数据仓库ETL设计与实现——IBM讲座解析
需积分: 9 192 浏览量
更新于2024-07-27
收藏 605KB DOCX 举报
"本文主要探讨了数据仓库的ETL过程设计和实现,强调了ETL在数据仓库解决方案中的核心地位。IBM的讲座内容涵盖了ETL的基本原则、设计策略以及在DB2数据仓库中的具体实现方法。"
在设计数据仓库的过程中,ETL(Extract, Transform, Load)是一个至关重要的步骤,它负责从各种数据源提取数据,进行清洗和转换,最后加载到数据仓库中。ETL的过程不仅关乎数据质量,也直接影响着数据仓库的性能和效率。在设计ETL流程时,遵循不改变原始数据的原则是基础,因为任何对数据的修改都可能改变其含义,这需要在开始前与业务方充分沟通确认。
ETL过程设计需要考虑系统的高效性、可扩展性和维护性。一个典型的ETL过程可以分为六个主要模块:提取、验证、清理、集成、聚集和装入。每个模块都有其特定的任务,例如提取是从源系统获取数据,验证确保数据的准确性,清理处理数据的不一致和错误,集成则是将来自不同源的数据合并,聚集用于汇总数据,而装入则将处理后的数据加载到目标仓库。
数据映射是ETL设计的关键部分,它记录了数据转换的规则。ETL数据映射表是一种有效的记录方式,可以帮助设计师明确数据转换逻辑,并与业务团队进行沟通。这种映射表可以按实体和属性级别提供详细信息,以便追踪每个转换的具体操作。
在IBM的DB2数据仓库环境中,DB2 Data Warehouse Center (DWC) 提供了一个可视化工具,用于设计和实施ETL流程。DWC是DB2 Universal Database Data Warehouse Editions的一部分,它增强了性能和可用性,使得ETL过程的实施更加直观和高效。通过DWC,用户可以利用其界面设计复杂的ETL流程,包括数据提取的定义、转换规则的设定以及加载到数据仓库的步骤。
总结来说,设计并实现数据仓库的ETL过程是一项复杂但至关重要的任务,涉及到多个阶段和组件。通过理解ETL的基本原则,合理规划数据映射,以及利用专门的工具如DB2 DWC,可以构建出高效且适应性强的数据仓库解决方案。在整个过程中,始终要关注数据的完整性和业务需求,确保ETL过程能够满足分析和决策支持的需求。
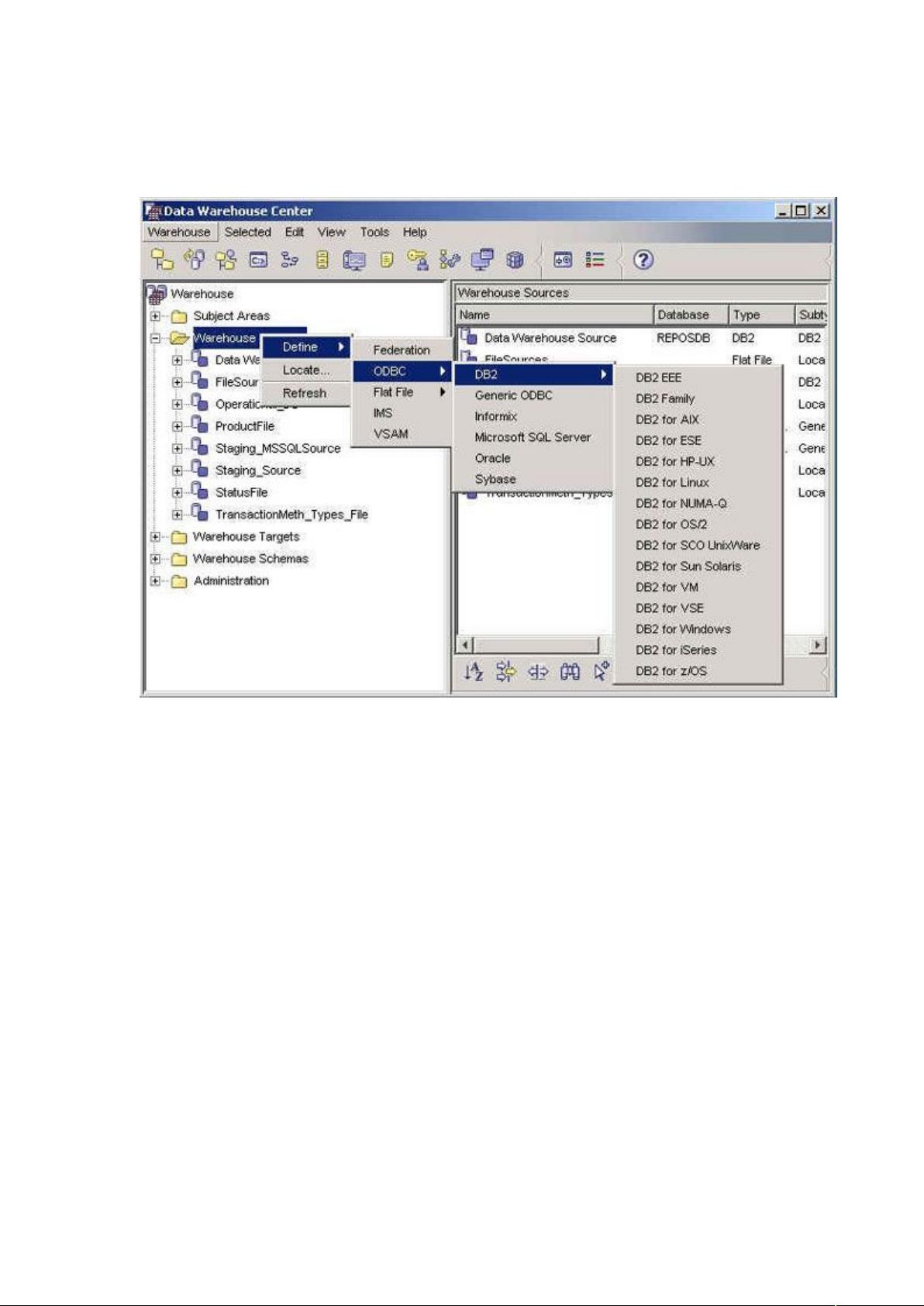
图 4. 仓库数据源
这使得配置从 到所支持数据源的连接变得极
其容易。
在建立到数据源的连接并确定需要使用哪些源表之后,就可以在
中定义 仓库数据源了。如果使用相对仓库代理的远
程源数据库,就必须在包含仓库代理的工作站上注册这些数据库。
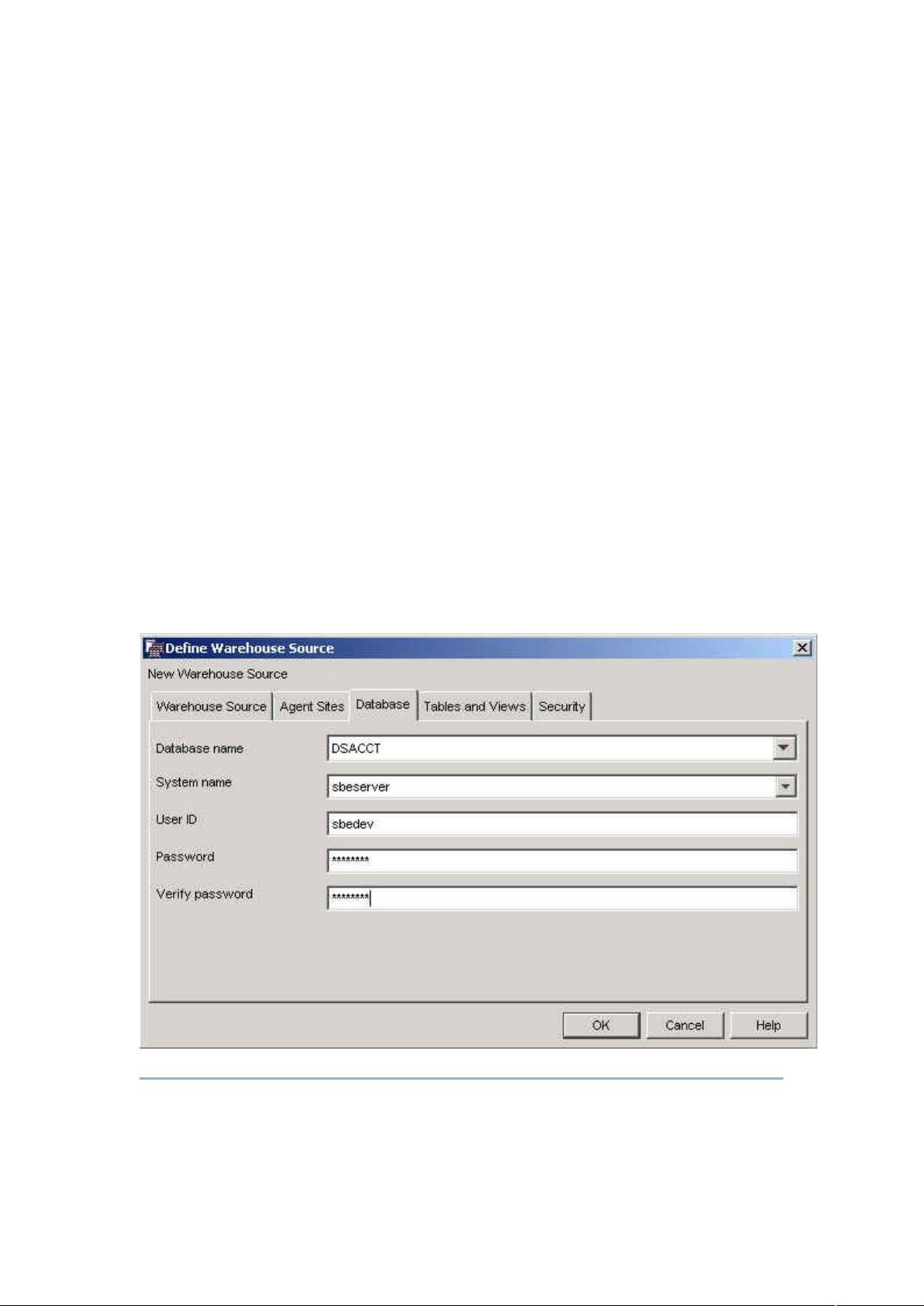
定义仓库数据源的过程会根据数据源类型的不同而有所不同。下面是一个在
中定义关系仓库数据源的例子。
为了在 中定义关系数据源,要执行以下操作:

剩余52页未读,继续阅读
2018-10-07 上传
2019-03-24 上传
2023-04-28 上传
2023-04-28 上传
2024-06-13 上传
2023-07-29 上传
2023-04-03 上传
2024-06-29 上传
2023-04-04 上传

hillva2
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
