Apache Flink:大数据流处理框架详解
需积分: 48 33 浏览量
更新于2024-07-09
收藏 4.73MB DOCX 举报
"尚硅谷的Flink教程文档详细介绍了Flink的大数据处理技术和核心特性。"
Apache Flink是一个强大的开源流处理框架,源自于Stratosphere项目,该项目由多所大学共同研发并在2014年捐赠给Apache软件基金会,成为其顶级项目。Flink的名字来源于德语中的“快速”和“灵巧”,象征着其高效和灵活的处理能力。项目标志是一只具有Apache风格的红棕色松鼠,寓意其快速和灵活的特性。
Flink的核心理念在于提供分布式、高性能、高可用和精确的流处理解决方案。它能够处理无界和有界数据流,并且设计目标是在各种集群环境中以内存计算速度进行大规模处理。这意味着Flink能够在不影响性能的情况下处理大规模实时数据流。
Flink的一个显著特点是其事件驱动型(Event-driven)架构。这种模式下,应用从事件流中获取数据,基于事件触发计算和状态更新。与之对比,Spark Streaming采用微批次处理,而不是真正的事件驱动。事件驱动型应用更适合实时响应和状态管理,如消息队列(如Kafka)中的应用。
Flink在处理流和批上有独特的世界观。批处理处理有界数据,适合离线分析;而流处理则针对无界数据,适用于实时计算。在Spark中,流被视为一系列小批次,而在Flink中,无论是离线数据还是实时数据,都被视为流动的数据流。无界数据流代表持续不断的数据源,需要持续处理,而有界数据流则有明确的开始和结束点。
Flink提供了一种统一的API来处理这两种类型的数据流,允许开发者在同一个平台上进行批处理和流处理。这使得Flink在处理实时数据时能够保持低延迟,同时具备处理历史数据的能力,从而实现近实时分析。
Flink的关键特性还包括容错机制,它可以确保在分布式环境中处理数据的准确性和一致性。此外,Flink还支持状态管理和窗口操作,使得开发者能够轻松管理和操作处理过程中积累的状态,以及按时间或事件数量定义的数据窗口。
Flink是一个强大且灵活的大数据处理工具,特别适用于需要实时分析和事件驱动的应用场景。通过理解Flink的核心概念和技术,开发者可以构建出高性能、实时响应的流处理系统。
4)
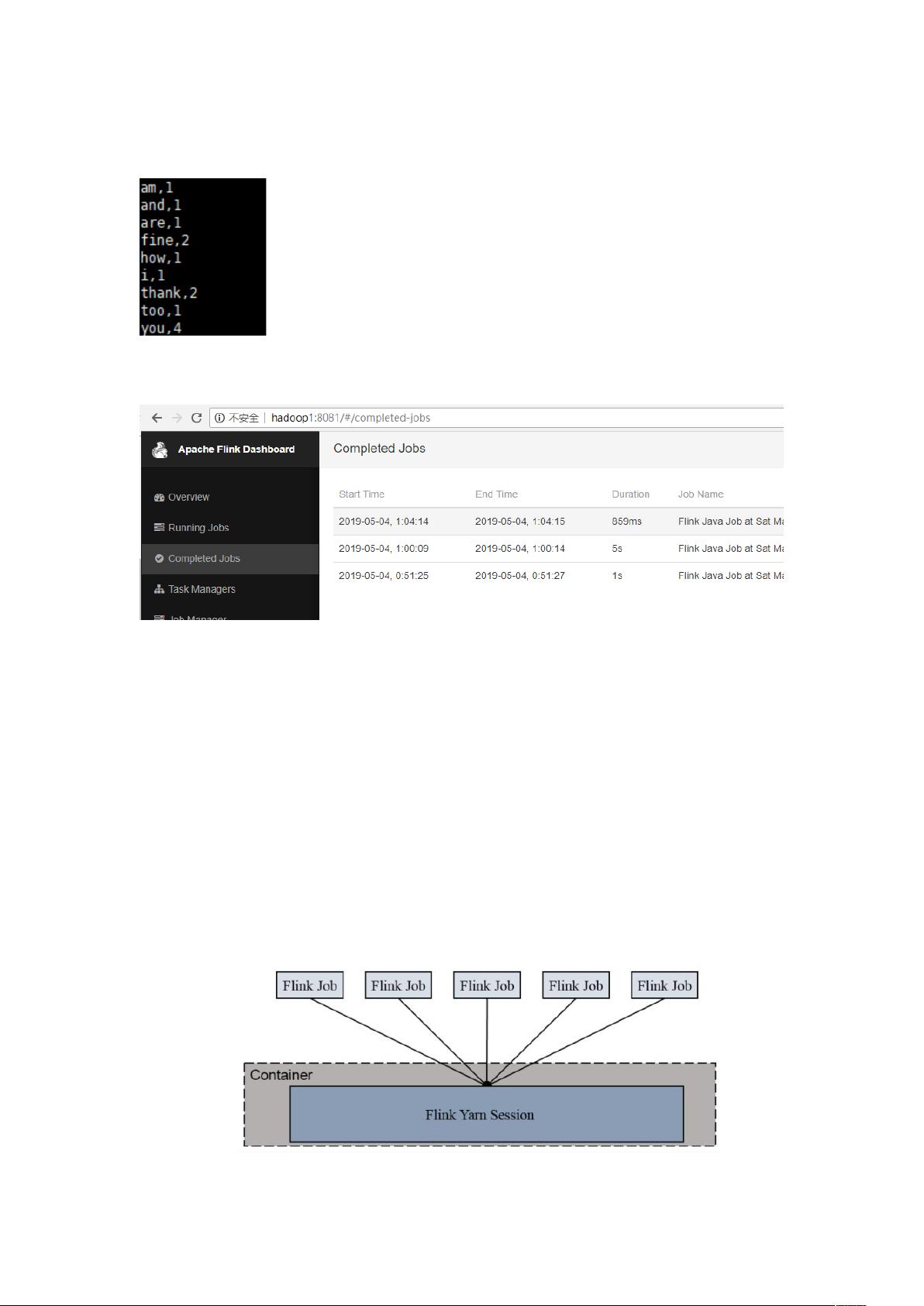
到目标文件夹中查看计算结果
注意:计算结果根据会保存到 的机器下,不会在 #' 下。
5)
在
webui
控制台查看计算过程
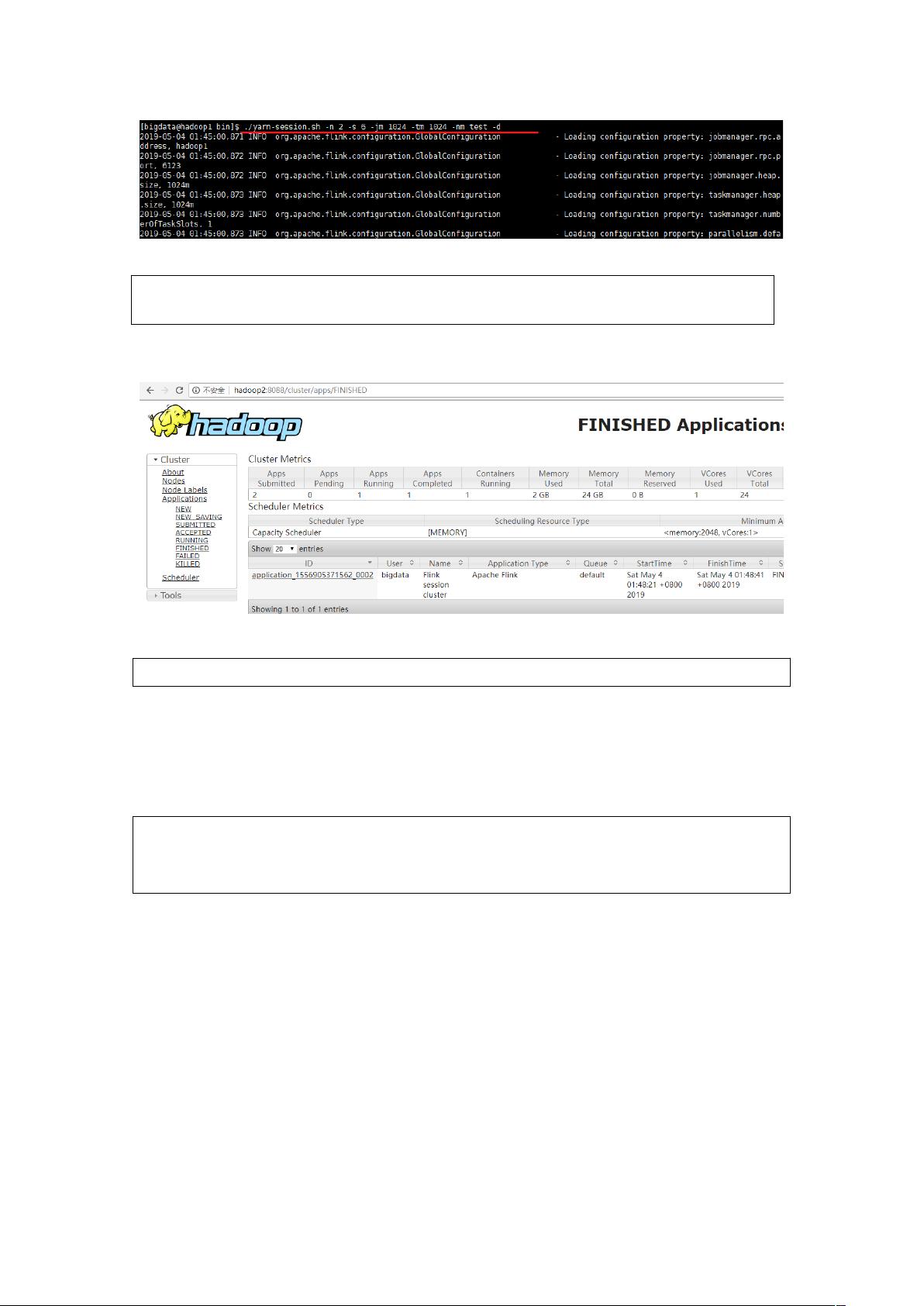
3.2 Yarn 模式
以 8 模式部署 任务时,要求 是有 9% 支持的版本,9% 环
境需要保证版本在 3 以上,并且集群中安装有 9 服务。
78
提供了两种在 ) 上运行的模式,分别为 (" 和 (:'("
模式。
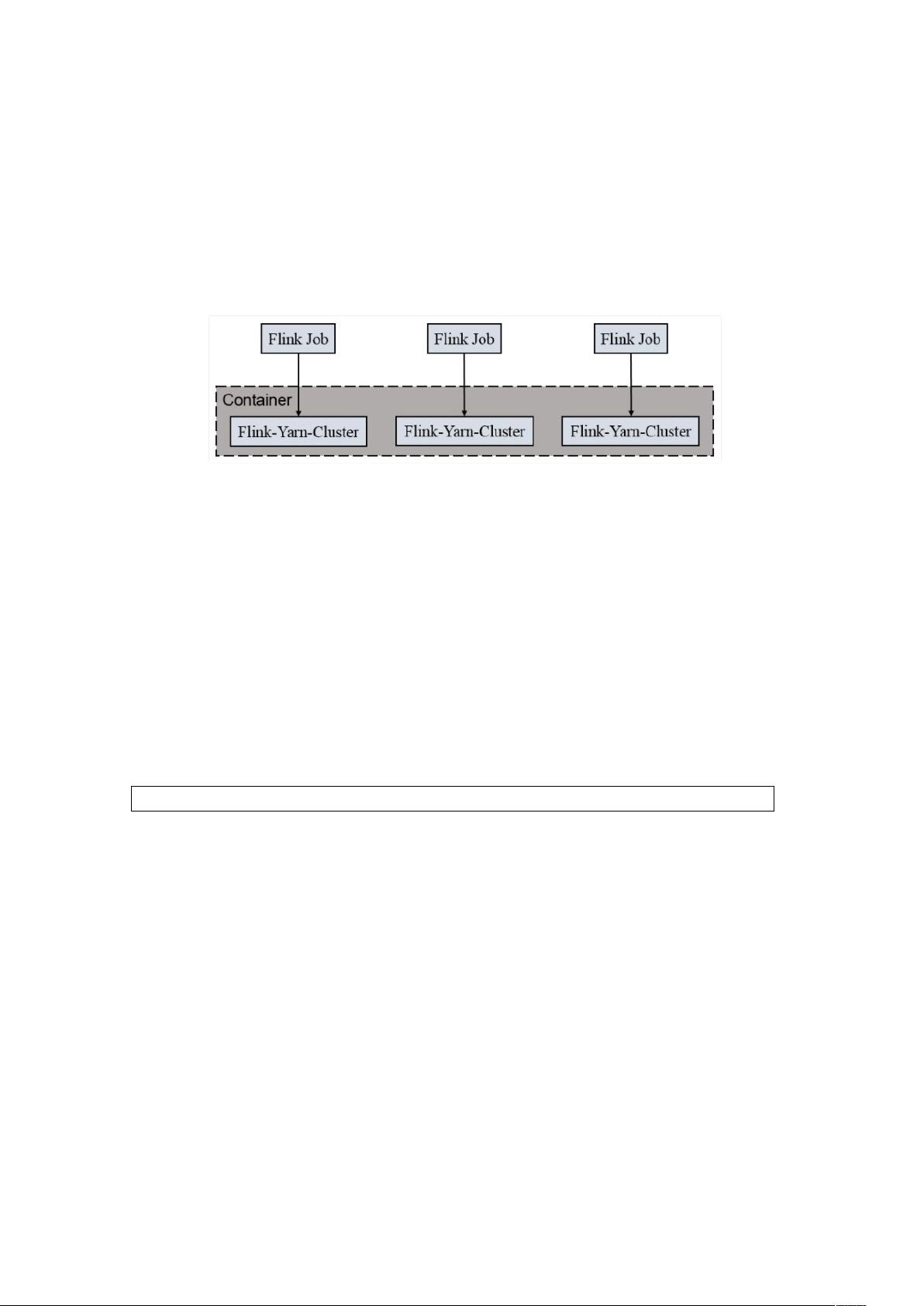
1) Session-cluster 模式:
剩余63页未读,继续阅读
2022-08-08 上传
2019-12-18 上传
2020-11-23 上传
2024-03-06 上传
2021-12-05 上传
点击了解资源详情
2022-04-10 上传
2020-07-16 上传
2022-03-22 上传

时时刻刻看着自己的心
- 粉丝: 43
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
