Python轻松实现简易Siri:不到一百行代码
20 浏览量
更新于2024-09-01
1
收藏 312KB PDF 举报
"本文主要讲解如何使用Python编写一个简易版的Siri,通过不到一百行的代码实现基础的命令词识别。文章的核心技术包括音频特征提取和动态时间规整(DTW)算法,适合初学者了解语音识别的基本原理和实践方法。"
在Python中实现一个小Siri,首先需要理解语音识别的基本步骤。这个项目的关键在于音频处理和模式匹配。以下是实现过程的详细说明:
1. **特征提取**:
音频特征提取是识别过程的第一步,通常涉及将音频信号转化为可计算的表示。在这个项目中,作者采用了类似于音乐识别的方法,将每一秒的音频分成40段,对每一段进行傅里叶变换。傅里叶变换能够将时域信号转换到频域,从而揭示音频中的频率成分。接着,取模长作为特征值。这种方法简化了特征提取,但可能无法捕捉到复杂的语音特征,如音调和语速变化。
2. **动态时间规整(DTW)算法**:
DTW是一种用于序列比对的算法,特别适用于不同长度的序列。在语音识别中,由于不同人的发音速度和停顿可能不同,DTW可以帮助找到两段音频之间最佳的对齐路径,使得它们的相似度最大化。在DTW中,计算两特征向量之间的距离通常采用欧氏距离,然后构建一个代价矩阵,从起点(1,1)到终点(M1,M2)寻找总代价最小的路径。这一路径代表了最佳的匹配方式。
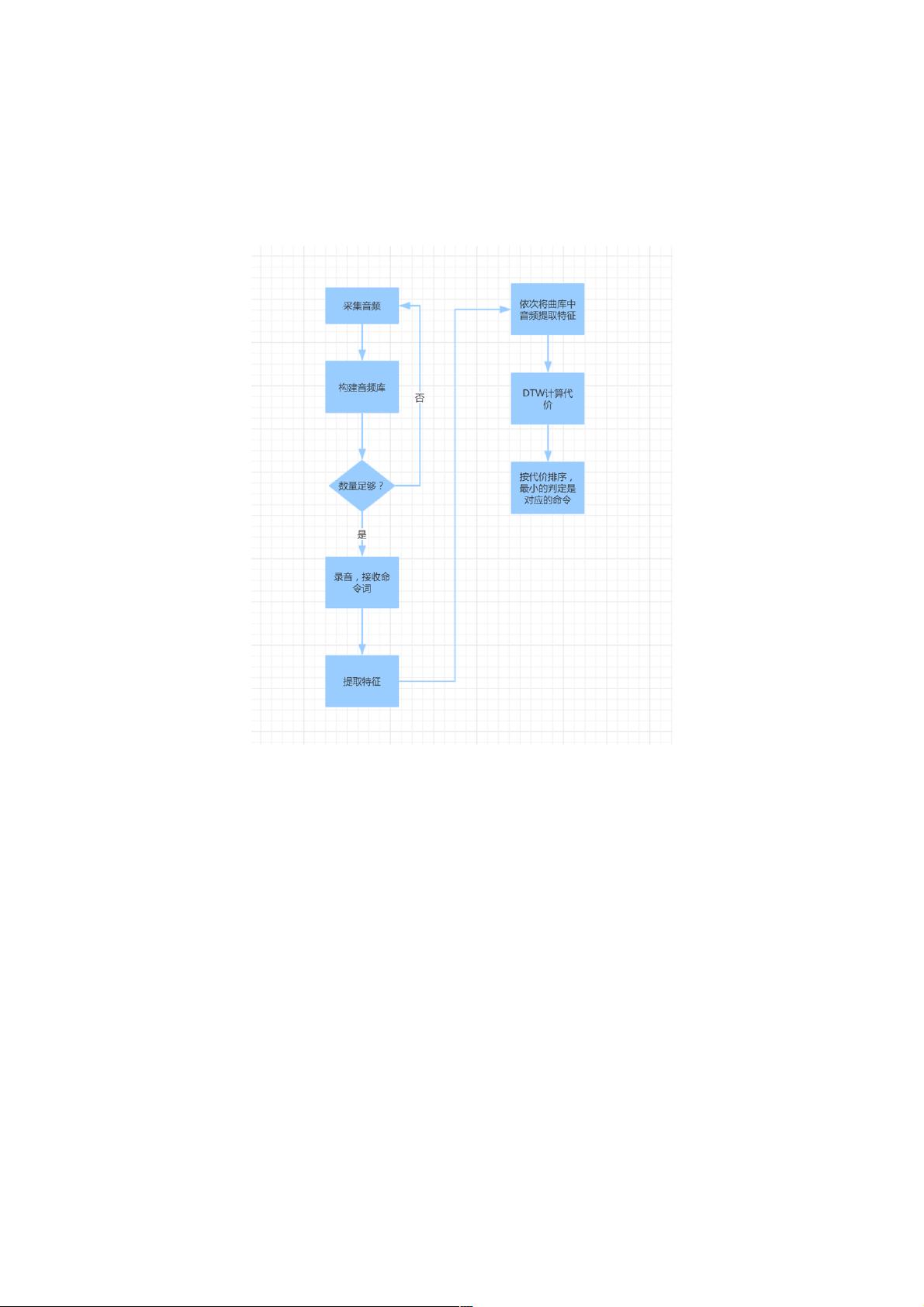
3. **实现流程**:
- 录音并预处理:获取用户的声音输入,可能需要去除背景噪声,调整音量等。
- 特征提取:对录制的音频应用上述方法,得到一系列特征向量。
- 命令模板创建:预先录制并处理命令词,同样得到特征向量作为模板。
- DTW匹配:使用DTW算法,将用户输入的特征向量与所有命令模板进行比对,找出最佳匹配。
- 命令识别:根据匹配结果,识别出最接近的命令词,然后执行相应的操作。
虽然这个简单的Python实现无法与商业级的语音助手如Apple的Siri相媲美,但它提供了一个基础的框架,帮助学习者理解语音识别的基本原理。通过扩展和优化,比如引入更复杂的特征提取技术、深度学习模型,以及更大的训练数据集,可以提高识别准确率和功能。
这个项目是一个有趣的实践,它将理论与实际编程结合,让初学者能够快速上手语音识别技术,并理解其内在的工作机制。同时,这也是一个很好的起点,为进一步深入研究语音识别和自然语言处理技术打下基础。
python利用不到一百行代码实现一个小利用不到一百行代码实现一个小siri
主要介绍了关于python利用不到一百行代码实现了一个小siri的相关资料,文中介绍的很详细,对大家具有一定的参考借鉴价值,需要的朋友们下面来一起看看吧。
前言前言
如果想要容易理解核心的特征计算的话建议先去看看我之前的听歌识曲的文章,传送门://www.jb51.net/article/97305.htm
本文主要是实现了一个简单的命令词识别程序,算法核心一是提取音频特征,二是用DTW算法进行匹配。当然,这样的代码肯定不能用于商业化,大家做出来玩玩娱乐一下还是不错的。
设计思路设计思路
就算是个小东西,我们也要先明确思路再做。音频识别,困难不小,其中提取特征的难度在我听歌识曲那篇文章里能看得出来。而语音识别难度更大,因为音乐总是固定的,而人类说话常常是变化的。
比如说一个“芝麻开门”,有的人就会说成“芝麻开门”,有的人会说成“芝麻开门”。而且在录音时说话的时间也不一样,可能很紧迫的一开始录音就说话了,也可能不紧不慢的快要录音结束了才把这四个字
说出来。这样难度就大了。
算法流程:
特征提取特征提取
和之前的听歌识曲一样,同样是将一秒钟分成40块,对每一块进行傅里叶变换,然后取模长。只是这不像之前听歌识曲中进一步进行提取峰值,而是直接当做特征值。
看不懂我在说什么的朋友可以看看下面的源代码,或者看听歌识曲那篇文章。
DTW算法算法
DTW,Dynamic Time Warping,动态时间归整。算法解决的问题是将不同发音长短和位置进行最适合的匹配。
算法输入两组音频的特征向量: A:[fp1,fp2,fp3,......,fpM1] B:[fp1,fp2,fp3,fp4,.....fpM2]
A组共有M1个特征,B组共有M2个音频。每个特征向量中的元素就是之前我们将每秒切成40块之后FFT求模长的向量。计算每对fp之间的代价采用的是欧氏距离。
设D(fpa,fpb)为两个特征的距离代价。
那么我们可以画出下面这样的图
下载后可阅读完整内容,剩余3页未读,立即下载
2021-02-03 上传
2019-08-13 上传
2024-11-23 上传
2024-11-23 上传

weixin_38701952
- 粉丝: 5
- 资源: 977
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
