Kafka消息可靠性解析:存储、复制与保证
25 浏览量
更新于2024-08-29
收藏 571KB PDF 举报
"kafka数据可靠性深度解读"
Kafka是一个由LinkedIn开发并后来成为Apache软件基金会项目的分布式消息系统,因其可扩展性和高吞吐率而广受欢迎。它使用Scala编程语言编写,现已被许多开源分布式处理系统如Cloudera、Apache Storm、Spark等集成。在互联网行业中,Kafka作为消息中间件扮演着关键角色,唯品会等企业也采用了它。确保Kafka的数据可靠性至关重要,涉及消息传输的精确性、存储的准确性和消费的正确性。
Kafka的架构由Producer、Broker、Consumer Group和Zookeeper集群组成。Producer通过push模式将消息发送到Broker,而Consumer则通过pull模式从Broker获取并消费消息。Zookeeper负责集群配置管理、leader选举以及Consumer Group变化时的rebalance操作。
在Kafka中,消息被组织成topics,每个topic可被划分为多个partitions。partitions是以append-only log的形式存储,消息的顺序写入(基于offset)保证了高效的性能。分区内的消息根据特定的partition规则被分配到不同的partition,这有助于负载均衡和提高系统性能。
Kafka的数据可靠性主要体现在以下几个方面:
1. **复制机制**:每个partition在多个broker之间都有副本(replicas),其中一个被选为leader,其余为followers。如果leader失败,followers中的一台将自动晋升为新的leader,确保服务不间断。
2. **同步原理**:followers通过fetch请求从leader同步数据,确保所有副本保持一致。Kafka提供了不同的同步策略(例如,同步复制和异步复制),在延迟和容错性之间取得平衡。
3. **持久性保证**:Kafka将消息写入磁盘,并且可以通过设置保留策略(例如,基于时间或大小)来控制消息的生命周期。即使在broker故障后,数据也可以从副本中恢复。
4. **消费者offset管理**:每个Consumer Group维护自己的offset,记录了每个partition的消费进度。这样,即使consumer失败,从上次已知的offset恢复消费也能保证不丢失消息。
5. **错误恢复**:Kafka提供幂等性和Exactly-Once语义,通过幂等producer和事务特性,确保消息在故障情况下不会被重复处理。
6. **可用性和一致性**:通过Zookeeper协调,Kafka可以在保证数据一致性的同时,实现高可用性。在进行rebalance时,可以避免数据丢失或重复消费。
通过深入理解Kafka的这些机制,我们可以更好地评估和优化系统的可靠性。此外,基准测试(benchmark)也是验证和提升Kafka高可靠性的重要手段,通过实际的性能测试,可以发现并解决潜在问题,进一步增强系统的稳定性。
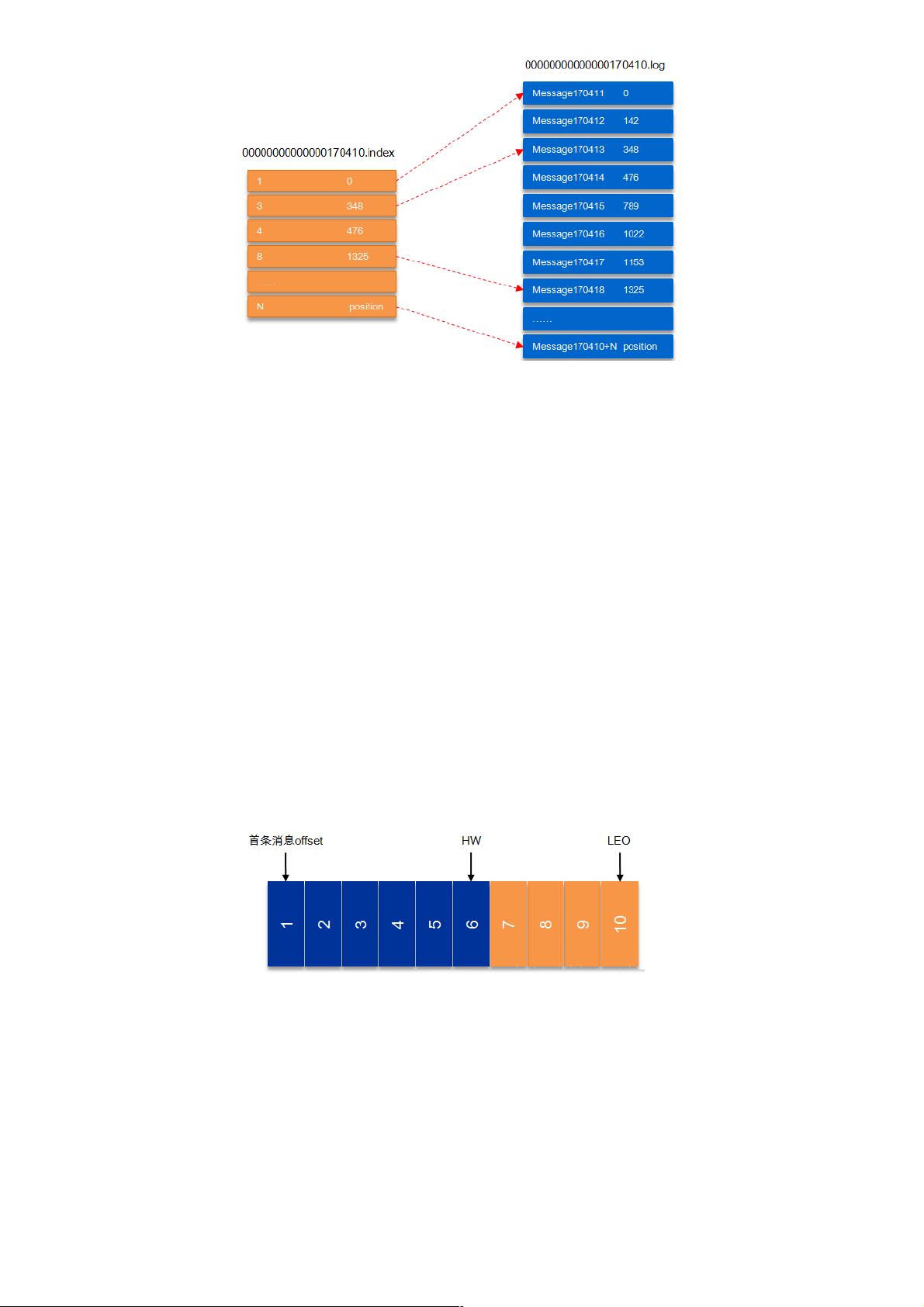
如上图,“.index”索引文件存储大量的元数据,“.log”数据文件存储大量的消息,索引文件中的元数据指向对应数据文件中
message的物理偏移地址。其中以“.index”索引文件中的元数据[3, 348]为例,在“.log”数据文件表示第3个消息,即在全局
partition中表示170410+3=170413个消息,该消息的物理偏移地址为348。
那么如何从partition中通过offset查找message呢?
以上图为例,读取offset=170418的消息,首先查找segment文件,其中00000000000000000000.index为最开始的文件,第二
个文件为00000000000000170410.index(起始偏移为170410+1=170411),而第三个文件为
00000000000000239430.index(起始偏移为239430+1=239431),所以这个offset=170418就落到了第二个文件之中。其他
后续文件可以依次类推,以其实偏移量命名并排列这些文件,然后根据二分查找法就可以快速定位到具体文件位置。其次根据
00000000000000170410.index文件中的[8,1325]定位到00000000000000170410.log文件中的1325的位置进行读取。
要是读取offset=170418的消息,从00000000000000170410.log文件中的1325的位置进行读取,那么怎么知道何时读完本条
消息,否则就读到下一条消息的内容了?
这个就需要联系到消息的物理结构了,消息都具有固定的物理结构,包括:offset(8 Bytes)、消息体的大小(4 Bytes)、
crc32(4 Bytes)、magic(1 Byte)、attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes)等
等字段,可以确定一条消息的大小,即读取到哪里截止。
3.2 复制原理和同步方式
Kafka中topic的每个partition有一个预写式的日志文件,虽然partition可以继续细分为若干个segment文件,但是对于上层应用
来说可以将partition看成最小的存储单元(一个有多个segment文件拼接的“巨型”文件),每个partition都由一些列有序的、不
可变的消息组成,这些消息被连续的追加到partition中。
上图中有两个新名词:HW和LEO。这里先介绍下LEO,LogEndOffset的缩写,表示每个partition的log最后一条Message的位
置。HW是HighWatermark的缩写,是指consumer能够看到的此partition的位置,这个涉及到多副本的概念,这里先提及一
下,下节再详表。
言归正传,为了提高消息的可靠性,Kafka每个topic的partition有N个副本(replicas),其中N(大于等于1)是topic的复制因子
(replica fator)的个数。Kafka通过多副本机制实现故障自动转移,当Kafka集群中一个broker失效情况下仍然保证服务可
用。在Kafka中发生复制时确保partition的日志能有序地写到其他节点上,N个replicas中,其中一个replica为leader,其他都为
follower, leader处理partition的所有读写请求,与此同时,follower会被动定期地去复制leader上的数据。
如下图所示,Kafka集群中有4个broker, 某topic有3个partition,且复制因子即副本个数也为3:
剩余12页未读,继续阅读
2018-09-21 上传
2020-01-09 上传
2020-01-08 上传
2021-02-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38599430
- 粉丝: 0
- 资源: 886
 我的内容管理
展开
我的内容管理
展开







最新资源
- MCS51单片机的寻址
- 用Flash制作选择题模板
- oracle10的优化
- Windows Communication Foundation 入门.pdf
- 中大ACM题库的分类
- datasheet-lm3s1138-zh_cn
- 基于ICL8038函数信号发生器的设计
- Makefile中文教程
- 杭电ACM1002解题答案
- Mean Shift图像分割的快速算法
- vxwork 6.6版本的bsp开发指导说明文档
- Windows嵌入式开发系列课程(3):WindowsCE.NET USB驱动开发基础.pdf
- Java反射机制Demo
- MyEclipse+6+Java开发教程
- 无废话JavaScript和html学习笔记
- 计算机专业软件工程的复习范围
