-label evaluation metrics to be introduced next.
2.2.2 Example-based Metrics
Following the notations in Table 1, six example-based clas-
sification metrics can be defined based on the multi-label
classifier h(·) [33], [34], [75]:
• Subset Accuracy:
subsetacc(h) =
1
p
p
i=1
[[ h(x
i
) = Y
i
]] .
The subset accuracy evaluates the fraction of cor-
rectly classified examples, i.e. the predicted label set
is identical to the ground-truth label set. Intuitively,
subset accuracy can be regarded as a multi-label
counterpart of the traditional accuracy metric, and
tends to be overly strict especially when the size of
label space (i.e. q) is large.
• Hamming Loss:
hloss(h) =
1
p
p
i=1
1
q
|h(x
i
)Y
i
|.
Here, stands for the symmetric difference between
two sets. The hamming loss evaluates the fraction
of misclassified instance-label pairs, i.e. a relevant
label is missed or an irrelevant is predicted. Note that
when each example in
S is associated with only one
label, hloss
S
(h) will be 2/q times of the traditional
misclassification rate.
• Accuracy
exam
,Precision
exam
,Recall
exam
,F
β
exam
:
Accuracy
exam
(h) =
1
p
p
i=1
|Y
i
h(x
i
)|
|Y
i
h(x
i
)|
;
Precision
exam
(h) =
1
p
p
i=1
|Y
i
h(x
i
)|
|h(x
i
)|
Recall
exam
(h) =
1
p
p
i=1
|Y
i
h(x
i
)|
|Y
i
|
;
F
β
exam
(h) =
(1 + β
2
) · Precision
exam
(h) · Recall
exam
(h)
β
2
· Precision
exam
(h) + Recall
exam
(h)
.
Furthermore, F
β
exam
is an integrated version of
Precision
exam
(h) and Recall
exam
(h) with balancing fac-
tor β>0. The most common choice is β = 1 which
leads to the harmonic mean of precision and recall.
When the intermediate real-valued function f(·, ·) is
available, four example-based ranking metrics can be
defined as well [75]:
剩余18页未读,继续阅读
2009-10-02 上传
2018-06-05 上传
129 浏览量
2007-12-29 上传
2021-10-21 上传
2023-07-17 上传
2019-09-17 上传
2019-11-22 上传

hywcxq
- 粉丝: 0
- 资源: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- DS1302中文资料
- STC89C52RC 中文数据手册
- Oracle权限管理
- swing 官方网 教程
- FckEditor帮助文档
- i2c协议(中文版).pdf
- ubuntu完美应用
- Packt.Publishing.Smarty.PHP.Template.Programming.and.Applications.Mar.2006.pdf
- ColdFusion_Security
- 配送中心建设的若干问题研究
- thinking in java 中文版
- 字节对齐详解,真的很有用地啊
- DLL(动态链接库)专题
- Dynamips+使用手册+V1.00
- Windows藍屏死機代碼完全解析
- ☆精品资料大放送☆.pdf
