CentOS下Hadoop集群安装详解与体系结构
 已收录资源合集
已收录资源合集
需积分: 9 127 浏览量
更新于2024-07-23
收藏 1.26MB PDF 举报
Hadoop集群安装教程深入解析
本文主要介绍了如何在CentOS操作系统下搭建Hadoop集群,Hadoop作为一个开源的分布式计算平台,由Apache软件基金会支持,特别强调了其核心组件Hadoop Distributed File System (HDFS) 和 MapReduce。HDFS负责提供分布式文件系统服务,通过NameNode和DataNode来管理和存储数据,NameNode作为主服务器,负责命名空间管理和客户端访问控制,而DataNode则负责实际的数据存储。
另一方面,MapReduce是Hadoop实现分布式计算和任务处理的重要模块,它由JobTracker(主节点)和TaskTracker(从节点)组成。JobTracker负责任务调度、监控和重试,而TaskTracker则执行分配的任务。HDFS与MapReduce紧密协作,HDFS为MapReduce提供文件操作和存储的支持,MapReduce则基于HDFS进行任务分发、跟踪和执行,最终汇总结果。
构建的Hadoop集群包括一个Master节点和三个Slave节点,这些节点通过局域网连接,确保节点间通信畅通。集群的具体配置可以在第二期的内容中找到,涉及节点的IP地址和机器名称,如Master节点的IP地址未在文中给出,但可以推测是在这个列表中。
在进行Hadoop集群安装时,需要确保所有节点的硬件环境、网络配置以及必要的软件包如Java、SSH等都已经正确设置。安装过程可能涉及到下载Hadoop源代码、编译、配置环境变量、启动守护进程以及调整参数等步骤。此外,由于Hadoop集群的部署和管理涉及到分布式系统特性,还需要对集群的负载均衡、容错机制和数据一致性有深入理解。
通过本文,读者将了解到如何在CentOS环境下搭建Hadoop集群的基本架构和配置流程,这对于理解和应用大数据处理技术具有重要的参考价值。后续的系列文章可能会进一步探讨Hadoop的高级特性、性能优化和故障排查等内容。

创建时间:2012/2/26 修改时间:2012/3/17 修改次数:1
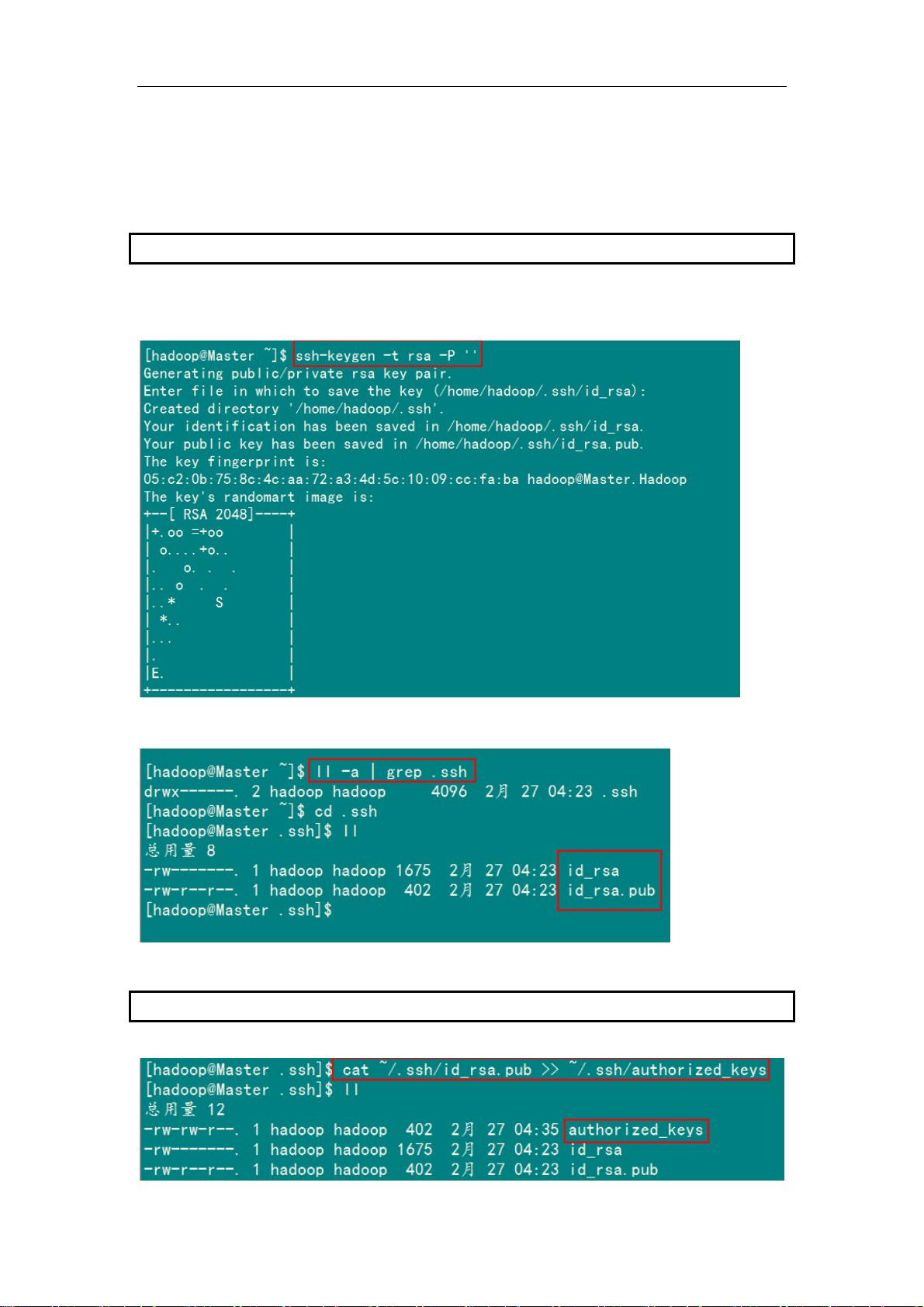
2、SSH无密码验证配置
Hadoop 运行过程中需要管理远端 Hadoop 守护进程,在 Hadoop 启动以后,NameNode
是通过 SSH(Secure Shell)来启动和停止各个 DataNode 上的各种守护进程的。这就必须在
点之间执行指令的时候是不需要输入密码的形式,故我们需要配置 SSH 运用无密码公钥
登录并启动 DataName 进程,同样原理,
ataNode 上也能使用 SSH 无密码登录到 NameNode。
节
认证的形式,这样 NameNode 使用 SSH 无密码
D
2.1 安装和启动SSH协议
在“Hadoop 集群(第 1 期)”安装 CentOS6.0 时,我们选择了一些基本安装包,所以我
们需要两个服务:ssh 和 rsync 已经安装了。可以通过下面命令查看结果显示如下:
rpm –qa | grep openssh
rpm –qa | grep rsync
假设没有安装 ssh 和 rsync,可以通过下面命令进行安装。
yum install ssh 安装 SSH 协议
yum install rsync (rsync 是一个远程数据同步工具,可通过 LAN/WAN 快速同步多台主机间
的文件)
service sshd restart 启动服务
确保所有的服务器都安装,上面命令执行完毕,各台机器之间可以通过密码验证相互登。
.2 配置Master无密码登录所有Salve
r(Nam
eNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器
时,需要在 Master 上生成一个密钥对,包括一个公钥和一
私钥,而后将公钥复制到所有的 Slave 上。当 Master 通过 SSH 连接 Salve 时,Salve 就会
数之后再用私钥解密,并将解密数回传给 Slave,Slave 确认解密数无误之后就允许 Master
2
1)SSH 无密码原理
Maste
Salve(DataNode | Tasktracker)上
个
生成一个随机数并用 Master 的公钥对随机数进行加密,并发送给 Master。Master 收到加密
河北工业大学——软件工程与理论实验室 编辑:虾皮
7
剩余43页未读,继续阅读
2014-08-04 上传
2017-04-07 上传
2024-09-13 上传
2013-11-01 上传
2018-10-19 上传
2015-12-04 上传
2023-09-07 上传

blueoceanliang
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
