挖掘高价值模式:理论、算法与应用指南
需积分: 18 17 浏览量
更新于2024-07-17
收藏 12.31MB PDF 举报
《高效实用模式挖掘:理论、算法与应用》是一本专著,收录在"Studies in Big Data"系列第51卷中,由Philippe Fournier-Viger、Jerry Chun-Wei Lin、Roger Nkambou、Bay Vo和Vincent S. Tseng共同编辑。本书于2019年1月19日首次出版,是针对大数据背景下高重要性模式(即高效实用模式)发现的深入研究。高效实用模式挖掘关注的是具有高价值或频繁度的项集和序列模式,对于商业智能、市场分析等领域具有重要意义。
该书共分为十二章,其中七章是对高效率模式挖掘主要子领域的概述,包括:
1. 项集挖掘:研究数据集中频繁出现的项目组合。
2. 序列模式挖掘:处理时间序列数据中的模式发现。
3. 大数据模式挖掘:针对大规模数据集的高效算法和方法。
4. 元启发式方法:利用启发式策略优化模式挖掘过程。
5. 隐私保护模式挖掘:兼顾数据隐私和模式分析之间的平衡。
6. 模式可视化:通过图表展示复杂模式,便于理解和解释。
另外五章则聚焦于关键技术和应用,如:
- 发现简洁表示法:用更精炼的形式表达模式。
- 规则和结构化模式:揭示数据中的潜在规律和结构。
《高效实用模式挖掘》不仅涵盖了理论基础,还介绍了核心算法以及实际应用案例,包括客户交易数据分析和序列数据挖掘。书中提到的软件和研究机会反映了当前领域的发展趋势。作为"Studies in Big Data"系列的一部分,这本书旨在快速传播大数据领域的新进展,并促进工程、计算机科学、物理学、经济学和生命科学等领域的交叉融合。
对于那些对数据挖掘、业务分析和大数据技术感兴趣的读者,这是一本不可或缺的参考书籍,可以帮助他们理解如何从海量数据中提取有价值的信息,以支持决策制定和优化业务流程。价格方面,该书标价为$159.99,体现了其专业深度和实用性。

A Survey of High Utility Itemset Mining 7
Table 5 The high utility itemsets for mi nut il = 25
Itemset Utility Itemset Utility Itemset Utility
{a, c} 28 {b, c, d} 34 {b, d, e} 36
{a, c, e} 31 {b, c, d, e} 40 {b, e} 31
{a, b, c, d, e} 25 {b, c, e} 37 {c, e} 27
{b, c} 28 {b, d} 30
Table 6 The quantitative
transaction database
corresponding to the database
of Table1
TID Transaction
T
0
(a, 1), (b, 1), (c, 1), (d, 1), (e, 1)
T
1
(b, 1), (c, 1), (d, 1), (e, 1)
T
2
(a, 1), (c, 1), (d, 1)
T
3
(a, 1), (c, 1), (e, 1)
T
4
(b, 1), (c, 1), (e, 1)
Table 7 External utility
values for the database of
Table 6
Item External utility
a 1
b 1
c 1
d 1
e 1
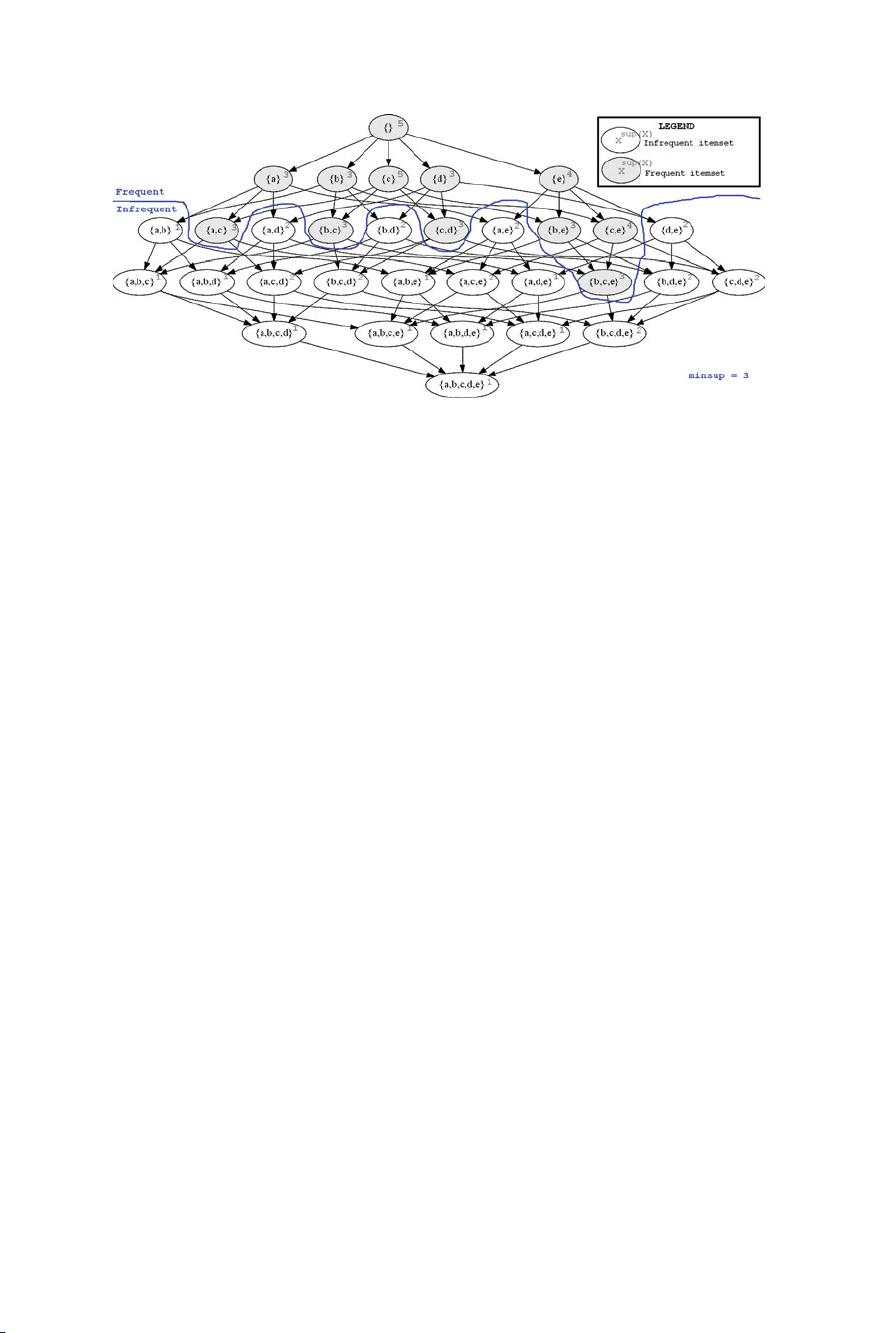
discovering high utility itemsets can also be used to discover frequent itemsets in a
transaction database. To do that, the following steps can be applied:
1. The transaction database is converted to a quantitative transaction database. For
each item i ∈ I , the external utility value of i issetto1,thatis p(i) = 1 (to indicate
that all items are equally important). Moreover, for each item i and transaction
T
c
,ifi ∈ T
c
,setq(i, T
c
) = 1. Otherwise, set q(i, T
c
) = 0.
2. Then a high utility mining algorithm is applied on the resulting quantitative trans-
action database with mi nut il set to mi nsup, to obtain the frequent itemsets.
For example, the database of Table 1 can be transformed in a quantitative database.
The result is the transaction database of Tables 6 and 7. Then, frequent itemsets can
be mined from this database using a high utility itemset mining algorithm. How-
ever, although a high utility itemset mining algorithm can be used to mine frequent
itemsets, it may be preferable to use frequent itemset mining algorithms when per-
formance is important as these latter are optimized for this task.



剩余342页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2009-08-14 上传
101 浏览量
2010-11-11 上传
2015-03-20 上传
2021-02-07 上传
2021-06-30 上传

THESUMMERE
- 粉丝: 23
- 资源: 328
 我的内容管理
展开
我的内容管理
展开







最新资源
- 搜索引擎-原理、技术与系统.pdf
- mysql视图简介.pdf
- SEO Book By:Google
- iphone cook book
- MIMO及智能天线技术简介
- Quick.Recipes.On.Symbian.OS-Mastering.CPP.Smartphone.Development
- 进销存管理系统(开发文档)
- Tornado使用指南
- 基于Delphi技术的图书管理系统设计
- Oracle9i SQL Reference官方文档
- UNIX 环境高级编程
- 需求规格说明书(Volere版)
- ExtJs中文帮助文档
- VMwareWorkstation6基本使用
- 华南理工电子电子考研试卷
- 2008 acm 个人赛
