Scrapy深度解析:爬虫架构与工作流程详解
 已收录资源合集
已收录资源合集
需积分: 0 143 浏览量
更新于2024-08-04
收藏 830KB DOCX 举报
Scrapy是一个强大的Python网络爬虫框架,用于高效地抓取网站数据。本文将深入探讨Scrapy的架构以及各个组件的作用。
**Scrapy架构**
Scrapy的核心组成部分包括:
1. **引擎(Engine)**: 是Scrapy的框架核心,负责管理整个爬虫的数据流程。它接收来自Spiders的初始请求,调度和控制整个爬取过程。
2. **调度器(Scheduler)**: 是Scrapy的重要模块,它是一个优先级队列,负责存储待抓取的URL。它根据策略(如随机或优先级排序)决定下一次要抓取哪个URL,并防止重复抓取。
3. **下载器(Downloader)**: 运行在Twisted异步网络库之上,负责下载网页内容。当引擎发送请求时,下载器会处理这些请求,确保快速且稳定地获取网页。
4. **爬虫(Spiders)**: 用户编写的主要部分,它们从特定网页中提取所需信息(Item)并可能发现新的链接以进行进一步抓取。Spiders是Scrapy执行实际抓取任务的主体。
5. **项目管道(Pipeline)**: 用于处理爬虫获取的实体,例如清洗数据、验证有效性、存储到数据库或文件等,确保数据的完整性和一致性。
6. **下载器中间件(Downloader Middlewares)**: 在引擎和下载器之间,处理请求和响应,可进行诸如重定向、代理、错误处理等额外操作。
7. **爬虫中间件(Spider Middlewares)**: 处理爬虫响应和请求,如数据预处理或后处理,增强爬虫的灵活性和扩展性。
8. **调度中间件(Scheduler Middlewares)**: 位于引擎和调度器之间,对请求和响应进行过滤或修改,可能影响爬取策略。
**运行流程**
Scrapy的运行流程可以概括为以下步骤:
1. **初始化与请求获取**:引擎从Spiders获取起始的抓取请求。
2. **调度与请求管理**:引擎将请求放入调度器,然后请求调度器提供下一个要抓取的URL。
3. **请求调度**:调度器返回下一个URL给引擎,请求按照预定策略进行抓取。
4. **下载器处理**:下载器中间件处理请求后,通过下载器下载网页,`process_request()`函数在此阶段执行。
5. **页面下载**:下载器接收到响应后,中间件处理下载结果,然后发送给引擎。
6. **响应处理**:引擎将响应传递给爬虫中间件,然后转发给项目管道进行进一步处理。
通过这些组件的协同工作,Scrapy构建了一个高度灵活且可扩展的爬虫系统,适用于大规模数据抓取和数据分析项目。理解这些组件的工作原理对于有效地使用Scrapy框架至关重要。
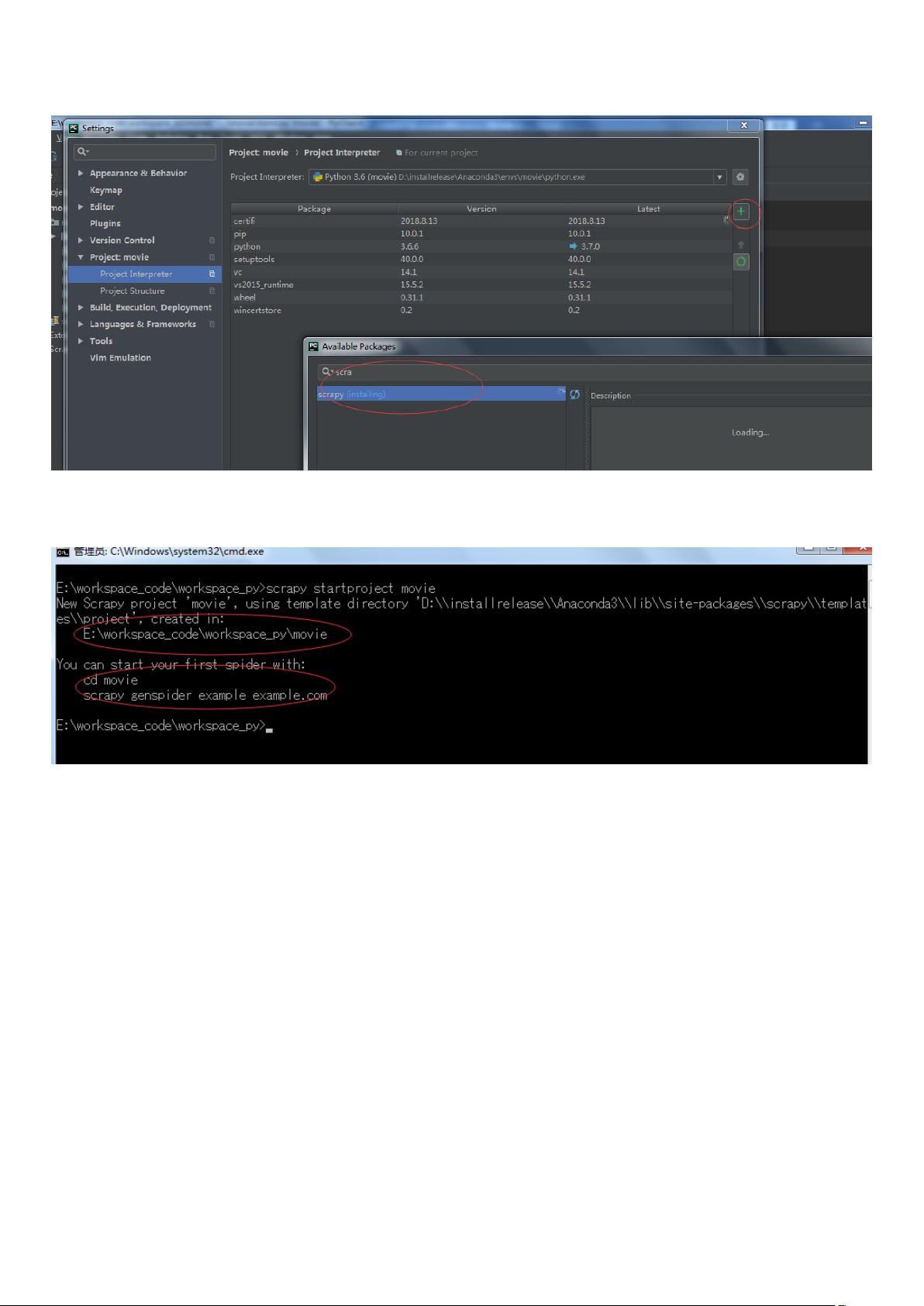
5. 创建项目
E:\workspace_code\workspace_py>scrapy startproject movie
New Scrapy project 'movie', using template directory 'D:\\installrelease\\Anaconda3\\lib\\site-packages\\scrapy\\templat
es\\project', created in:
E:\workspace_code\workspace_py\movie
6. 创建爬虫
You can start your first spider with:
cd movie
genspider 生成爬虫命令
example 爬虫的名字
example.com 爬取的网站
scrapy genspider example example.com
剩余10页未读,继续阅读
2021-06-19 上传
2018-12-04 上传
2024-02-04 上传
2020-12-10 上传
2021-01-20 上传
2022-08-05 上传
2021-01-27 上传
2022-08-05 上传

whph
- 粉丝: 27
- 资源: 305
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
