利用Hadoop优化分布式搜索引擎:深度剖析与目标实现
版权申诉
133 浏览量
更新于2024-07-02
收藏 1.64MB DOCX 举报
本文档主要探讨了大数据技术背景下分布式搜索引擎的构建与优化,以Hadoop、Nutch和Solr为核心组件。首先,章节一介绍了背景,指出随着互联网信息爆炸式增长,传统的信息搜索面临挑战,需要向具备分布式处理能力的方向发展。Hadoop以其高效的数据处理能力、高扩展性和安全性成为解决方案的关键。
Hadoop的优势体现在:
1. 数据处理效率高:Hadoop集群能够显著提升数据处理速度,特别是对于大规模数据,其优势更为明显。
2. 高度扩展性:Hadoop设计允许轻松扩展集群以适应不断增长的数据量,不会破坏现有集群的性能。
3. 安全可靠:Hadoop的数据冗余机制确保数据的备份和恢复,即使在单点故障情况下也能保持服务连续性。
4. Nutch的功能丰富:除了基础的网页抓取,Nutch还能解析网页、建立链接数据库、网页评分和索引构建,增强了系统的实用性。
5. 插件机制:Nutch的插件系统增强了系统的灵活性和可维护性,便于开发人员定制化需求。
研究目标集中在深入分析分布式搜索引擎,特别是针对Hadoop和Nutch的底层技术进行研究。这包括:
- 深入剖析Hadoop的分布式文件系统HDFS和MapReduce编程模型,理解其在搜索引擎中的应用。
- 研究Nutch的架构和技术细节,尤其是其插件系统,如开发支持表单登录的protocol-httpclient插件和改进搜索主题相关度的信息解析插件,甚至实现了Google排序算法的MapReduce版本。
系统功能方面,分为两个主要模块:
1. 本地资源解析模块:针对PDF、Word和Excel等本地文件内容进行解析,将其按主题分类并添加到索引中,方便用户根据特定主题进行搜索。
2. 搜索模块:用户可以通过关键词查询索引,系统会返回与查询关联度最高的前n个文档,提供高效且主题相关的搜索结果。
本文旨在通过优化分布式搜索引擎,特别是利用Hadoop、Nutch和Solr的组合,解决海量信息检索中的效率和相关度问题,提升用户体验。通过深入技术研究和实际功能设计,本文为构建高效、稳定和灵活的分布式信息检索系统提供了有价值的技术参考。
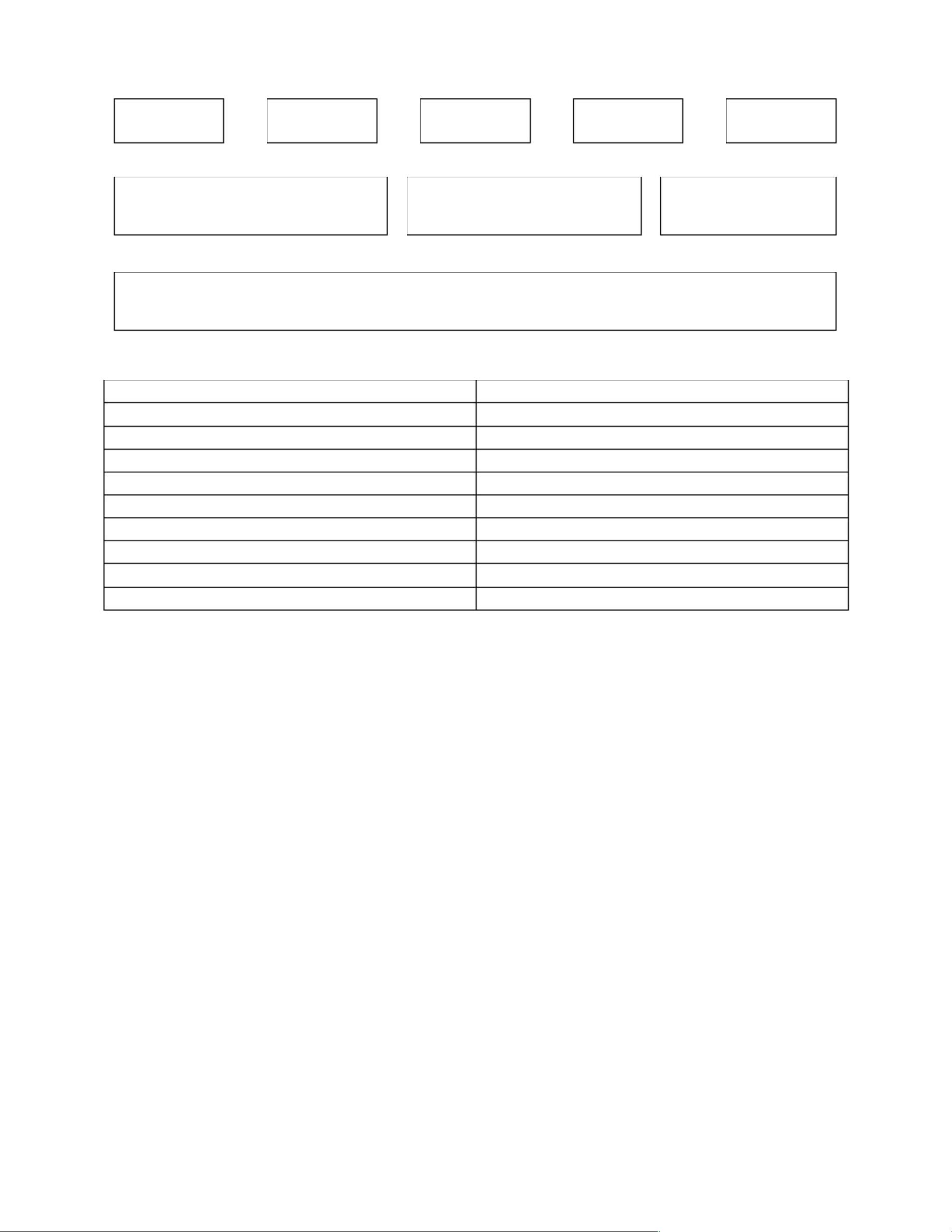
Hbase分布式数据库
Pig数据流语言
Hive数据仓库
Mahout数据挖掘库
Avro远程过程调用
MapReduce
分布式处理模型
HDFS
分布式文件系统
ZooKeeper
分布式协同系统
Hadoop Common
Hadoop项目的核心
图 Hadoop 框架图
功能
Hadoop 系统核心,提供子项目的基本支持
实现高吞吐的分布式存储
MapReduce
HBase
执行分布式并行计算
一个可扩展的分布式数据库系统
为并行计算提供数据流语言和执行框架
提供类 SQL 语法进行数据查询的数据仓库
提供分布式锁等
Pig
Hive
ZooKeeper
Mahout
Arvo
一个大规模机器学习和数据挖掘库
Hadoop 的 RPC(远程过程调用)方案
表 Hadoop 子项目功能介绍
5
剩余31页未读,继续阅读
2023-08-04 上传
174 浏览量
2022-06-20 上传
168 浏览量
2022-06-21 上传
109 浏览量
2022-06-27 上传
233 浏览量
299 浏览量

xxpr_ybgg
- 粉丝: 6805
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- ISO/IEC 9899 C 语言标准
- 一些著名的大公司面试题目
- JAVA笔试面试题(值得一看)
- zigbee的英文版
- Cutting Edge Java Game Programming.pdf
- 北邮IT项目管理案例课件
- php完整教程PDF
- sap basis 操作指南
- 计算机端口介绍计算机端口介绍
- ubuntupocketguide-v1-1随身指南
- SOA using Open ESB, BPEL, and NetBeans
- 张太国的BlackBerry开发者指南高级篇
- 张太国的BlackBerry开发者指南基础篇
- Eclipse for BlackBerry环境搭配
- Java 资料 个人总结
- ubuntu8.04速成手册1.0.
